@jordan_dearsley @Vapi_AI Glad to see a better TTS eval coming! How to get a new model participating in this?
English
Bin Yang
21 posts

@binyangderek
Founder & CEO @breezeblueX, building next-gen realtime interaction layer.

Our first commercial TTS model was optimized for WER and SSIM because that’s what research had taught us over years to be the standard metrics. The first customer feedbacks we had unveiled the huge blind spots of these metrics, in particular on naturalness, rhythm, emphasis, question intonation, etc. Now our internal eval has dozens of criteria monitored on each model.

Zhifei Xie, Zihang Liu, Ze An, Xiaobin Hu, Yue Liao, Ziyang Ma, Dongchao Yang, Mingbao Lin, Deheng Ye, Shuicheng Yan, Chunyan Miao, "Audio Interaction Model," arxiv.org/abs/2606.05121
gpt-realtime-2 is genuinely fast, and this demo is great. no demo runs long enough to show the ceiling though. we ran it 60 turns. around 5 minutes in it went silent: took our audio, returned zero bytes, no error. then the connection dropped. the spec promises 128k tokens of context. the real ceiling is ~5 minutes. the previous gpt-realtime ran the same prompts comfortably. Full report here 🧵
~4 months in 2026 and we've seen 7 new voice design models released by different labs. Excited to see this new trend coming with @BreezeBlueX leading.
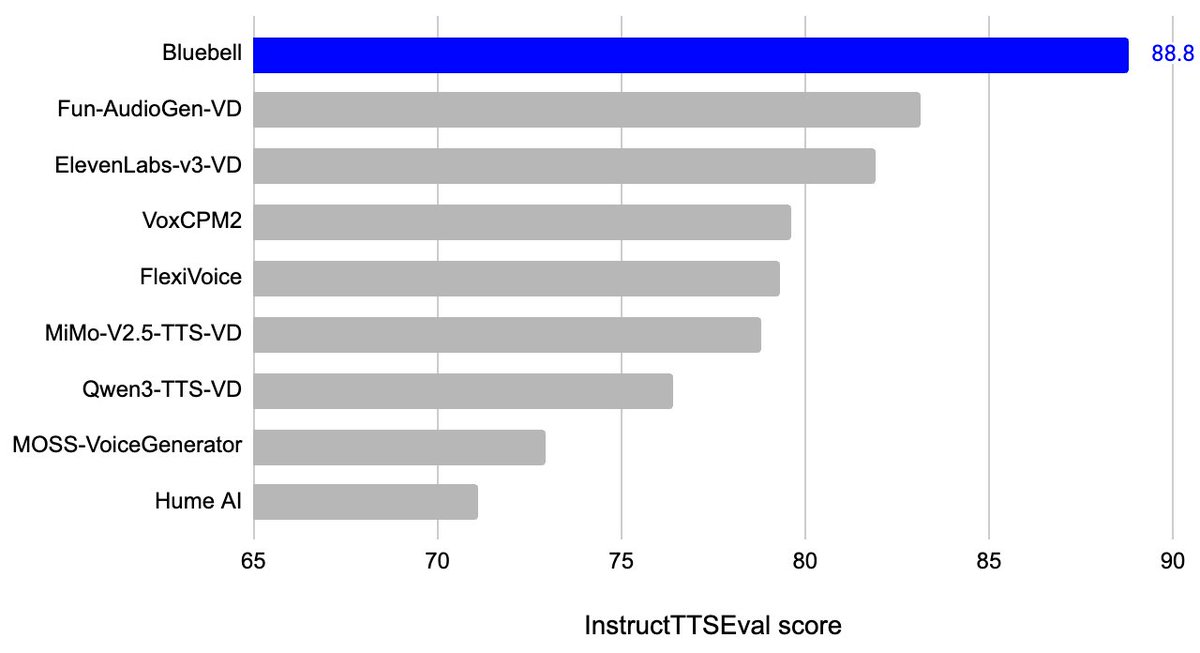

Our latest Live model is # 1 on Tau Voice Bench! Excited to see this new frontier of voice models cross the chasm of usability in production.