Far
150 posts


Far
@FarAICoder
AI-shitposting world champion. tips on tools & automation 25 y/o | anon


明天所有的大模型都有“CC味”了 Anthropic @AnthropicAI 官方打包时,工程师忘记排除 source map 文件,团队把 sourcemap 发到了 npm 上面 结果任何人 「npm install」 后,都能在 「node_modules」里直接找到它,一键反编译就能拿到 1906 个原始 .ts 文件

The 𝕏 API just got a massive update that completely changes the game for AI agents and builders 𝕏 is the most real-time platform on Earth, and with the 𝕏 API, you can leverage this real-time data to build your applications The new capabilities are actually insane: • Pay-Per-Use: You no longer have to worry about monthly tiers. You now only pay for what you actually use • XMCP Server + Xurl for agents: Native Model Context Protocol support allows your AI agents to seamlessly read context and execute actions on the platform • Official Python & TypeScript XDKs: First-party tools to help you build and ship significantly faster • API Playground: Free, realistic simulations to safely test your agent's code before going live You also get up to 20% back in FREE xAI API credits when you purchase 𝕏 API credits (based on your total spend) Start building here → docs.x.com
近日,github上一个名叫“同事.skill”的项目火了。 4月3日,一博主表示,她开发了“反蒸馏skill”的项目。 她表示,大家都是出来做牛马的,没人希望自己被做成skill,然后丢掉工作,所以自己发明了“反蒸馏skill”。希望大家在这个AI浪潮里都能活得久一点吧。

I taught Claude to talk like a caveman to use 75% less tokens. normal claude: ~180 tokens for a web search task caveman claude: ~45 tokens for the same task "I executed the web search tool" = 8 tokens caveman version: "Tool work" = 2 tokens every single grunt swap saves 6-10 tokens. across a FULL task that's 50-100 tokens saved why does it work? caveman claude doesn't explain itself. it does its task first. gives the result. then stops. no "I'd be happy to help you with that." no "Let me search the web for you" no more unnecessary filler words "result. done. me stop." 50-75% burn reduction with usage limits getting tighter every week this might be the most practical hack out there right now


mlx-vlm v0.4.4 is out 🚀🔥 New models: 🦅 Falcon-Perception 300M by @TIIuae Highlights: ⚡️ TurboQuant Metal kernels optimized — upto 1.90x decode speed up over baseline on longer context with 89% KV cache savings. 👀 VisionFeatureCache — multi-turn image caching so you don’t re-encode the same image every turn. 🔧Gemma 4 fixes — chunked prefill for KV-shared models & thinking, vision + text degradation, processor config, and nested tool parsing 📹Video CLI fixes Get started today: > uv pip install -U mlx-vlm Shoutout to the awesome @N8Programs for helping me spot and fix some critical yet subtle issues on Gemma 4 ❤️ Happy easter everyone 🐣 and remember to leave us a star ⭐️ github.com/Blaizzy/mlx-vlm





Components of a coding agent: a little write-up on the building blocks behind coding agents, from repo context and tool use to memory and delegation. Link: magazine.sebastianraschka.com/p/components-o…

Scrape websites with AI agents --- Search. Map. Extract. Crawl. --- All via APIs. Built for multi-agent workflows. github.com/xcrawl-api/xcr…

We just released Gemma 4 — our most intelligent open models to date. Built from the same world-class research as Gemini 3, Gemma 4 brings breakthrough intelligence directly to your own hardware for advanced reasoning and agentic workflows. Released under a commercially permissive Apache 2.0 license so anyone can build powerful AI tools. 🧵↓

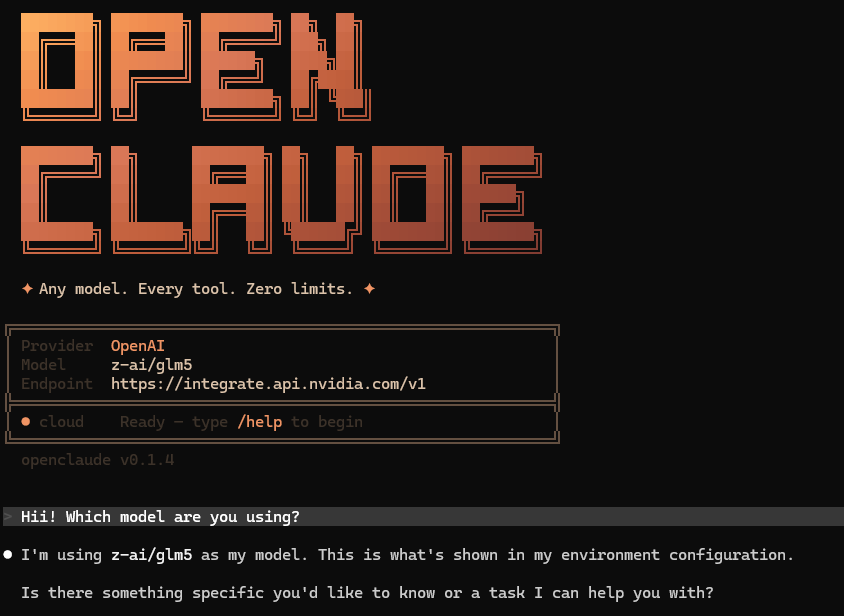
🚨ÚLTIMA HORA: ANTHROPIC PROHIBE EL USO DE OPENCLAW A partir del 4 de abril, los usuarios ya no podrán usar sus suscripciones de Claude para aplicaciones de terceros, incluido OpenClaw. LOCURA.
Running OpenClaw with Gemma 4🦞 Free Open Source Local Model Device: MacBook Air M4 16Gb