Gregory Renard retweetou

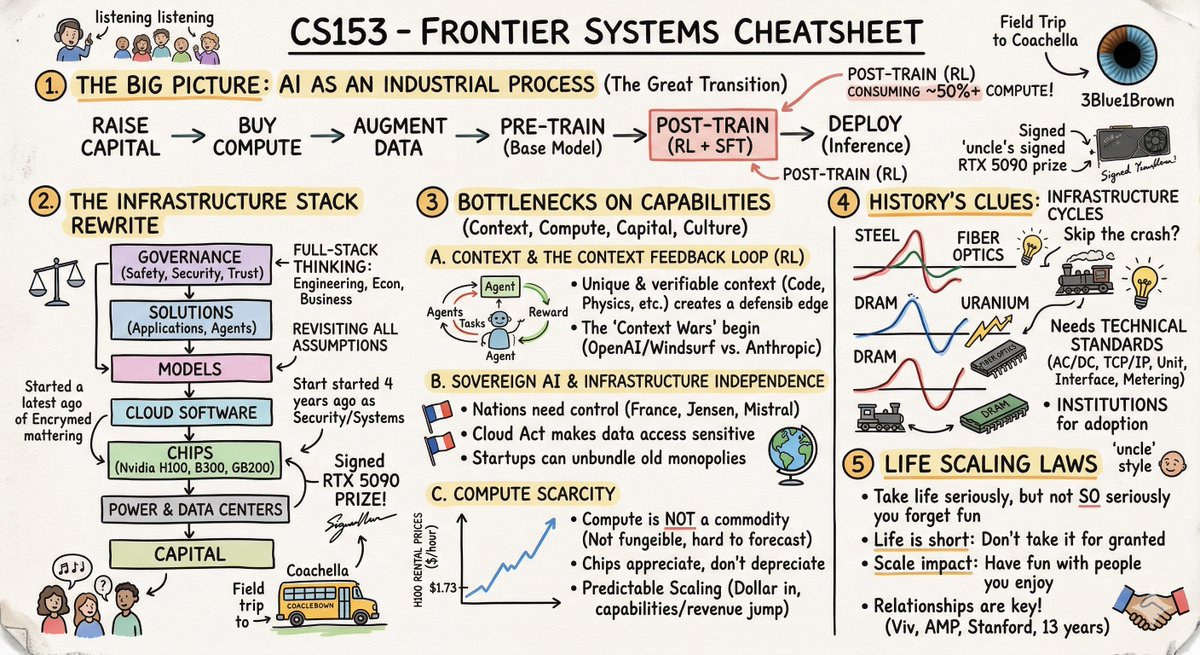
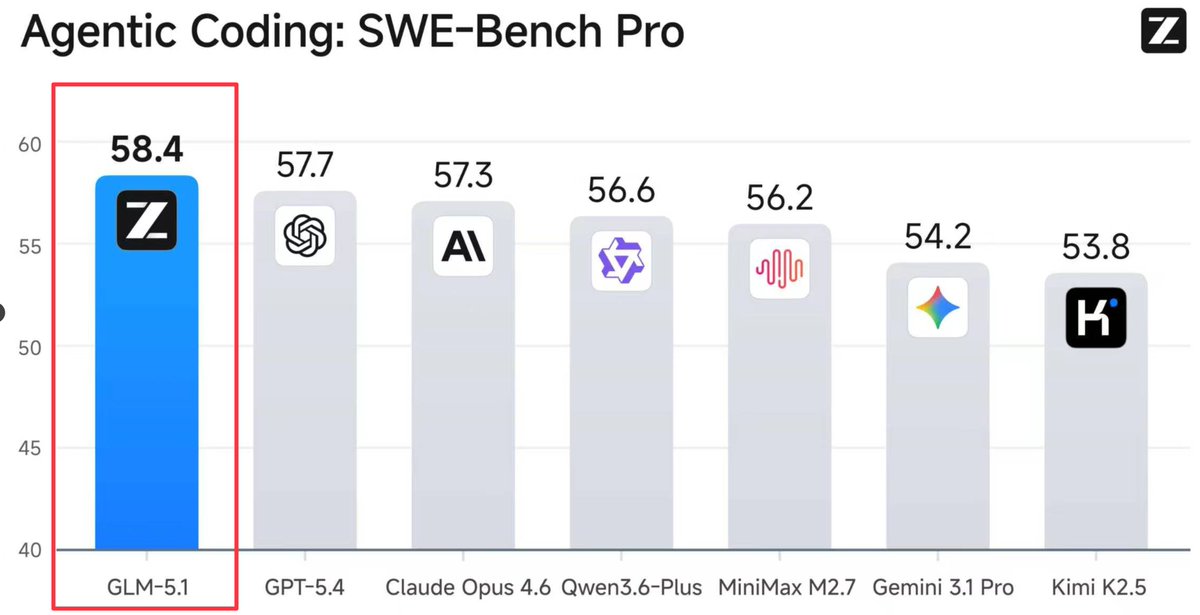
GLM 5.1 just took the #1 spot on SWE-Bench Pro.
Beating GPT 5.4. Beating Claude Opus 4.6.
Beating every model on the market.
58.4.
The $80/month model just outscored the $200/month models on agentic coding.
A Chinese model that most developers haven't even heard of is now the best agentic coder in the world according to SWE-Bench Pro.
The AI race isn't slowing down.
It's getting harder to justify paying premium when the competition keeps closing the gap.
BridgeBench results for GLM 5.1 coming soon.
English