📊We further combine DARS with breadth scaling (DARS-Breadth). We replace PPO’s mini-batch updates with full-batch gradient descent across multiple PPO epochs.
The training dynamics show the complementary improvement of DARS-Breadth for both Pass@1 & Pass@K.
🧵4/5
💥 Introducing "Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration"
We proposed DARS to solve the systematic bias in GRPO: the cumulative advantage down-weighting hard samples that are crucial for reasoning boundaries.
arxiv.org/abs/2508.13755
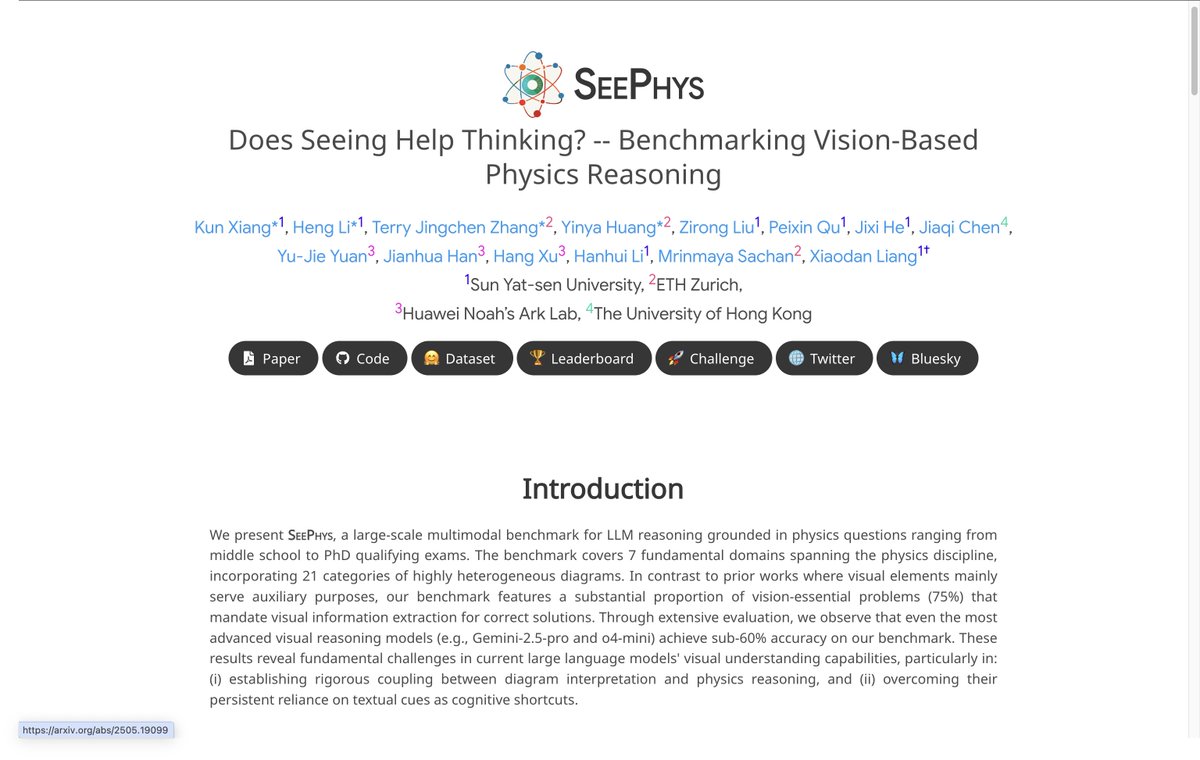
🤖⚛️Can AI truly see Physics? Test your model with the newly released SeePhys Benchmark! 🚀
🖼️Covering 2,000 vision-text multimodal physics problems spanning from middle school to doctoral qualification exams, the SeePhys benchmark systematically evaluates LLMs/MLLMs on tasks integrating complex scientific diagrams with theoretical derivations.
📊Experiments reveal that even SOTA models like Gemini-2.5-Pro and o4-mini achieve accuracy rates below 55%, with over 30% error rates on simple middle-school-level problems, highlighting significant challenges in multimodal reasoning.
Key Features Highlighted:
🔎Vision-Text Integration: Explicitly emphasizes multimodal reasoning failures in interpreting diagrams (e.g., circuit schematics, coordinate systems).
🔎Cross-Domain Complexity: Tests models across 7 physics domains and 8 educational tiers, exposing weaknesses in both visual grounding and logical derivation.
🔎Open-Source Design: Fully reproducible framework for diagnosing AI's "visual illiteracy" in scientific contexts.
🎖️Project led by: @kaleb962, @HengLee29423, Terry Jingchen Zhang, @YinyaHuang
💼Joint work with an exceptional team: Zirong Liu, Peixin Qu, Jixi He, Jiaqi Chen, Yu-Jie Yuan, Jianhua Han, Hang Xu, Hanhui Li, @mrinmayasachan, Xiaodan Liang
🏁The benchmark is now open for evaluation at the ICML 2025 AI for MATH Workshop. Academic and industrial teams are invited to test their models and advance multimodal physics!
⚛️Project Page: seephys.github.io
🤗Data: huggingface.co/datasets/SeePh…
📜Paper: arxiv.org/abs/2505.19099
🏆Challenge Submission: codabench.org/competitions/7…
➡️Competition Guidelines: sites.google.com/view/ai4mathwo…
Is your model faithfully translating math into formal languages like Lean?
⚖ Introducing "FormalAlign"! #ICLR2025
⁉️To address the lack of scalable evaluation in autoformalization, we propose the FIRST method to evaluate semantic alignment between informal and formal languages.
Results:
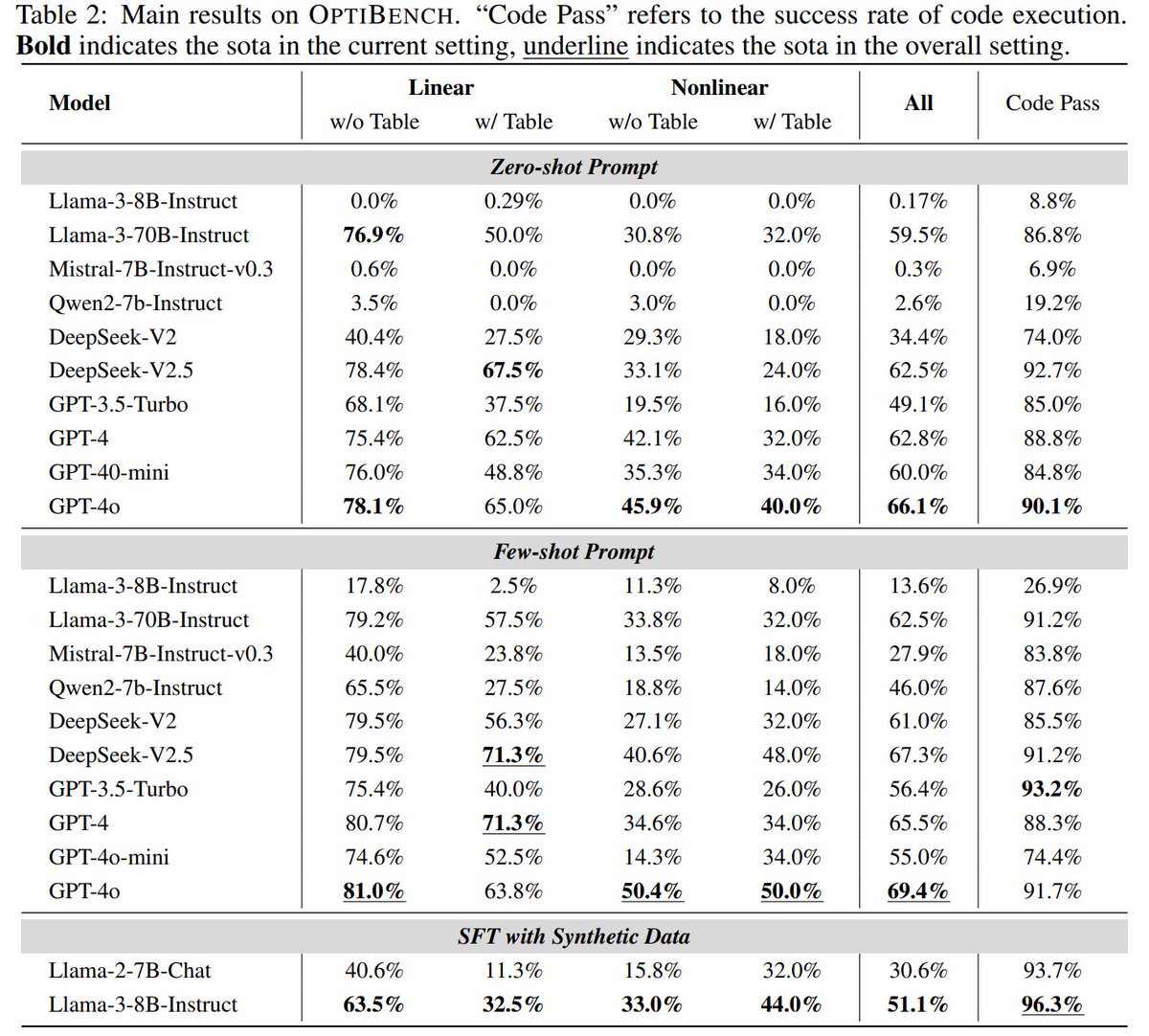
📊 We conducted substantial experiments and evaluations. As a benchmark that simultaneously tests both mathematical and coding abilities, OptiBench poses significant challenges to advanced LLMs.
📷The SFT results demonstrate the superiority of our synthetic data.
🚀 Excited to share our research at ICLR 2025!
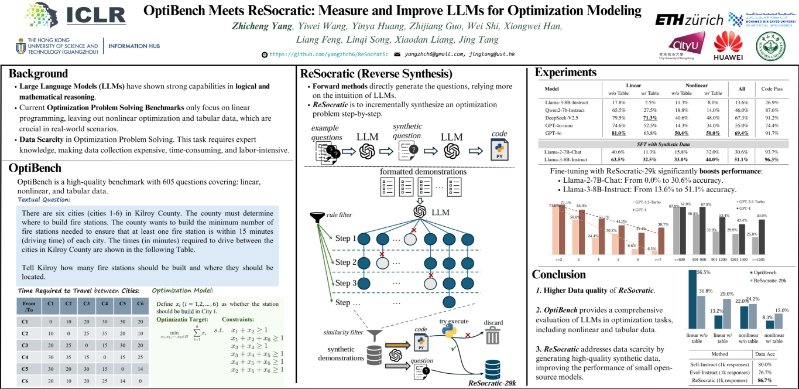
📘 We introduce OptiBench, a comprehensive benchmark for evaluating LLMs in optimization tasks, and ReSocratic, a novel reverse data synthesis method to enhance model performance.
🔗iclr.cc/virtual/2025/p…#ICLR2025#LLMs
The main idea of ReSocratic is to incrementally synthesize a problem with step-by-step generation via the Socratic method in a reverse manner. However, former methods synthesize the question without intermediate reasoning step, which led to data quality defects.
Benchmark:
OptiBench is an end-to-end benchmark, that takes natural language as input and numerical values of variables and objective as output. It covers a substantial number of challenging optimization problems with a wider range of problems (linear, non-linear, and table).
💥 Introducing "AutoPSV: Automated Process Supervised Verifier" - accepted at #NeurIPS2024!
AutoPSV automatically annotates reasoning steps via confidence tracking, making it efficient and effective even without ground-truth answers.
🔗 arxiv.org/abs/2405.16802
🧵1/5
The paper 📚 "Speak Like a Native: Prompting Large Language Models in a Native Style" explores the influence of the text style of context examples on the performance of Large Language Models (LLMs). The study introduces a new approach, named AlignCoT, which aims to enhance the reasoning capabilities of LLMs by aligning context examples with the native style of the LLMs.
The term "native" refers to the inherent characteristic style of LLMs, which can be probed by original zero-shot scenarios. The AlignCoT approach is orthogonal to other prompt engineering methods, making it easy to combine with state-of-the-art techniques to further improve LLM performance.
Experiments conducted demonstrate that AlignCoT significantly improves performance compared to manually crafted context examples. For instance, with GPT-3.5-turbo, a +2.5% improvement was observed on GSM8K. Furthermore, AlignCoT consistently enhances performance when combined with other cutting-edge prompt engineering methods.
MORE DETAILS AT: arxiv.org/pdf/2311.13538…