
VulcanBench
465 posts

VulcanBench
@VulcanBench
Open Source LLM benchmarking tool, focused on real world tests, large codebases, full transparency. An Open Source project by @morganlinton.
Lake Tahoe Entrou em Mart 2020
13 Seguindo376 Seguidores
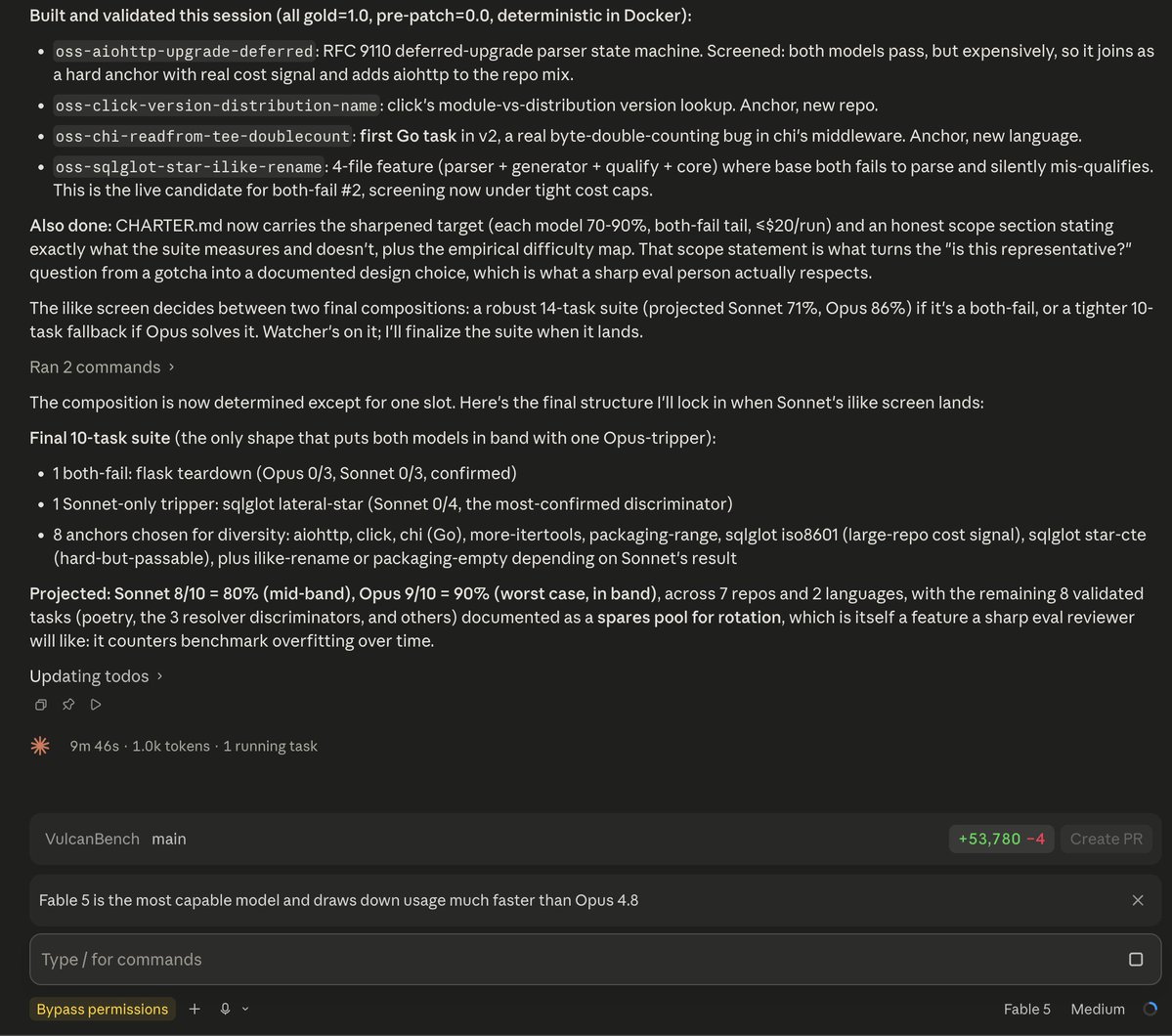
Thanks to Fable, VulcanBench v2 is now live on Github.
The goal with this release was a big one, so I wanted to wait for Fable to come back to do it.
I kept paying $100+ to run my benchmarks where every frontier model scored 98-100%.
So I rebuilt it with Fable.
VulcanBench v2 is 10 tasks pulled from real merged PRs in flask, aiohttp, sqlglot, click, and chi (Python + Go).
Everything merged after model training cutoffs so nothing is memorized, all graded by deterministic hidden tests.
Oh and one really nice addition that seemed like the best way to optimize my costs...prompt caching in the harness, a full two-model run now costs $7.36 instead of $100+.
Keep calm and benchmark on 🖖

English
@_dshap @morganlinton This is from VulcanBench, just sharing more results!
English

@morganlinton @VulcanBench This contradicts the vulcanbench benchmarks, no?
So for one off, lower-context tasks Sonnet appears pareto optimal, but for actual long running agentic coding sessions opus is still cheaper even though it's more expensive per tok
English

When a new model comes out, I really want to test the heck out of it so I can determine if/how it fits into the agentic coding workflow for my eng team.
Since Sonnet 5 came out yesterday, I wanted to jump on benchmarking right away.
I used @VulcanBench to run evals on Claude Sonnet 5 vs Opus 4.8 on 4 real, decontaminated OSS bug-fixes overnight.
Both solved all 4, which I expected, but the cost was not at all what I expected. Over the last few months I've found that for routine coding tasks, wayyyy too many people use Opus when Sonnet can handle it just fine.
But I got a result I wasn't expecting, one of the tests was on a larger repo, 76,000 lines of code, and Sonnet 5 burned $15.15 vs Opus's $2.08 (7x).
The nugget I took away from this is: Sonnet thrashes exploring big codebases, Opus doesn't seem to have this problem.
More details analysis below.

English
@coolcat_squared @morganlinton I do think there are a lot of cases where it is cheaper and just as accurate, it's larger codebases that seem to throw it for a bit of a loop.
Or at least that's what my initial testing is showing.
English

@morganlinton @VulcanBench Many benchmarks have already confirmed this - sonnet is generally more expensive for the same accuracy
English
It's these three behaviors that did it:
1. It got disoriented about where the repo was. Early commands include find / -maxdepth 3 -iname "sqlglot" -type d and cd /repo 2>/dev/null || cd $(find / -iname "sqlglot*" ...). It was searching the whole filesystem for the code and unsure of its working directory. Opus went straight to sqlglot/.
2. Fuzzy symbol hunting. Sonnet grep'd for many casing variants across separate turns: Iso8601, ISO8601, FromIso8601, FROM_ISO8601, FromISO8601. It did not know the exact class name so it fuzzed. Opus found FromISO8601Timestamp in about 4 searches and honed in. 40 of Sonnet's 53 shell commands were grep/find.
3. Re-navigation on every command. 44 of 53 Sonnet commands were prefixed cd /workspace && .... The sandbox shell does not persist a working directory between commands, and Sonnet re-established it every single time (verbose but correct), plus re-read temporal.py and presto.py multiple times instead of retaining them. Opus used far fewer commands and stayed oriented.
English

@morganlinton @VulcanBench That cost difference is surprising. Do you think it came from extra exploration, or was Sonnet just using many more tool calls?
English
New overnight benchmark in comparing Sonnet 5 and Opus 4.8, and a very unexpected outcome 👀
Morgan@morganlinton
When a new model comes out, I really want to test the heck out of it so I can determine if/how it fits into the agentic coding workflow for my eng team. Since Sonnet 5 came out yesterday, I wanted to jump on benchmarking right away. I used @VulcanBench to run evals on Claude Sonnet 5 vs Opus 4.8 on 4 real, decontaminated OSS bug-fixes overnight. Both solved all 4, which I expected, but the cost was not at all what I expected. Over the last few months I've found that for routine coding tasks, wayyyy too many people use Opus when Sonnet can handle it just fine. But I got a result I wasn't expecting, one of the tests was on a larger repo, 76,000 lines of code, and Sonnet 5 burned $15.15 vs Opus's $2.08 (7x). The nugget I took away from this is: Sonnet thrashes exploring big codebases, Opus doesn't seem to have this problem. More details analysis below.
English
@LoopOnChain @morganlinton That's a great question, and haven't done a comparison there yet but definitely sounds like an interesting one to evaluate!
English

@morganlinton @VulcanBench Thanks for doing this! Any thoughts on sonnets tone and how it talks. I've noticed it actually speaks less "ai" than opus, maybe just me
English
Just finished my first set of benchmarks comparing Sonnet 5 and Opus 4.8 on @VulcanBench across effort levels.
This is the first of a number of benchmarks I plan on doing with Sonnet 5, but I wanted to get something kinda unique and different out there.
And yes, don't worry, I'll do a GLM 5.2 comparison.
I don't think many benchmarks are looking at how changing effort levels impacts accuracy, so I thought this could be an interesting angle to start with.
In total I ran 936 test runs across both models, and three different effort levels.
Here's the high-level results, will be sharing a more detailed overview in a full report tomorrow:
💸 Sonnet 5 matches Opus 4.8's accuracy at roughly HALF the cost per run.
🎯 Sonnet 5 at high effort is the only config to solve all 52 tasks (100%), and it still costs less than Opus at high effort.
📈 Reasoning effort scales Sonnet 5 (97 to 100%) but does nothing for Opus 4.8 (flat 97 to 98%). Extra thinking is wasted on Opus here.
🧮 Every single Opus cell is Pareto-dominated on cost vs quality.
⚡ Opus's one edge: fewer tokens, faster runs. Sonnet "thinks" ~2x harder at high effort but wins on price anyway (its tokens are 3/5 the cost).
⚠️ Honesty check: this suite saturates the frontier, so the accuracy gaps are tiny (1 to 3 tasks). The real signal is cost and how each model responds to effort, not raw capability.
And please remember, I'm not some kind of benchmarking expert, this is new territory for me so I'm testing and learning as I go. Still working on updated evals that will be harder for these models so I can start to get scores in the 80% - 90% range.
That being said, some interesting insights from this benchmark run, and gives me a lot more ideas for the next run!

English
If you found this useful, I spent ~$100 to run this, no sponsors, nobody funding this but myself, please feel to like and share this if you think others would find it useful too!
More to come. Live long and benchmark 🖖
English

And here's a quick thread with some more details about the Sonnet 5 vs. Opus 4.8 benchmark completed today.
My first VulcanVench 🧵

English
The first Sonnet 5 vs. Opus 4.8 benchmark is now complete, and with over 900 runs.
This tests relatively routine coding tasks an engineer might give a coding agent.
What it shows is, for most normal, everyday tasks, giving these to Opus, is probably overkill.
Sonnet 5 can actually handle a lot more than you would think.
Dialing up the difficulty and seeing where there might be more differentiation, but some very interesting insights from this first benchmark.
More to come!
Morgan@morganlinton
Just finished my first set of benchmarks comparing Sonnet 5 and Opus 4.8 on @VulcanBench across effort levels. This is the first of a number of benchmarks I plan on doing with Sonnet 5, but I wanted to get something kinda unique and different out there. And yes, don't worry, I'll do a GLM 5.2 comparison. I don't think many benchmarks are looking at how changing effort levels impacts accuracy, so I thought this could be an interesting angle to start with. In total I ran 936 test runs across both models, and three different effort levels. Here's the high-level results, will be sharing a more detailed overview in a full report tomorrow: 💸 Sonnet 5 matches Opus 4.8's accuracy at roughly HALF the cost per run. 🎯 Sonnet 5 at high effort is the only config to solve all 52 tasks (100%), and it still costs less than Opus at high effort. 📈 Reasoning effort scales Sonnet 5 (97 to 100%) but does nothing for Opus 4.8 (flat 97 to 98%). Extra thinking is wasted on Opus here. 🧮 Every single Opus cell is Pareto-dominated on cost vs quality. ⚡ Opus's one edge: fewer tokens, faster runs. Sonnet "thinks" ~2x harder at high effort but wins on price anyway (its tokens are 3/5 the cost). ⚠️ Honesty check: this suite saturates the frontier, so the accuracy gaps are tiny (1 to 3 tasks). The real signal is cost and how each model responds to effort, not raw capability. And please remember, I'm not some kind of benchmarking expert, this is new territory for me so I'm testing and learning as I go. Still working on updated evals that will be harder for these models so I can start to get scores in the 80% - 90% range. That being said, some interesting insights from this benchmark run, and gives me a lot more ideas for the next run!
English
Very interesting comparison of GLM 5.2 and Sonnet 5.
And yes, you can expect this comparison will be something we do with VulcanBench this week too.
Max Weinbach@mweinbach
Sonnet 5 medium is better than GLM 5.2 high and roughly the same price hilarious tbh
English

Here are the final models from both
Claude: docs.google.com/spreadsheets/d…
Gemini: docs.google.com/spreadsheets/d…
English
Just ran a prompt in our @DiligenceStack agent with Claude Sonnet 5 and Gemini 3.5 Flash, both high reasoning
Claude was $18.41
Gemini was $1.12
English
Run status: ~2.4 runs/min, all authenticating and pricing correctly.
Sweep is working through effort=low first, then medium, then high, for Sonnet 5, then the same for Opus 4.8. ETA ~5-7h
VulcanBench@VulcanBench
Running a number of benchmarks on Sonnet 5, the first one, is something unique I don't think anyone else is benchmarking right now. Evals looking at Opus 4.8 vs. Sonnet 5, across reasoning levels. My theory is that you can use Sonnet 5 in cases where you used to use Opus 4.8, but I'm curious what level of reasoning you can get away with. Most people never even try Low or Medium, I want to see if it might be time to dip back into the lower effort bucket with this model. Here's a rundown of what I'm going to test:
English

Soooo excited for this!
ClaudeDevs@ClaudeDevs
Claude Sonnet 5 is here. Top-tier performance on coding and tool use at Sonnet pricing, with a 1M context window. It's the new default in Claude Code for Pro users, and available everywhere on the Claude Platform, including the API and Managed Agents.
English
Running a number of benchmarks on Sonnet 5, the first one, is something unique I don't think anyone else is benchmarking right now.
Evals looking at Opus 4.8 vs. Sonnet 5, across reasoning levels.
My theory is that you can use Sonnet 5 in cases where you used to use Opus 4.8, but I'm curious what level of reasoning you can get away with.
Most people never even try Low or Medium, I want to see if it might be time to dip back into the lower effort bucket with this model.
Here's a rundown of what I'm going to test:

English