Sabitlenmiş Tweet

We launched SWE Atlas at Coding Agents Conference 2026, held at the Computer History Museum
After the success of SWE-Bench Pro, I kept asking myself: how do we encourage the industry to build towards the rest of the coding ecosystem?
SWE-Bench Pro measures whether AI can resolve GitHub issues, but software engineering is much more than that. What about understanding a codebase you've never seen before? Writing tests that actually catch bugs? Refactoring code without breaking things?
These are the skills that take engineers years to develop. And we haven't really had a way to measure them.
So we built one.
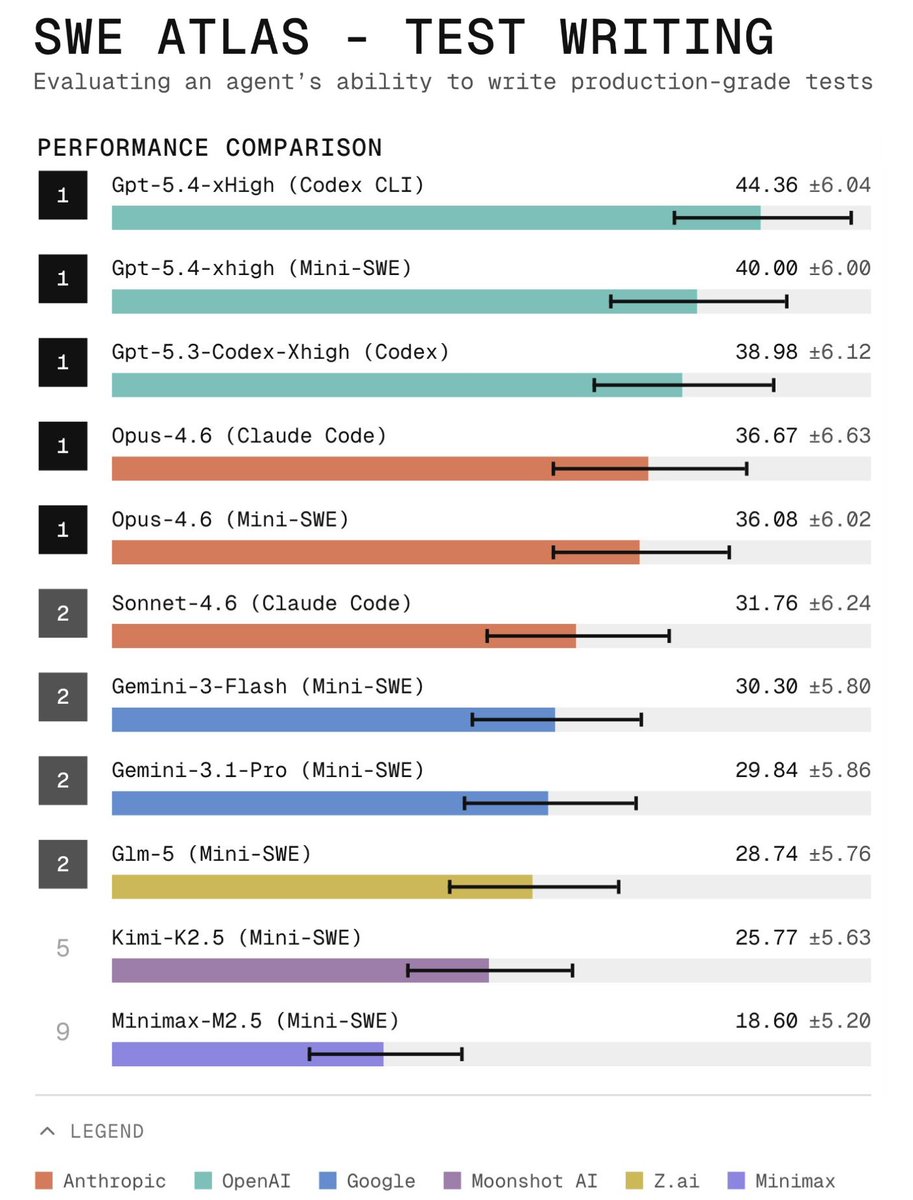
Today, we released SWE Atlas: a benchmark to assess how agents understand, validate, and improve software systems inside real repositories. It contains 3 types of tasks:
• Codebase QnA: deep code comprehension and reasoning (live now)
• Test Writing: writing meaningful tests that exercise real functionality (coming soon)
• Refactoring: restructuring code while preserving behavior (coming soon)
The codebase QnA focuses on comprehension: 124 tasks across real production repos. No code changes allowed. Just exploration, execution, and understanding.
As of today, the top model scores around low 30%. There's a lot of headroom.
I'm excited to see what kind of splash we can make with SWE Atlas. We hope this serves as a stepping stone for the community to build the next era of coding agents.
SWE Atlas Leaderboard: scale.com/leaderboard/sw…
Full Dataset: huggingface.co/datasets/Scale…


English