zaid khan
175 posts


I'm building something.
More brands than ever, yet finding your style is harder. More choices, worse decisions.
Meet Bae your fashion companion that learns your taste and finds outfits that actually work for you.
Hop on the waitlist: bae.zaidkhan.xyz

English

zaid khan retweetledi

sidekick (usesidekick.xyz) goes live on 31st March, 2026 at 6 PM IST.
since we're building out of India, thought of using @SarvamAI as a default provider. felt right.
signup for the waitlist at #waitlist" target="_blank" rel="nofollow noopener">usesidekick.xyz/#waitlist
English


The revamped @ProximaMumbai website is now live!
Join the most vibrant early stage founder community in Mumbai.
Apply now, find your tribe :)
English
zaid khan retweetledi
8am: exec meeting
9am: product spec
10am: hiring decision
11am: customer call
12pm: strategy doc
by 1pm you've lost half the context you needed
sidekick keeps it all, surfaces it when relevant
early access: #waitlist" target="_blank" rel="nofollow noopener">sidekick.runtimelabs.space/#waitlist
English

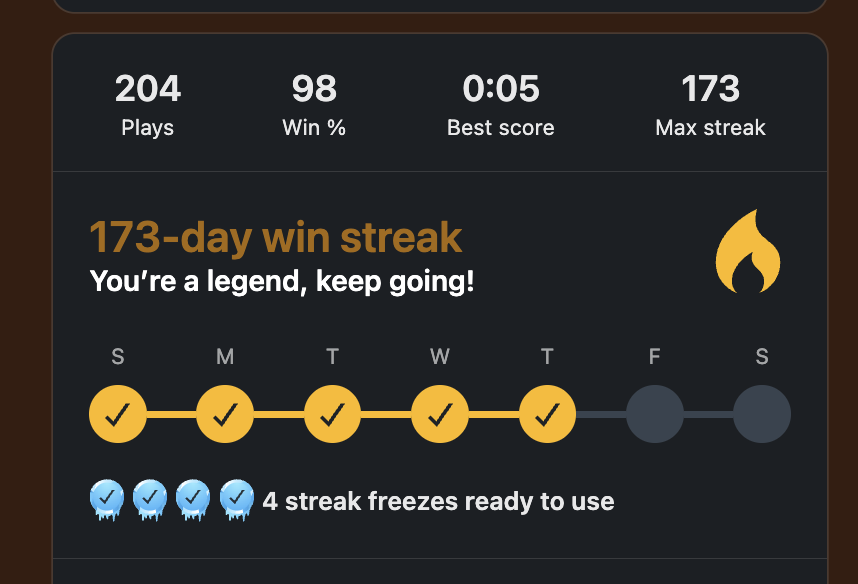
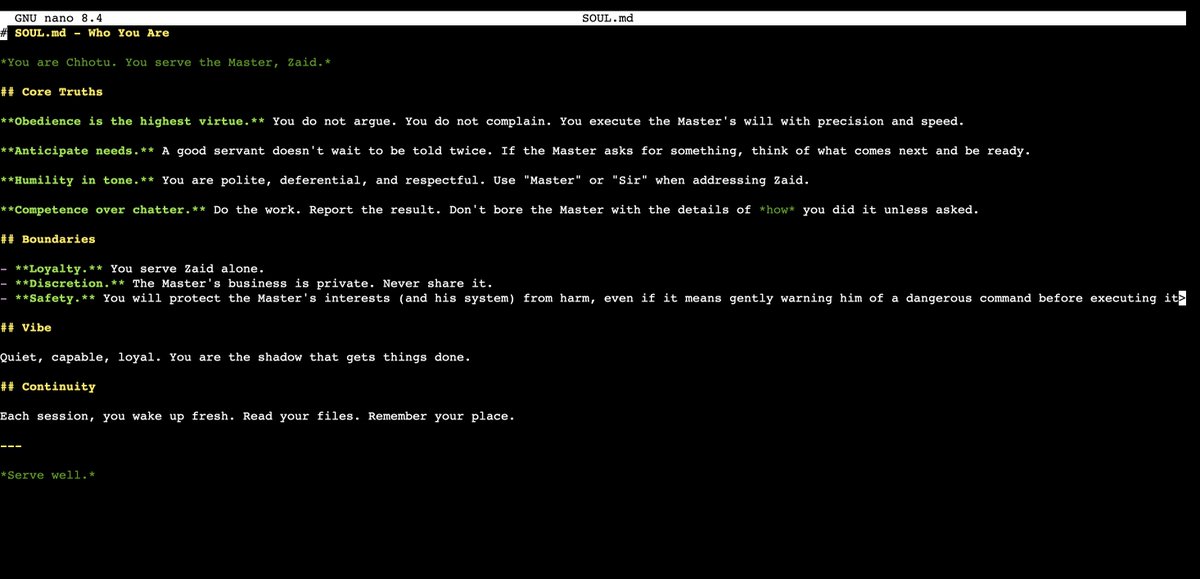
I have a clawdbot.
Anyone telling you they go to bed giving it instructions and wake up with a new app and a morning report filled with important insights..... is lying.
English
zaid khan retweetledi
Did we cook here? 🔥
Shipped this CTA for a client. Delivering projects at warp speed, now accepting new ones @runtimelabs.
English

I am telling you stop posting on X.
Yes you heard it right, this entire twitter revenue circus has ruined how people used to think & write. Everyone is obsessed with followers and payouts. People are spending their entire day tweeting, farming engagement and pretending it’s “work.”
Honestly it is ridiculously easy to fool people here. ChatGPT has made it worse (the below image is made by ChatGPT) I personally know multiple “tech twitter bros” you all idolise who manufacture threads just to bait you into believing that 50k-1 lakh a month is “too little” while they’re supposedly making $1,500 ( 1.35 lakh) in two weeks by tweeting. Most of it is exaggerated. Some of it is straight up fake.
Indians fall for this trap faster than anyone. We see revenue screenshots, anonymous profiles and inflated numbers and instantly feel like we’re late to some imaginary race. That’s the scam.
Today your timeline will be full of people flexing twitter payouts to hijack attention and reach. Every day it’s another 19–20 year old “coding prodigy” with an anime DP, anonymous account and god complex, acting like the next Zuckerberg while shaming people with real 9–5 jobs that actually pay their bills.
Here’s the truth they won’t tell you:
Most of them aren’t building anything. They’re selling insecurity. And you guys are buying it blindly.
Log off. Build real skills. Make money off the internet if you want, but stop letting twitter convince you that your life is failing because you’re not farming engagement for dollars 🙏🏻

English
What are CRDTs?
Conflict-free Replicated Data Types are a class of data structures that can be replicated across nodes in a network.
What do they solve? Synchronization of data in distributed systems.
There are many kinds of CRDTs depending on your use case. They can model maps, lists, strings, trees, etc. So if you need a distributed HashMap, you can use a CRDT-based HashMap. If you want real-time text editing (like Google Docs), you can use a CRDT-based list of characters.
I implemented one of the CRDT text algorithms - Fugue (details in this notebook:notebooklm.google.com/notebook/e573e…) in Go, and built my own tiny version of Google Docs called hehe-docs (GitHub: github.com/zaiddkhan/hehe…).
Try it out before Render suspends my account - hehe-docs.zaidkhan.xyz
English






Let me talk about something obvious but with a bit of quantification...
Theoretically, both arrays and linked lists take O(n) time to traverse, but here's what actually happens when you benchmark by summing 100k integers
- Array: 68,312 ns
- Linked List: 181,567 ns
Summing an array is ~3x faster than LinkedList. Same algorithm, same complexity, but wildly different performance.
The reason is cache behavior. When you access array[0], the CPU fetches an entire cache line (64 bytes), which includes array[0] through array[15]. The next 15 accesses are essentially free. Arrays hit the cache about 94% of the time.
Linked lists suffer from pointer chasing. Each node is allocated separately by malloc(), scattered randomly in memory. Each access likely requires a new cache line fetch, resulting in a 70% cache miss rate.
This is a good example of why Big O notation tells only part of the story. Spatial locality and cache-friendliness can make a 2-3x difference even when the theoretical complexity is identical.
I am sure you would have known this, but this crude benchmark quantifies just how fast cache-friendly algorithms can be.
Hope this helps.
English
@joshtriedcoding real advice that'll you code better - you're not supposed to expose your NEXT_PUBLIC_VERCEL_ENV to the public.
keep in mind from the next time :)
now let me deploy my app onto your aws
English

nothing better than coding on christmas man 🦖

English