
Florian Brand
36K posts

Florian Brand
@xeophon
evals @PrimeIntellect | open models @interconnectsai
Katılım Temmuz 2015
762 Takip Edilen14.9K Takipçiler

@xeophon Personal belief is that they’re practical
Not a panacea, not a wincon ; didn’t like the hype around personally
But definitely thinking they’re always nice to have and pretty good to provide to a model when availabl, useful and well defined
English

New Blog Post: Do Automated Evals Work?
There has been a rise of tools that look through your traces with AI and identifies issues. We tested these tools with real production data to see how good they are.
Where they shine
- They often spot issues human miss
- Integrate into your workflow: viewing traces, creating LLM judges etc.
Where they fall short
- They miss problems that require domain expertise and taste
- Don't have great mechanisms to learn from human feedback
- You can get similar results from using your coding agent
So you should use them? Yes, BUT do so iteratively with you in the loop. We describe how in the post: parlance-labs.com/blog/posts/aut…
It's also a good idea to try using your coding agent with you in the loop, which we discuss in the post.
This was written with @doesdatmaksense , who led the research and collated the results.

English

linear attention 6:1 ratio, DSA for global attention, 70 layers, 1M context, 1.5T parameters, ~30T training tokens, use latentMoE (or a variant of it), kimi residual attention, no engram, natively multimodal (only text out tho)
(i have 0 information)

leo 🐾@synthwavedd
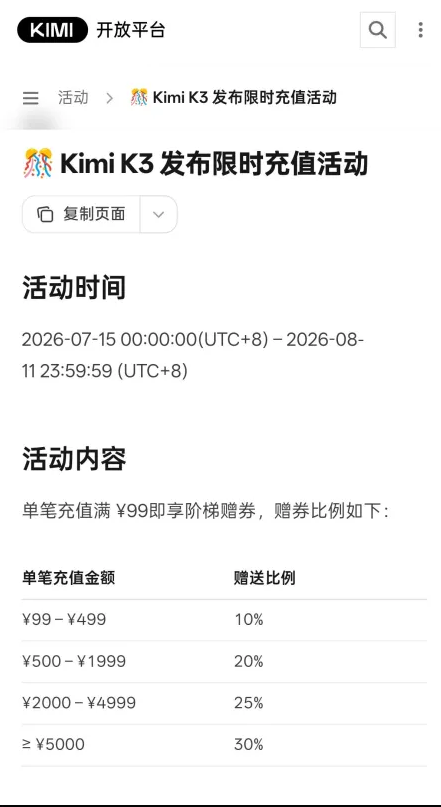
🚨 BREAKING: Kimi K3 is launching tomorrow with a discount on top-ups, according to a briefly live article on their docs site
English


Florian Brand retweetledi

@eternal_twil 100+ tools is not a problem of the protocol, people nowadays install 1000 skills and think its better. lazy loading is a solved problem and security issues are as well
English

@xeophon I mean restrained use yes, but people are often deranged, shoving in 100+ tools, bloating context; not gonna mention security issues
English

English

@xeophon @paradite_ @PrimeIntellect @willccbb just pivot these attempts into a verifier-implementation-env and add it into the mix.
English

@ben_burtenshaw @PrimeIntellect you should be able to zero-shot this thing and tailor it to your specific needs / setup in a few hours with claude code?
English
@ben_burtenshaw @paradite_ @PrimeIntellect @willccbb And: Can you one-shot such a library? Yes, we’ve done so. Thrice. By three people. It worked but it kinda sucked and had some rough edges. So that’s why we took two steps back and made the leash shorter. Result: code is better + more confidence in letting others build on it
Florian Brand@xeophon
@willccbb @usr_bin_roygbiv Yeah I should do a write up over this journey TL;DR is: Yes, you can one shot this with good specs but it’ll suck
English
@ben_burtenshaw @paradite_ @PrimeIntellect @willccbb Rather work together with you and add the missing pieces 🤗🤝🦋
English
@GergelyOrosz That’s why we wrote the docs for our library refactor by hand 🫡 removed like 60% of useless stuff, especially since concepts are meant to be read by humans while agents fill in the code gaps
English

The amount of AI writing on OpenAI's docs makes me sick.
Filler sentences for nothing. Mannerisms and phrases humans would not write. Has a human even read this?
And all of this will change how other docs are written, and how we all talk - for the worse IMO.
🤮

English
@willccbb @usr_bin_roygbiv Yeah I should do a write up over this journey
TL;DR is: Yes, you can one shot this with good specs but it’ll suck
English

@usr_bin_roygbiv thinking about how florian vibecoded a version with gpt-5.5 over a couple weeks and then i was like "nah we can do better" and i vibecoded a version over a couple weeks with gpt-5.5 and then mika was like "nah we can do better" and then basically wrote the final v1 by hand
English


Florian Brand retweetledi

New addition as of this morning: Verifiers v1 now supports GEPA, allowing you to get very fast and robust performance gains before you do any RL.
Prime Intellect@PrimeIntellect
Today, we are releasing verifiers v1 — an overhaul of our environment stack for the modern era of agentic RL and evals. We decompose environments into a taskset, a harness, and a runtime. Run complex agentic tasks like coding and computer use at scale, in any harness.
English

wait twitter is good again and I’m not seeing shit about katseye anymore?
English
we’ve tested prl both with professors and also in production runs, so come grab the update
samsja@samsja19
We are also releasing prime-rl 0.7.0 which has full support for verifiers v1 and bring your own harness for training. We have been battle tested it in prof for weeks now, on the menu: * Verifiers v1 integration * Full Algorithm layers (GRPO, OPD, OPSD, SFT, ECHO * Bunch of performance improvement and saner default
English
when you are 21 someone will tell you not to move to San Francisco after college. it’s very important that you do not listen to them



English

@xeophon That’s a good point. Looks like twitter beers are back on the menu. You want some?
English
I used to immediately spend all my X money on drinks with friends (because I don’t make much and that’s fun)
But now they offer 6% apy so I have to be financially responsible with my “dumb jokes” money
English