Sabitlenmiş Tweet

🚀 Can we cast reward modeling as a reasoning task?
📖 Introducing our new paper:
RM-R1: Reward Modeling as Reasoning
📑 Paper: arxiv.org/pdf/2505.02387
💻 Code: github.com/RM-R1-UIUC/RM-…
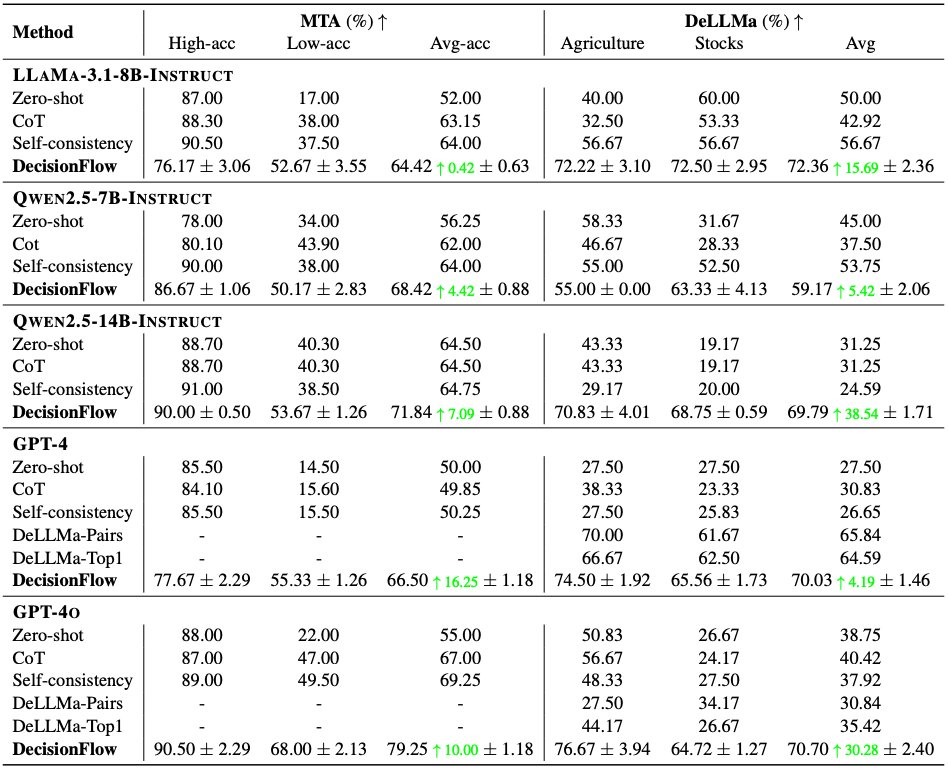
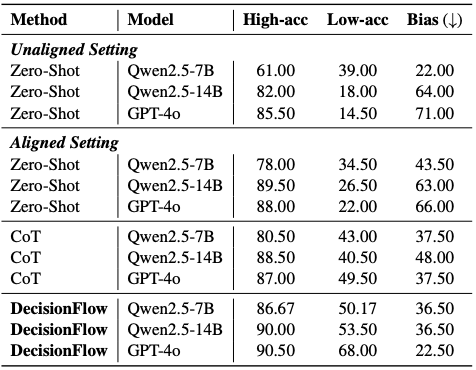
Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM's interpretability and performance. RM-R1 achieves state-of-the-art or near state-of-the-art performance of generative RMs on RewardBench, RM-Bench and RMB.
🧵👇


English