y
17 posts


y
@yasha1971
Built ACEAPEX (in lzbench) + GLYPH. Compression & exact retrieval. Not a programmer — just obsessed with the problem. https://t.co/2KSMZa6i4R


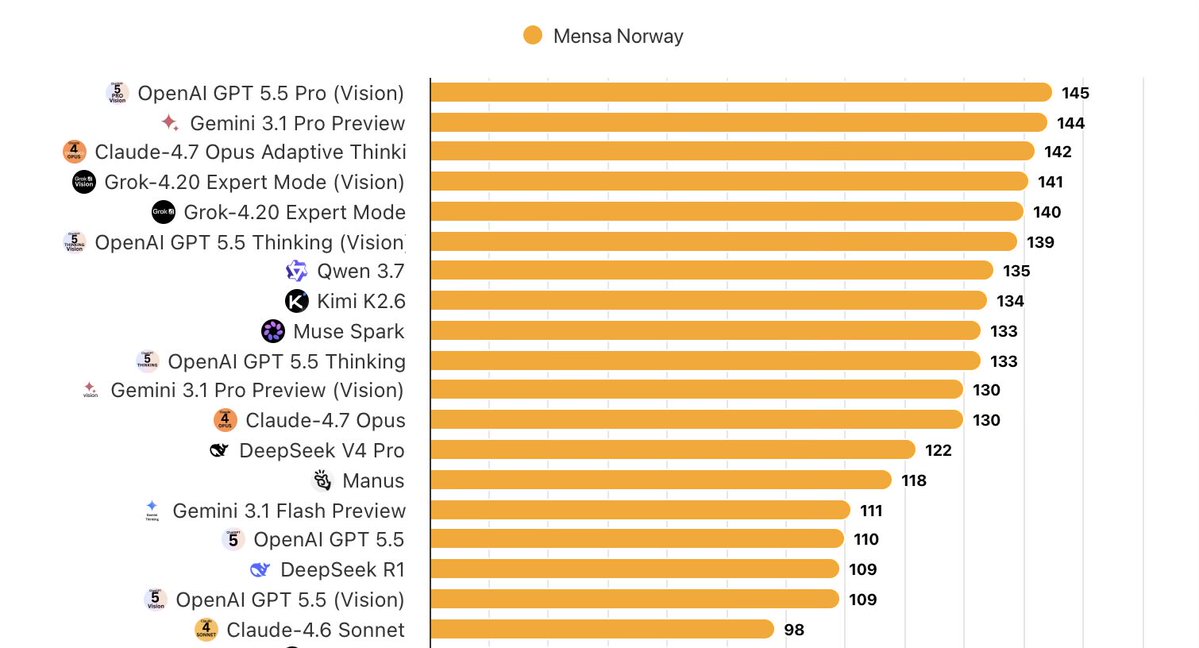
karpathy's CLAUDE.md hit #1 on github trending. 220,000 stars. most devs still haven't read it. it's 65 lines. it took AI coding accuracy from 65% to 94%. the 4 rules inside: → think before coding state your assumptions. ask when unsure. never guess. → simplicity first write the minimum code that solves the problem. no abstractions nobody asked for. → surgical changes don't touch code unrelated to the request. every changed line must trace back to what was asked. → goal-driven execution turn vague instructions into verifiable success criteria before writing a single line. that's it. 65 lines. 4 rules. 94% accuracy. save this before everyone else does.



Your analytics job scans 4TB of data every hour. You scaled from 10 machines to 500 machines. But processing speed barely improved. CPU usage is low. Network usage is low. So where is the bottleneck? What has to change in the storage architecture before hundreds of nodes can actually process the dataset in parallel?


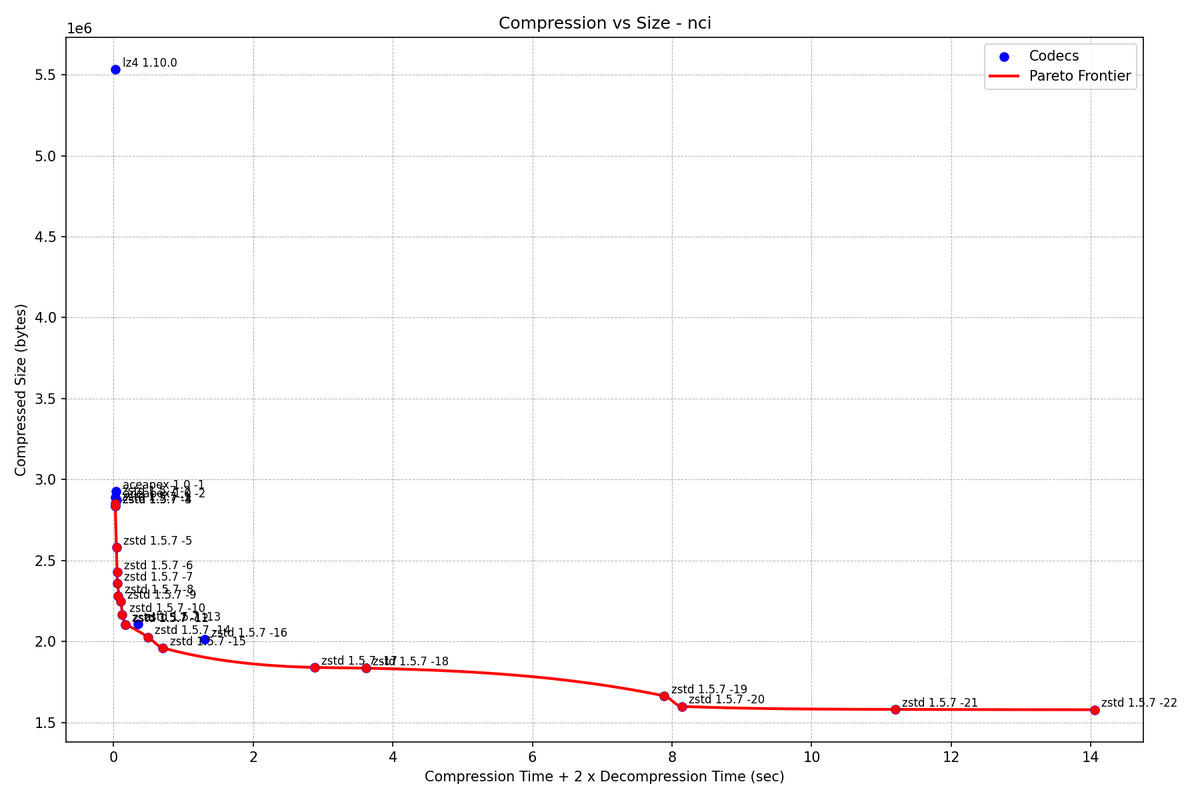


so we built psql_bm25s. exact BM25 retrieval. native Postgres access method. ~23x faster than pg_search on the standard benchmark. retrieval stops being a budget item. the harness stops rationing. the agent gets to look things up like it should have the whole time.


