Sabitlenmiş Tweet

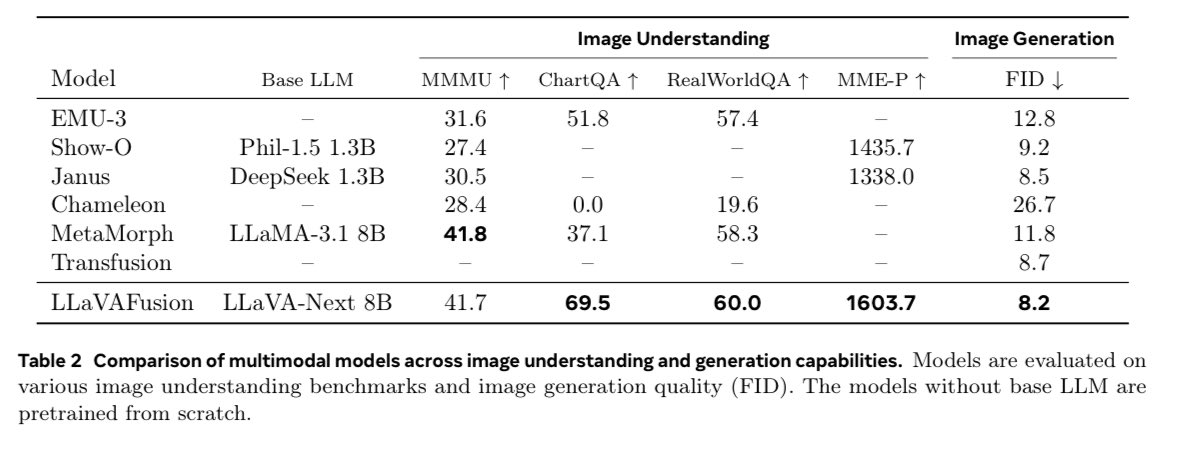
We find training unified multimodal understanding and generation models is so easy, you do not need to tune MLLMs at all.
MLLM's knowledge/reasoning/in-context learning can be transferred from multimodal understanding (text output) to generation (pixel output) even it is FROZEN!

English