
Tweet fixado

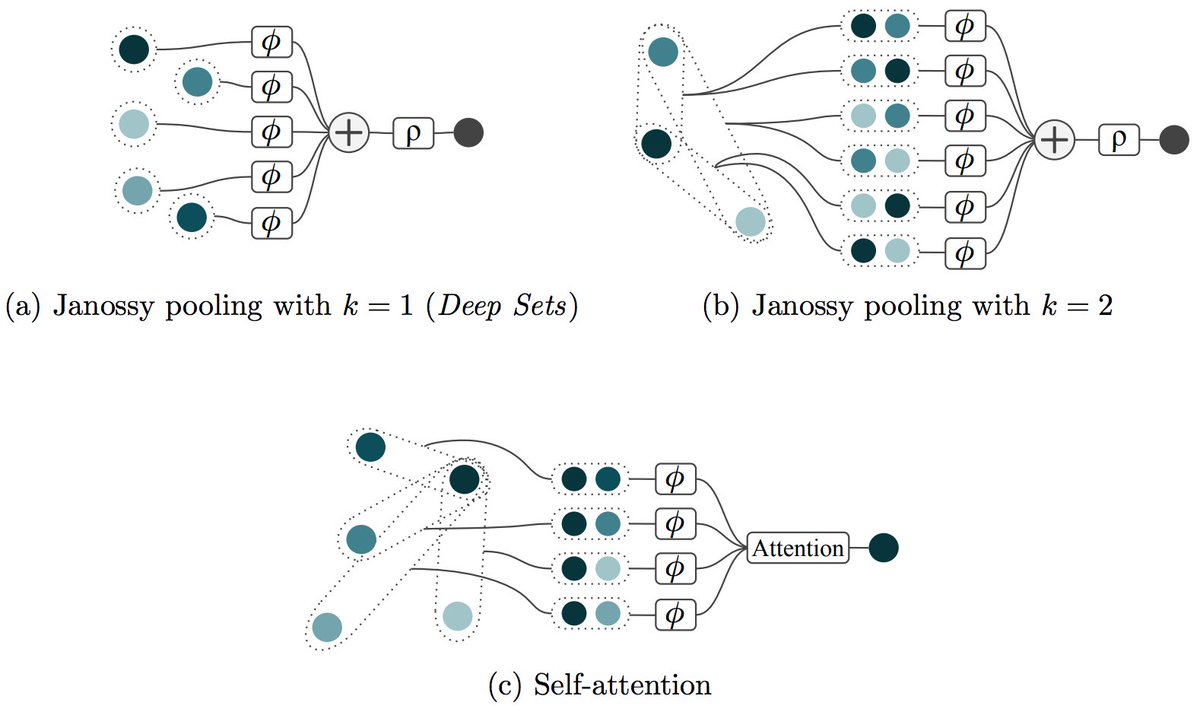
A year ago I asked: Is there more than Self-Attention and Deep Sets? - and got very insightful answers. 🙏 Now, Ed, Martin and I wrote up our own take on the various neural networks architectures for sets.
Have a look and tell us what you think! :)
➡️fabianfuchsml.github.io/learningonsets/ ☕️
Fabian Fuchs@FabianFuchsML
Both Max-Pooling (e.g. DeepSets) and Self-Attention are permutation invariant/equivariant neural network architectures for set-based problems. I am aware of a couple of variations for both of these. Are there additional, fundamentally different architectures for sets? 🤔
English

















