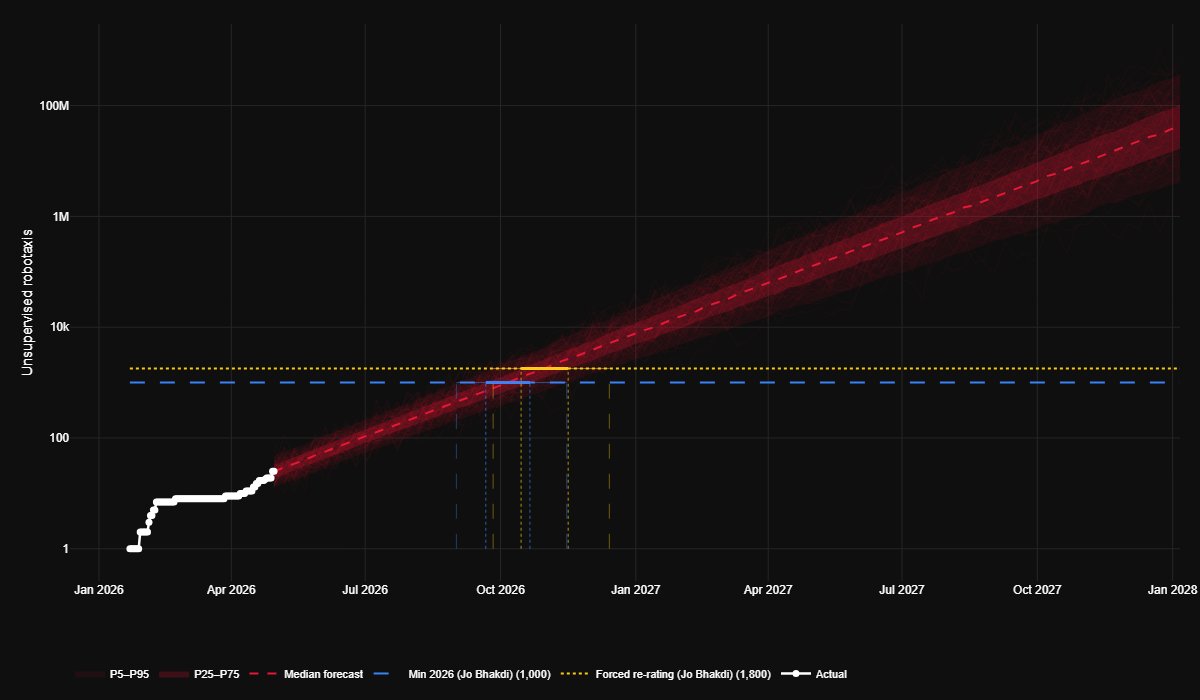
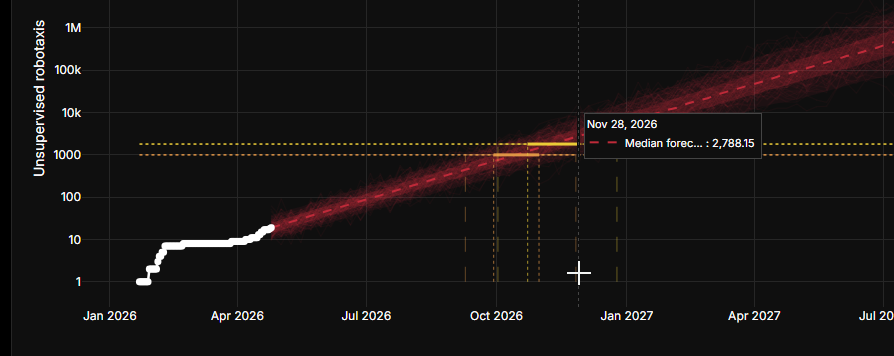
Yusuf Young@yusufyoung
I think privacy in AI agents is a dead end if you try to solve it technically.
I've been designing Aether's privacy model for weeks now, and the deeper I go, the clearer this gets. You can't classify information as "private" or "not private." It doesn't work.
Take a user's name. On a business card, it's fine. Linked to the fact that the user is in therapy, it's private. The name didn't change. The context did. And "the user is in therapy" isn't inherently private either. It's private because the user doesn't want others to know. Social judgment, embarrassment, vulnerability. That's a preference, not a property of the information.
Follow any piece of "private" information to its root and you arrive at the same place: someone's preference. A financial transaction: sharing it with the counterparty is expected. Sharing it with a stranger? Sometimes fine, sometimes catastrophic. Sometimes you'd actually want to share it, to signal status or further your interests. Same data, different answer depending on the person and the moment.
There is no universal rule that says "health information is private." In some cultures it isn't. Even within a culture, the same information in the same context may be private to one person and not to another. The only variable is what they prefer.
We initially had a requirement: "the agent must be able to distinguish what is private from what is not." That requirement was wrong. It assumes privacy is a derivable property of data. It isn't. No classification algorithm, no tagging system, no rule engine can determine what is private for a given user in a given context. Somewhere, someone's judgment is required: the user's (at the cost of autonomy) or the agent's (which the user must trust).
I've decided to go with autonomy and build trustability into Aether instead. The agent learns your preferences over time through feedback and alignment, the same way you'd build trust with a human assistant. This is different from NVIDIA's NemoCloud, for example, which takes the opposite route: require explicit approval for every share, every channel, every piece of information. It's safe. It's also not autonomous. I think the harder path is the right one.