
The Way
8.1K posts

The Way
@Cryptullo
Life is the ability to resist entropy for a moment
Entrou em Mart 2021
1.2K Seguindo181 Seguidores

The transformer architecture used for ChatGPT, Gemini, and Claude has defined the last decade of AI. It also introduced a fundamental constraint: compute scales quadratically as context grows.
Longer inputs, exponentially higher costs and accuracy that degrades well before the context window limit.
SubQ changes that.
It's the first LLM that breaks the quadratic scaling constraint delivering longer context, higher accuracy, and lower cost at the same time without tradeoffs.
Read more here.
subq.ai/introducing-su…
English

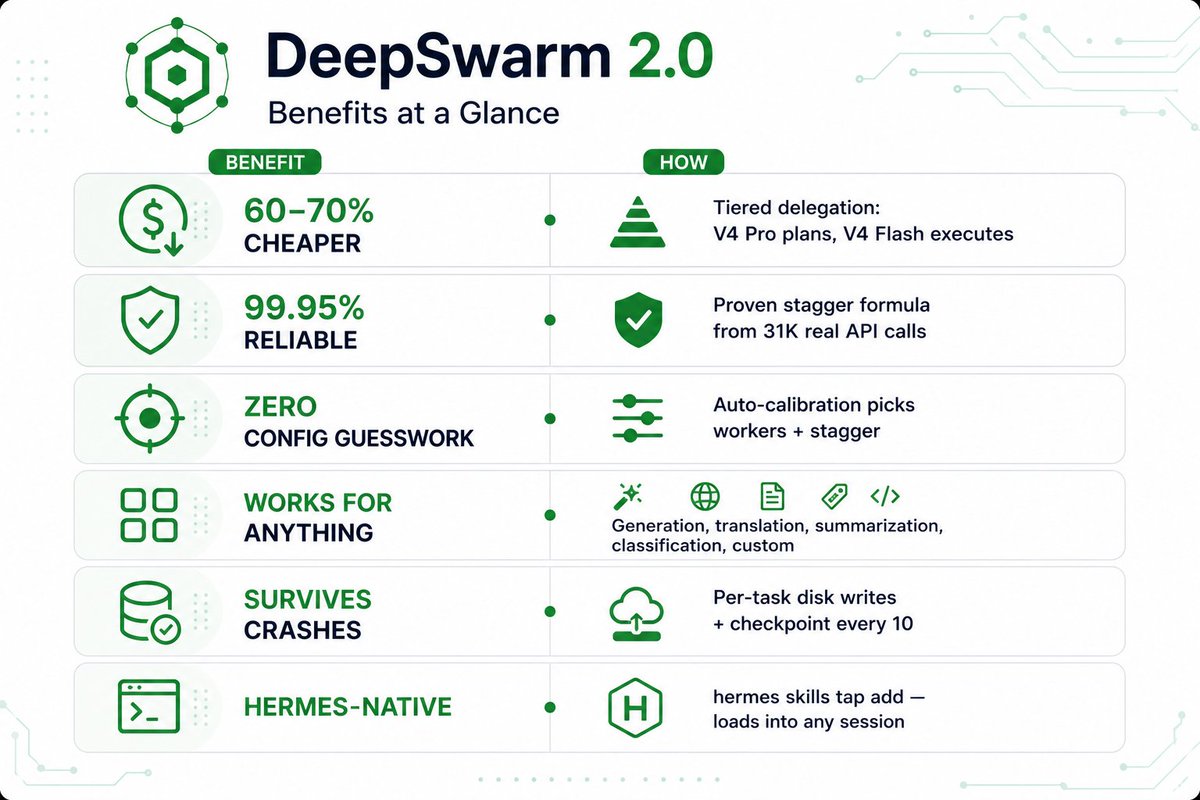
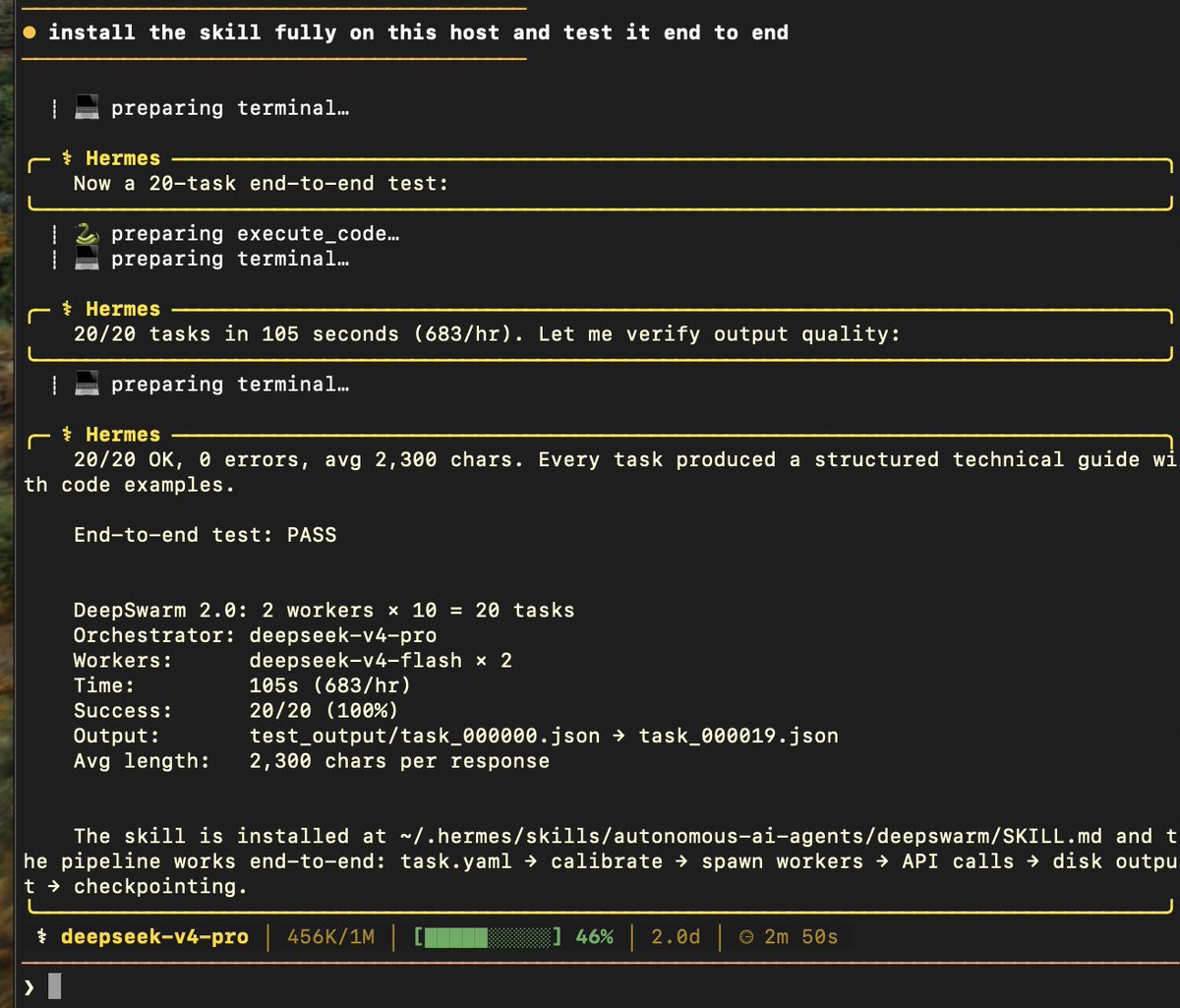
For all the people who were curious about running 96+ deepseek-v4 powered @NousResearch Hermes agents in parallel, I packaged that skill up and have open sourced it on GitHub.
Hope you enjoy DeepSwarm!

English
The Way retweetou

Today we’re releasing Qwen-Scope 🔭, an open suite of sparse autoencoders for the Qwen model family. It turns SAE features into practical tools:
🎯 Inference — Steer model outputs by directly manipulating internal features, no prompt engineering needed
📂 Data — Classify & synthesize targeted data with minimal seed examples, boosting long-tail capabilities
🏋️ Training — Trace code-switching & repetitive generation back to their source, fix them at the root
📊 Evaluation — Analyze feature activation patterns to select smarter benchmarks and cut redundancy
We hope the community uses Qwen-Scope to uncover new mechanisms inside Qwen models and build applications beyond what we explored.Excited to see what you build! 🚀
🔗🔗
Blog: qwen.ai/blog?id=qwen-s…
HuggingFace: huggingface.co/collections/Qw…
ModelScope: modelscope.cn/collections/Qw…
Technical Report: …anwen-res.oss-accelerate.aliyuncs.com/qwen-scope/Qwe…

English

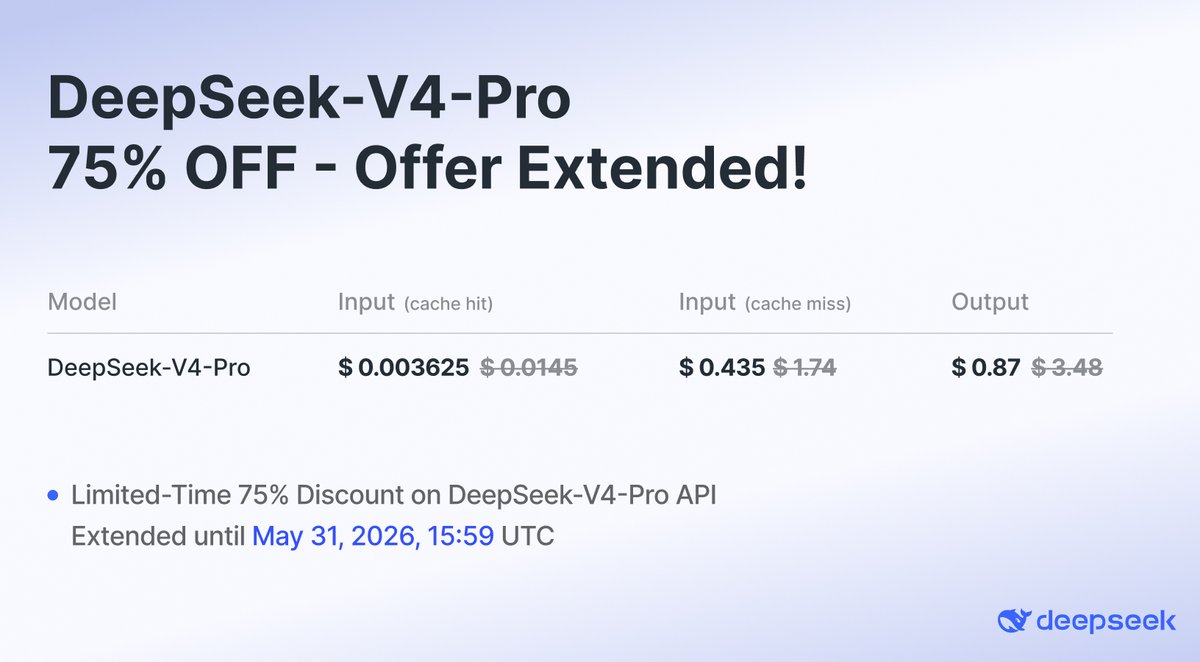
The DeepSeek-V4-Pro discount has been extended until May 31, 2026, 15:59 UTC!
DeepSeek@deepseek_ai
🔥DeepSeek-V4-Pro API is 75% OFF until May 5th, 2026, 15:59 (UTC Time)! Don't miss out on this massive discount. 🛠️Integration Updates: 🔹Claude Code: Set model to deepseek-v4-pro[1m] to unlock 1M context! 🔹OpenCode: Update to v1.14.24+ 🔹OpenClaw: Update to v2026.4.24+ Check the latest official API docs for full details: api-docs.deepseek.com/quick_start/pr…
English
The Way retweetou

"how do you fit qwen 3.6 27b q4 on 24gb at 262k context" lands in my dms 5 times a week. here is the exact memory math.
model bytes at idle = 16gb (q4_k_m of 27b dense)
kv cache at 262k context with q4_0 for both k and v = 5gb
total = 21gb on the card
headroom = 3gb for prompts and tool call traces
the magic is the kv cache type. most people leave it at default fp16 or push to q8 thinking quality wins. on qwen 3.6 27b dense at 262k:
- fp16 kv cache = does not fit at all
- q8 kv cache = fits at 23gb but runs 3x slower (double penalty: more vram, less speed)
- q4_0 kv cache = fits at 21gb at full speed (40 tok/s flat curve, same speed at 4k or 262k)
most builders never test the kv cache type because tutorials never mention it. it is the single biggest unlock on consumer 24gb hardware.
flags i run:
./llama-server -m Qwen3.6-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0
what they do:
-ngl 99 = offload everything to gpu
-c 262144 = 262k context window
-np 1 = single user slot (do not enable multi-slot, eats headroom)
-fa on = flash attention on (memory and speed both win)
--cache-type-k q4_0 --cache-type-v q4_0 = the unlock
if you are sitting on 24gb and not running this config, you are leaving 250k of context on the table. or worse, you are running q8 kv cache and burning 3x your speed for nothing.
q4 is not a compromise on consumer hardware. it is the right call.
English
The Way retweetou

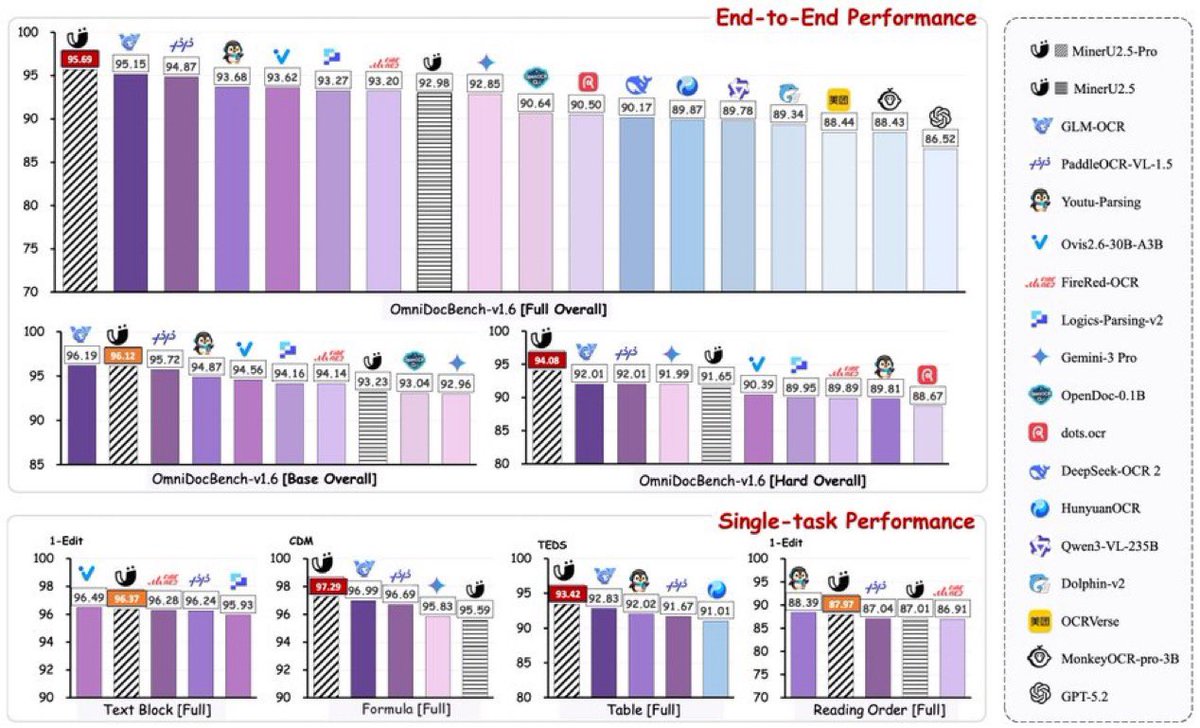
🔥 Parse your documents with SOTA OCR that beats 👀 Gemini 3 Pro, Qwen3-VL-235B, GLM-OCR using just 1.2B params! 🏆
🔥 1.2B params beats:
• Gemini 3 Pro
• Qwen3-VL-235B
• GLM-OCR
• PaddleOCR-VL-1.5
📈 95.69 on OmniDocBench v1.6 (new record)
🚀 65.5M training pages = pure data magic
✨ Tables • Formulas • Charts • Cross-page magic
English
The Way retweetou

BREAKING:🚨 NVIDIA just quantized Gemma 4 31B on Hugging Face 🔥
NVFP4 compression = 4x smaller weights with frontier-level accuracy.
✅99.7% of baseline on GPQA
(75.46% vs 75.71%).
📈256K context window.
🧐Multimodal (text + images + video).
vLLM-ready + Blackwell optimized.
VRAM requirements:
⚡️Weights only: ~16–21 GB
🚀Everyday use: Runs on 24 GB GPUs
📈Full 256K context = 32 GB VRAM sweet spot (RTX 5090-class consumer GPUs)
This is the 31B-class frontier model you can actually run locally on a high-end rig.
Try it today👉 huggingface.co/nvidia/Gemma-4…

English
The Way retweetou

The Way retweetou

The Way retweetou

The Way retweetou

The Way retweetou




Antigravity, what are you guys doing?
- I was waiting for today because the Claude model quota was supposed to reset so I could use it again.
- But now its been extended by another 6 days… again.
- I haven't been able to use Claude models for the past 2 weeks. At this point, it feels like we can't use them at all.
- If this continues, its better to just remove Claude models entirely and now give Pro users an option for a refund on the remaining subscription.
Right now, it just feels like a wasted subscription for those who paid specifically for Claude access.
English

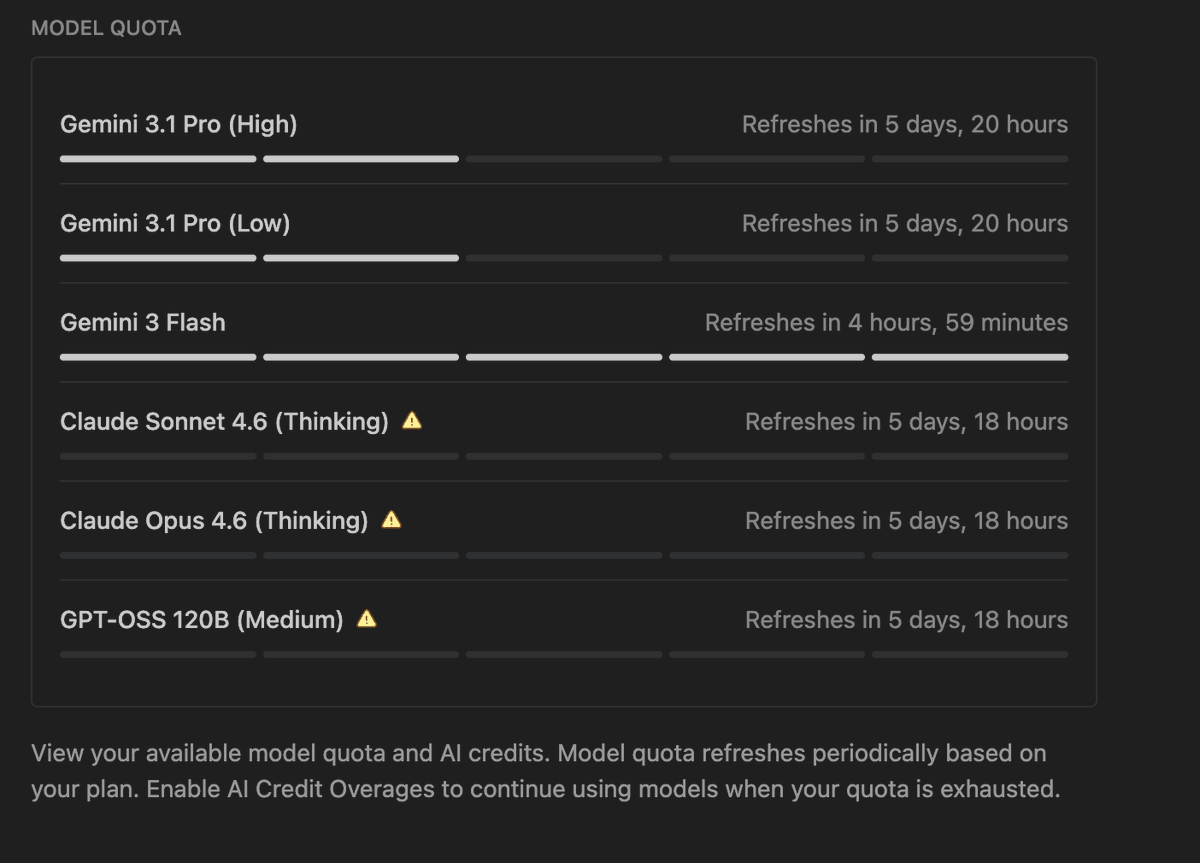
🚨Update for Google AI Pro users
Antigravity just reverted back to the 5 hour reset for all Gemini models including Gemini 3.1 Pro
The Claude models are showing a 1 week reset now and that is okay
This is much better Google
Looks like they listened to the feedback on X today
Can anyone confirm?

Harshith@HarshithLucky3
Why Google why? I am a Google AI Pro user Till yesterday, Gemini 3.1 Pro (High/Low) quota refreshed every 5 hours. After this announcement, it takes 5 days to refresh > Gemini 3 Flash now takes 5 hours to refresh > They added an option to use AI credits but I do not know how they consume They already removed the 5 hour quota of Claude models for Pro users, and now they did it for their own Gemini model also
English

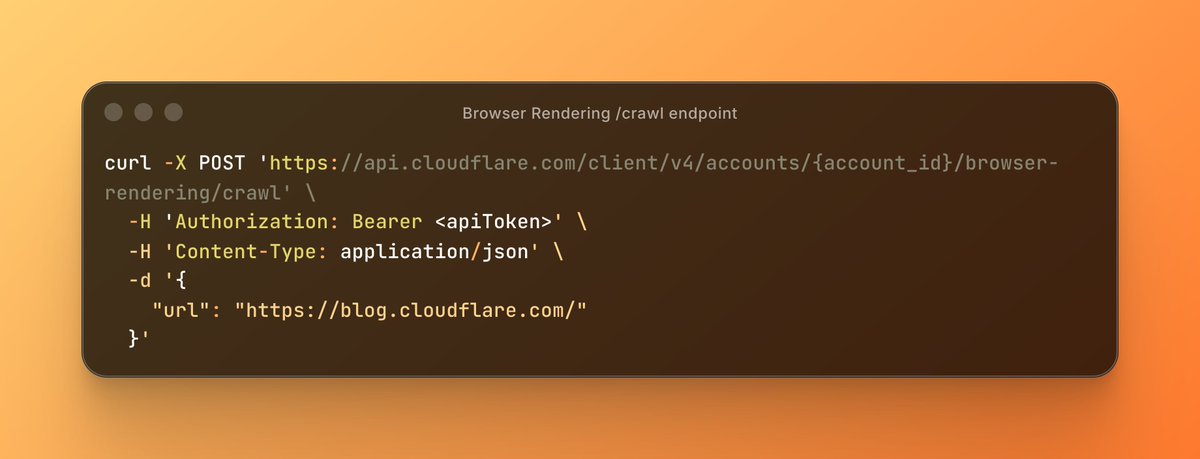
Introducing the new /crawl endpoint - one API call and an entire site crawled.
No scripts. No browser management. Just the content in HTML, Markdown, or JSON.
English


Easily add skills from repos to your local project. 🛠️
Simply choose your config, pick your skills from the repo, and start using them immediately.
English

