xophe retweetledi

Public github repo is live with plan: github.com/namanbarkiya/i…
English
xophe
3K posts

@xopheb
SRE #Agregio Solution ! My tweets are my own. @[email protected] / https://t.co/eRHCbvkCXR



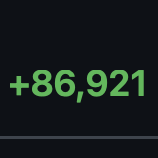
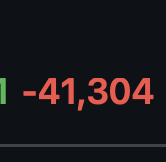

FYI, Dagger is about to move off Buildkit, to a cleanroom reimplementation. This matters beyond Dagger. Buildkit is load-bearing infrastructure for a huge chunk of CI/CD. It has fundamental limitations that are getting harder to work around, but it's too entrenched and complex to just rip out. We've been chipping away at it for two years, replacing it piece by piece, and it's finally paying off. And we'll make sure the offramp is available to others too... More once it ships. DM me (here or on discord) if you're curious. #project-theseus-removing-buildkit" target="_blank" rel="nofollow noopener">dagger.io/changelog/#pro…



🚨 CRITICAL: Active supply chain attack on axios -- one of npm's most depended-on packages. The latest axios@1.14.1 now pulls in plain-crypto-js@4.2.1, a package that did not exist before today. This is a live compromise. This is textbook supply chain installer malware. axios has 100M+ weekly downloads. Every npm install pulling the latest version is potentially compromised right now. Socket AI analysis confirms this is malware. plain-crypto-js is an obfuscated dropper/loader that: • Deobfuscates embedded payloads and operational strings at runtime • Dynamically loads fs, os, and execSync to evade static analysis • Executes decoded shell commands • Stages and copies payload files into OS temp and Windows ProgramData directories • Deletes and renames artifacts post-execution to destroy forensic evidence If you use axios, pin your version immediately and audit your lockfiles. Do not upgrade.





Les données disponibles sur data.gouv.fr sont désormais interrogeables via un serveur MCP dédié en experimentation, vos retours sont bienvenus ! 💻 Le code est ouvert et accessible sur GitHub : github.com/datagouv/datag… Pour en savoir plus : data.gouv.fr/posts/experime…







Researchers built a new RAG approach that: - does not need a vector DB. - does not embed data. - involves no chunking. - performs no similarity search. And it hit 98.7% accuracy on a financial benchmark (SOTA). Here's the core problem with RAG that this new approach solves: Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity. But similarity ≠ relevance. When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar. But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query. Traditional RAG would likely never find it. PageIndex (open-source) solves this. Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents. Then it uses reasoning to traverse that tree. For instance, the model doesn't ask: "What text looks similar to this query?" Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?" That's a fundamentally different approach with: - No arbitrary chunking that breaks context. - No vector DB infrastructure to maintain. - Traceable retrieval to see exactly why it chose a specific section. - The ability to see in-document references ("see Table 5.3") the way a human would. But here's the deeper issue that it solves. Vector search treats every query as independent. But documents have structure and logic, like sections that reference other sections and context that builds across pages. PageIndex respects that structure instead of flattening it into embeddings. Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications. But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines. For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis. Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself. I have shared the GitHub repo in the replies!


