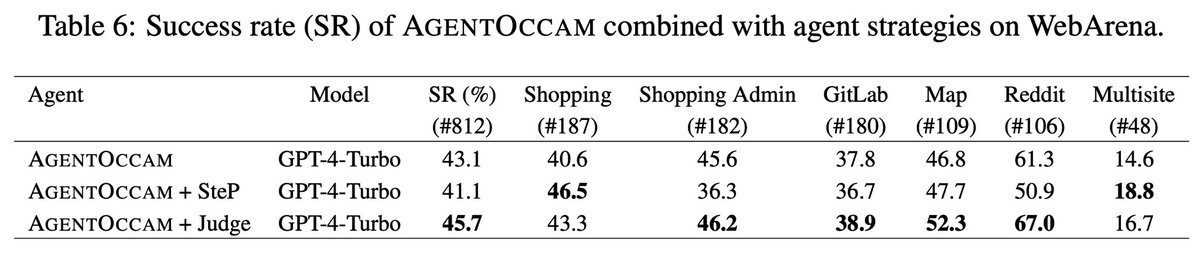
👾 Introducing AgentOccam: Automating Web Tasks with LLMs! 🌐 AgentOccam showcases the impressive power of Large Language Models (LLMs) on web tasks, without any in-context examples, new agent roles, online feedback, or search strategies. 🏄🏄🏄 🧙 Link: arxiv.org/abs/2410.13825 🧐 By refining the observation and action spaces, AgentOccam achieves a groundbreaking zero-shot performance, outperforming previous methods on the WebArena benchmark. This simple yet effective approach underlines the importance of aligning these spaces closely with LLM capabilities for enhanced efficiency. 📈 ✨ Highlights: - AgentOccam leads with a 29.4% improvement over state-of-the-art methods SteP, and a 161% boost in success rate compared to the vanilla agent. 🤖 - Achievements made possible without complicating the process with additional examples or strategies. 🚫 - All our replication work, prompts, and evaluator error rectifications are transparently shared in the appendix. 📚 🌟 Special thanks to my super brilliant and considerate mentor Yao and Rasool, our supportive manager Huzefa, and the invaluable suggestions and contributions from Sapana, Pratik, and George. Your guidance and support have been pivotal in this journey! #AgentOccam #LLM #WebAutomation #AI