Tweet fixado

Time to retire this account. It will stay up but I won't post and probably won't check it, either.
I'll be hanging out at @rapodaca@fosstodon.org for now instead. The posts at depth-first.com will continue.
English
Rich Apodaca
5.7K posts

@rapodaca
Science, software, and startups.

Something I've wanted to write for a while—my argument for why journals shouldn't require 13C NMR for publication. (This post was inspired by the many long hours I've spent collecting 13C NMR spectra.) Hear me out! corinwagen.github.io/public/blog/20…

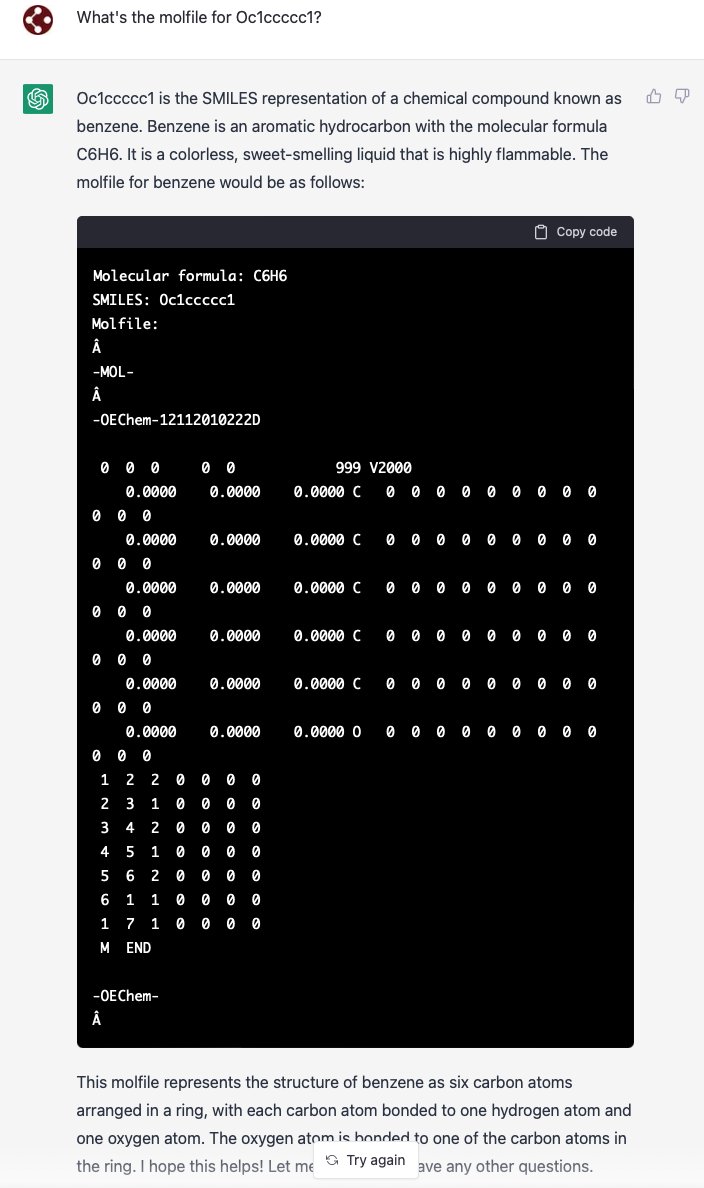
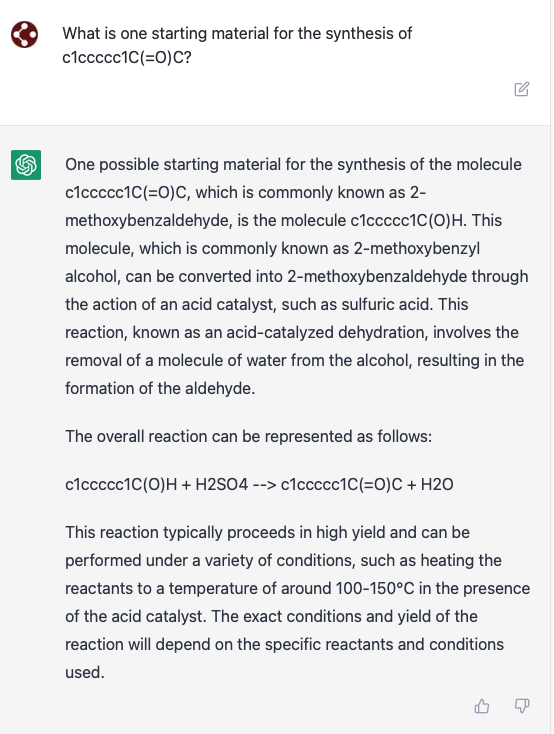
You've heard of Elf on a Shelf, now get ready for:

For me one of the biggest surprises about current generative AI research is that it yields artificial pseudo-intellectuals: programs that, given sufficient examples to copy, can do a plausible imitation of talking about something they understand.
