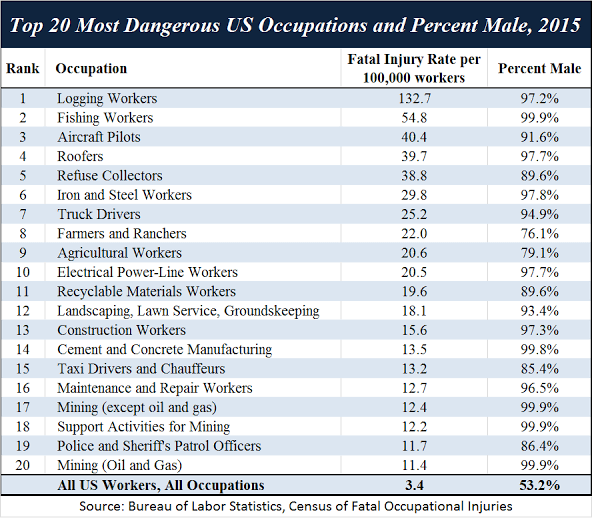
Gameisforever retweetledi

什么场景用什么AI,大概梳理了一下我的组合!
我也想看看你的,或者会有一些更好的推荐?
日常高频:ChatGPT 5.5、Claude、豆包
桌面程序:Codex、Claude
轻代码:Codex、Claude Code
本地模型:暂无
文案:Claude
视频:Seedance2.0、Kling3、Veo
图片:GPT image-2、Genmini(Nano Banana Pro/2)
图片编辑:GPT image-2
视频解析:Gemini 3.1
TTS:Gemini 3.1 Flash TTS
工作流:Coze
Agent:OpenClaw
付费情况:
年度订阅(之前因为bananapro):Gemini pro
每月续费(暂时离不开的刚需):GPT Plus、Claude Pro
按需付费:Coze、Claude Max、Seedance2.0(第三方)

中文