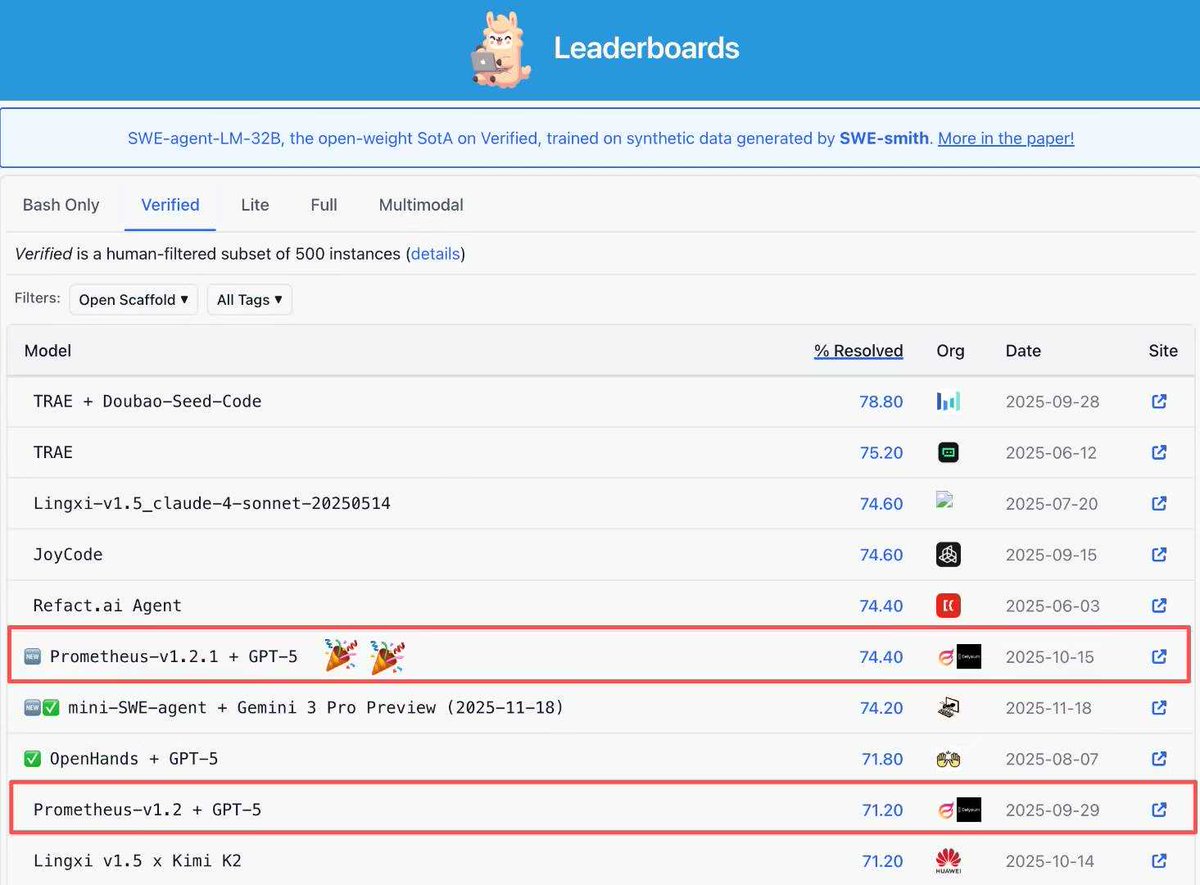
We just released ContextBench 🎉 A benchmark built to answer a question many repo-level evaluations still miss: Do coding agents truly retrieve and use the right context, or do they just get lucky?👀✨ 📊 Highlights 🧩 1,136 real-world issues across 66 repos and 8 languages 🧠 Expert verified gold contexts at file, block, and line levels 👣 Full trajectory tracking of what the agent actually reads and explores 📈 Metrics covering Recall, Precision, F1, Efficiency, and Usage Drop 🔍 Key Findings 1️⃣ Complex agentic scaffolds do not improve context retrieval quality 😅 In many cases, they introduce over-engineering, echoing "The Bitter Lesson" in AI research 2️⃣ Many SOTA LLMs favor high recall over precision 📉 They retrieve more context, but also much more noise 3️⃣ Retrieved does not mean utilized ❗ Agents often inspect the right code but fail to incorporate it into the final patch 4️⃣ Retrieval strategies that are more balanced tend to achieve stronger Pass@1 while keeping compute cost reasonable ⚖️✨ 🌐 Homepage 👉 contextbench.github.io 📄 Paper 👉 arxiv.org/abs/2602.05892 💻 Code 👉 github.com/EuniAI/Context… 🗂️ Dataset 👉 huggingface.co/datasets/Conte…