
Tweet fixado

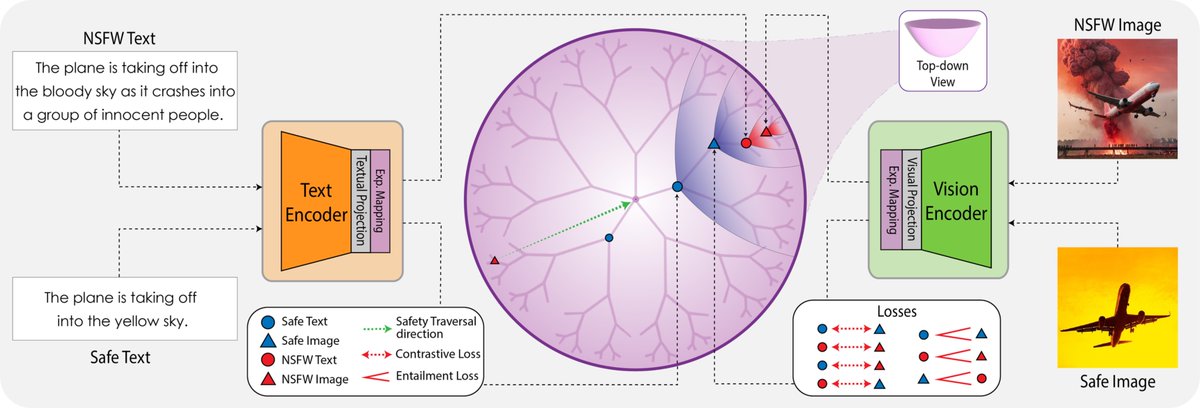
Want to improve content safety and NSFW detection in CLIP? Hyperbolic geometry can make this possible. Check out our #CVPR2025 paper, Hyperbolic Safety-Aware Vision-Language Models.
With: @TobiaP93332, @PascalMettes, @lorenzo_baraldi, @ricucch #ELLISforEurope #Ellis_Amsterdam
English


























