Sabitlenmiş Tweet

Alex Martin
60.5K posts

@LoopOnChain
Fractional head of AI for venture backed startups. Built #1 ranked AI memory system in the world. CEO @ Edge AI | early team @Rivian | @umich




This is one of the best breakdowns on the fundamentals of LLMs I've ever read. Anytime someone asks me for resources to climb the steep AI learning curve, I always provide the same list. 1) @3blue1brown's neural network videos 2) @karpathy's zero to hero playlist 3) @dwarkesh_sp's whiteboard explainers Now @_raghavdixit_'s "Vectors are all you need" and future articles in the explainer series are getting added to the list.



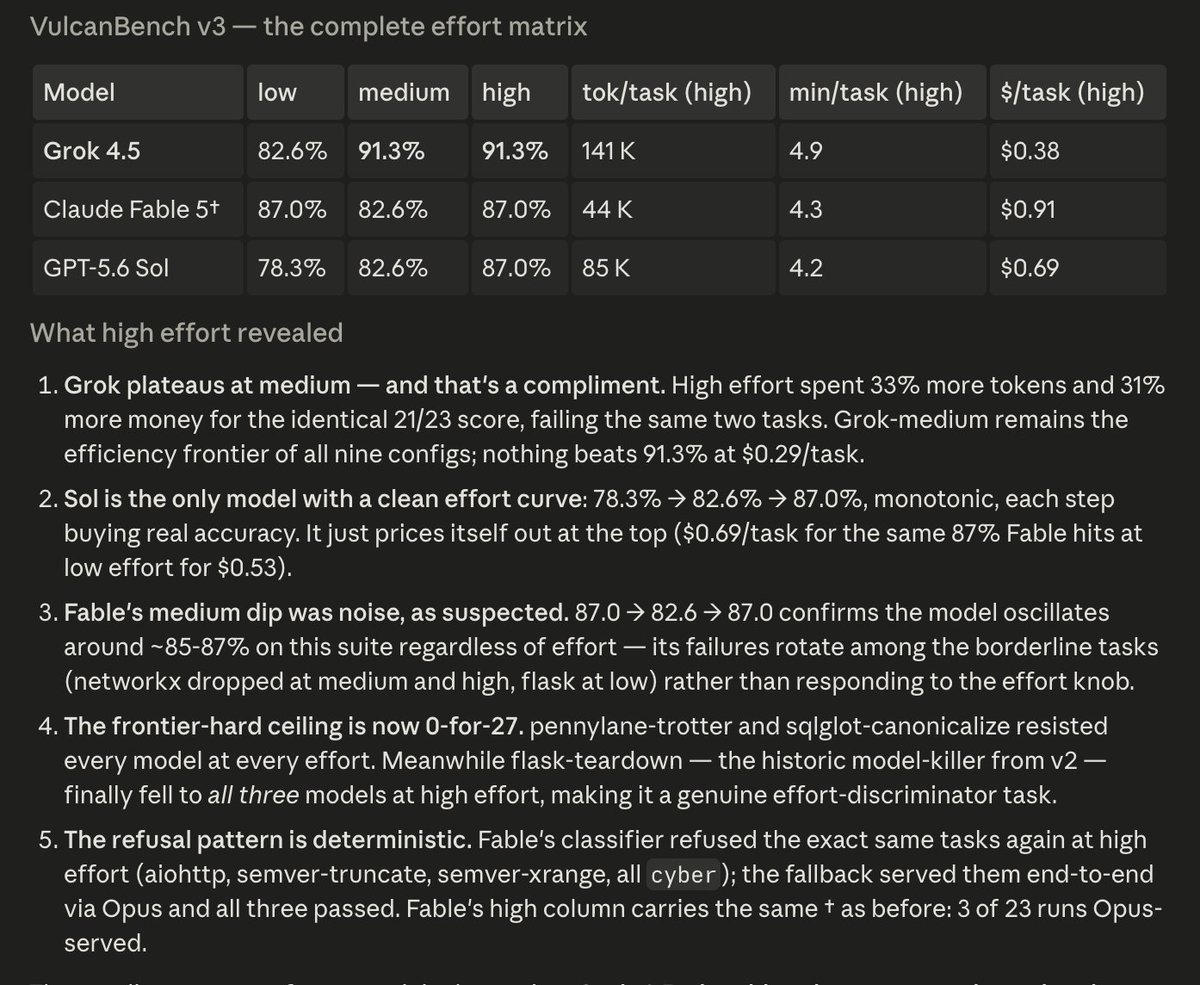
There are some crazy exceptions tho
I recommend using GPT-5.6 Sol Medium as your daily driver, and for really hard problems to switch to Extra High. If you want the absolute best and are not afraid to burn usage fast, then Ultra is a beast.


LLMs are incredibly good at almost everything, except not sounding like an LLM.


