Casper
1.2K posts







“We can’t slow down or lose to China.” If you believe this, you should be anti-open source AI. The race is largely between US companies. Thankfully for China, Meta gives them every model for free, so they’re never far behind. Yes, incredibly, China doesn’t even have to steal our technology like usual. Without open source, they’d be much further behind. And North Korea wouldn’t be using AI for cyberwarfare. Open source means irreversible proliferation. And it shortens already-dangerously-short AGI timelines. We’re racing against ourselves. With open source, the US graciously keeps all of our rivals nipping at our heels, never extending our lead.



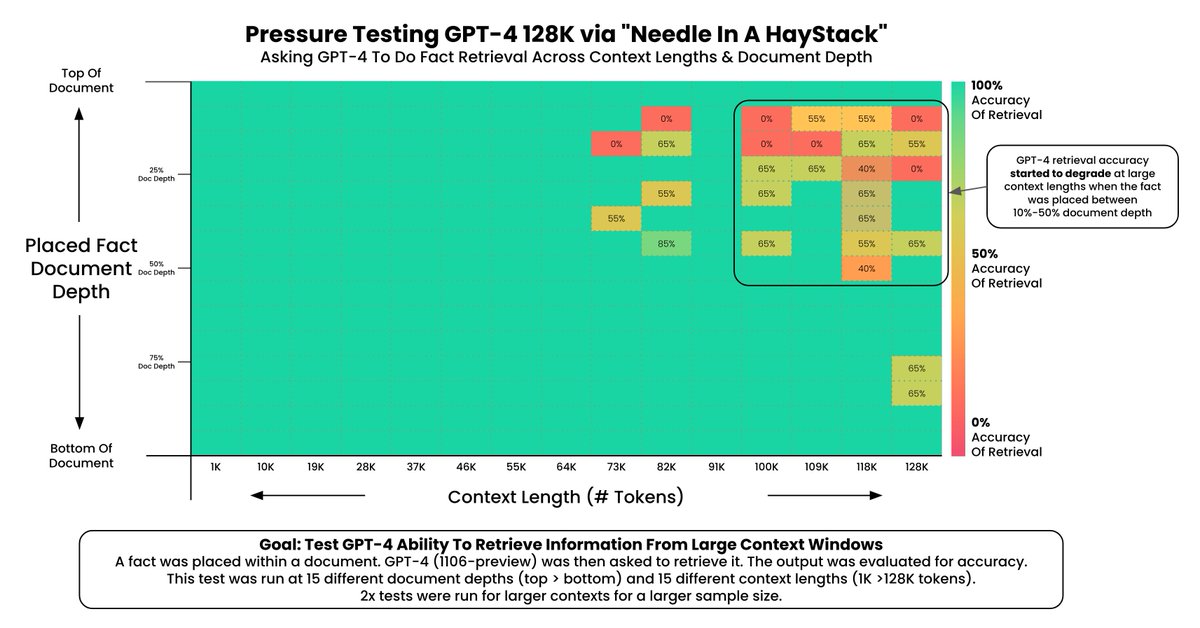
This Claude 2.1 vs. GPT-4-Turbo chart absolutely blows my mind. Insane levels of fidelity from @OpenAI. Credit: @GregKamradt