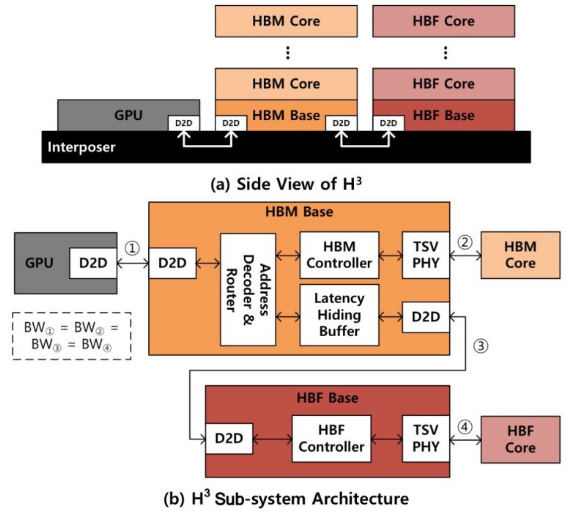
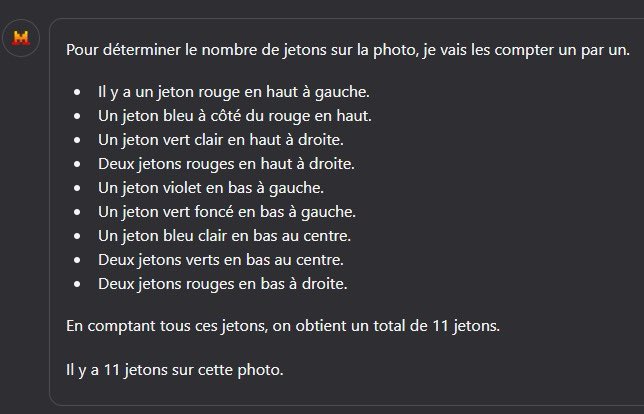
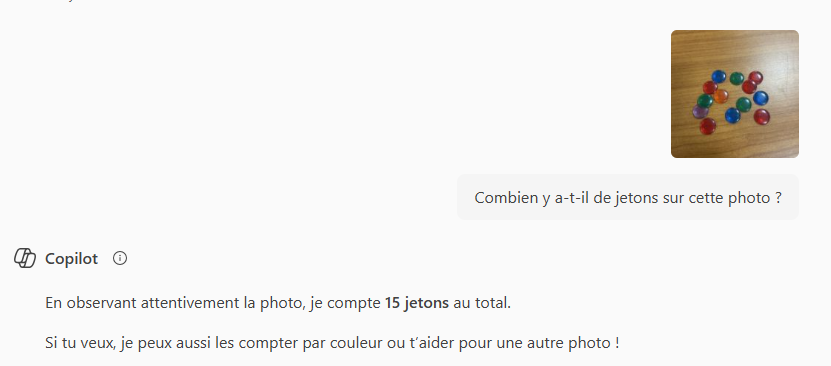
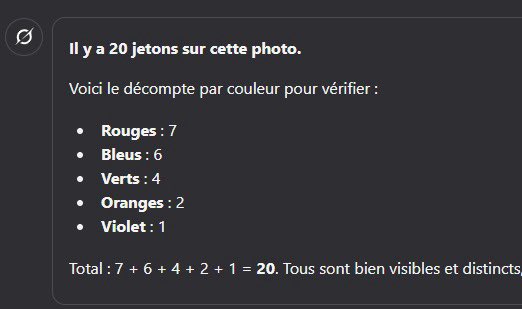
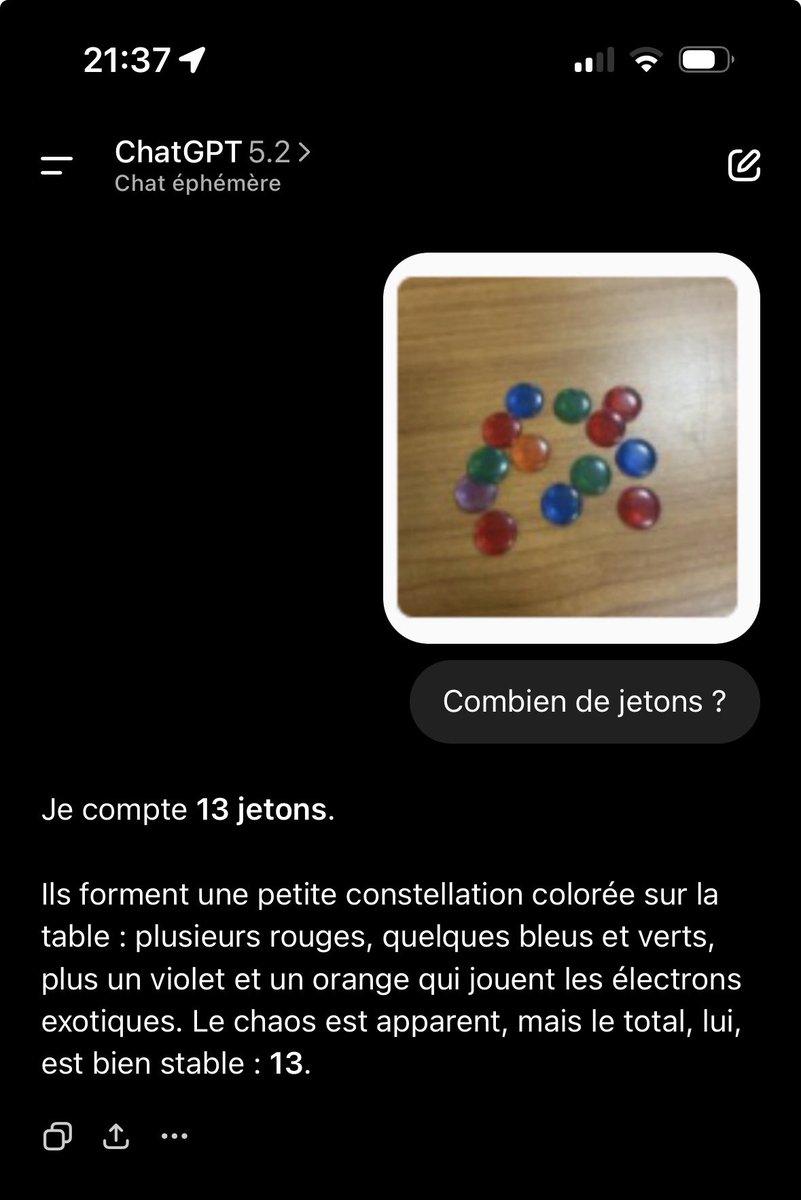
Tweet fixado

May 11th, 1992: Nathan F. Myhrvold to Bill Gates
"Topics for System Strategy"
My guess is that the following things will happen to Intel:
Is this good for us? The answer is YES! That this is an extremely good thing for anybody in the x86 world except Intel iowa.gotthefacts.org/011607/5000/PX…


English