winstonlamoine retweetledi

winstonlamoine
2.3K posts








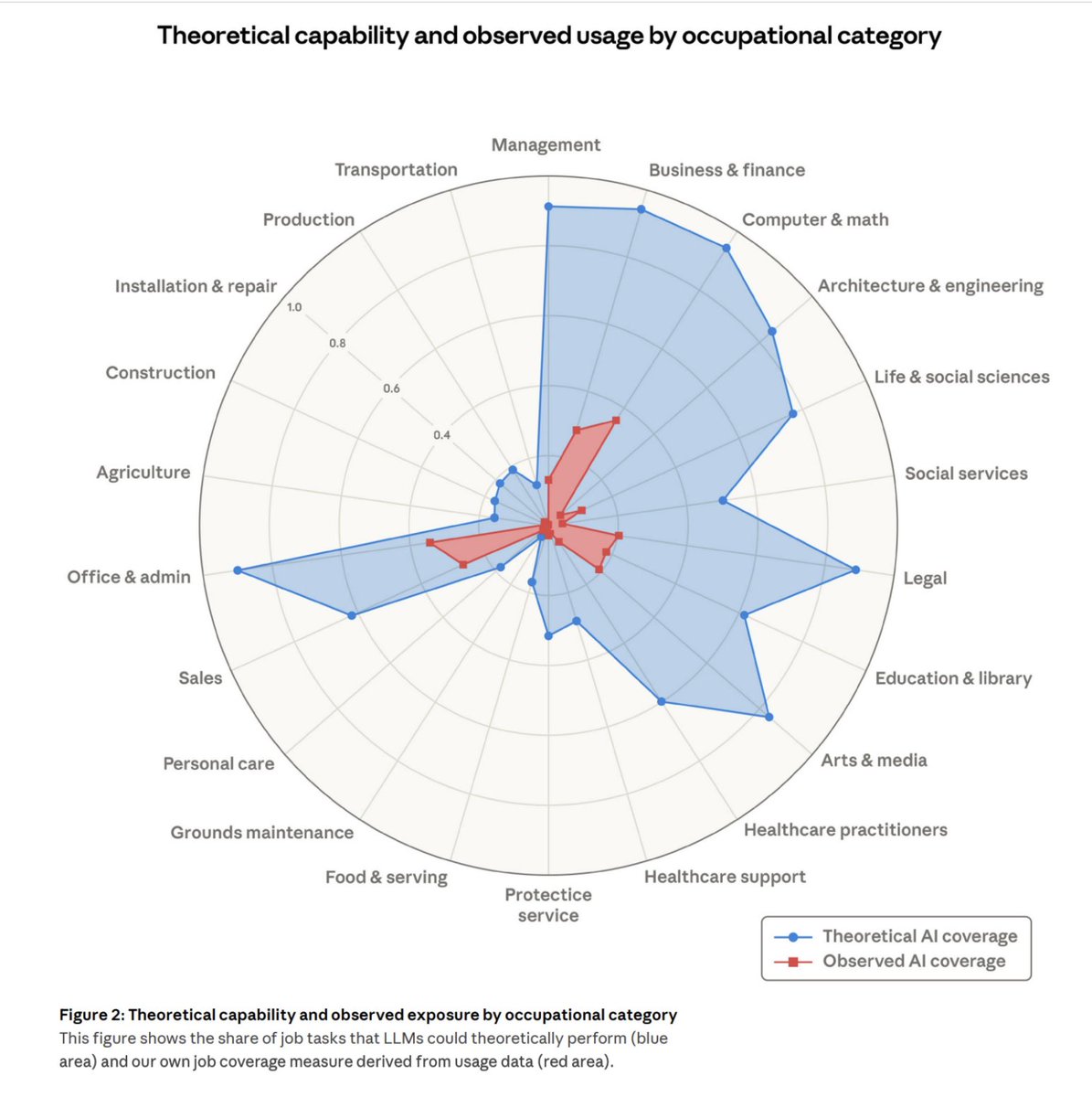
🚨Another update to our Generative AI US adoption time series results from our paper “The Labor Market Effects of Generative Artificial Intelligence”: we find LLM adoption at work in the US fell over the past quarter (while still up substantially from a couple years ago).