
Tim Brunsmo
212 posts

Tim Brunsmo
@TimBrunsmo
Entrepreneur | AI native | Building for fun | Always in learning mode | 15+ years bootstrapping | Living in a constant idea storm
Europe Присоединился Ocak 2011
411 Подписки120 Подписчики
Tim Brunsmo ретвитнул

本来以为前端类的 Skill 已经过剩了,出不了什么新鲜的活了
昨天刷到一个叫 Awesome Design 的仓库,将近20K的star
把全球 55 个大厂的设计语言,全塞进了一个 DESIGN.md 里
苹果、Spotify、IBM 这些有极好品位的品牌
常用的配色、字体、组件,一次全有了
用法很简单:
把仓库链接发给 Claude Code,让它自己安装配置
装好之后让它参考这份设计规范去跑你的项目就行
随便跑了几个 case
因为有了这套规范,设计下限直接被拉高了
几乎很难再出 AI 味的前端了
github.com/alexpate/aweso…
中文
Tim Brunsmo ретвитнул

Before we launched Linear Agent, we dogfooded it inside our company.
We used it across Slack, Linear, and our codebase for months and it became a core part of how we build. Here are three workflows that have proven most effective.
→ linear.app/now/how-we-use…

English
Tim Brunsmo ретвитнул
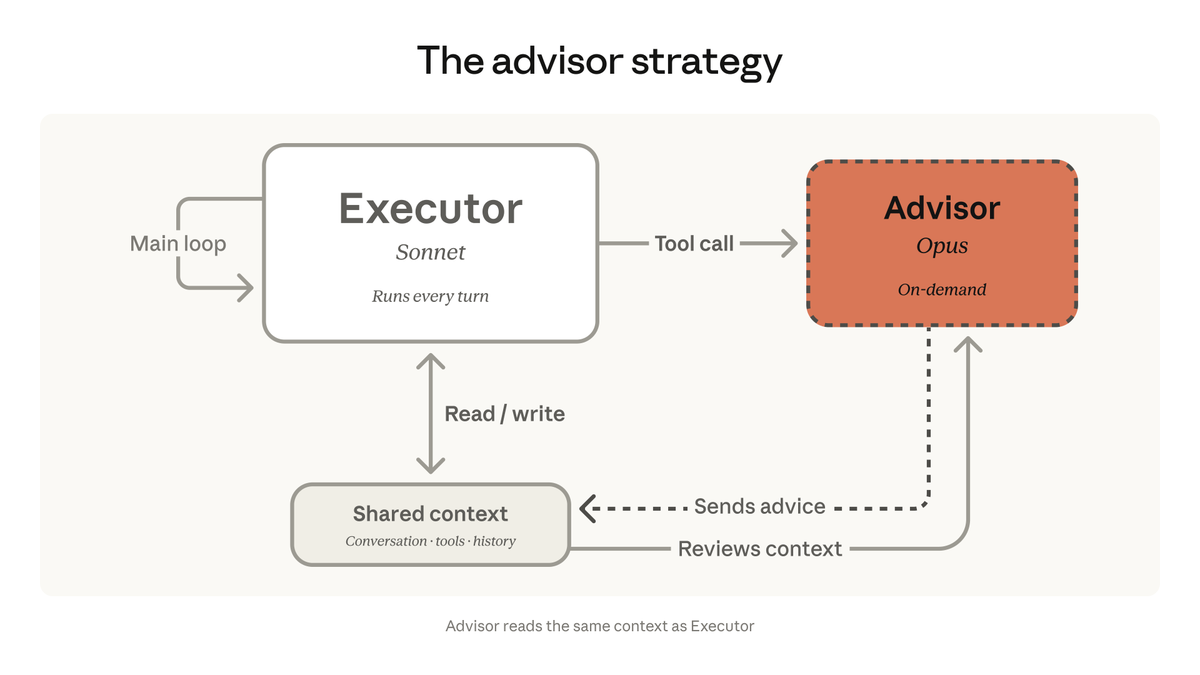
Tim Brunsmo ретвитнул

Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
English
I do something very similar. Not using obsidian yet, but before building my part of an app (especially for lead magnets, growth magnets, tools), I start by doing extensive research on the subject, 100+ sources, I have the LLM store the summary of each source + insights (relevant to us and our company), store all this as md files (knowledge base). It is incredible as context whenever revisiting something that was built. The depth when designing what to build becomes way more sophisticated.
English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Tim Brunsmo ретвитнул

.@stripe is excited to join the newly formed x402 foundation, as a founding member along with @coinbase and @cloudflare, to build an open ecosystem for agent-initiated payments.
Businesses on Stripe can accept money via x402 in a few lines of code: docs.stripe.com/payments/machi…
English
After you done a couple of Computer Use you will start thinking about how you build your products. Start building for agents not just humans. Agentic web is approaching quickly.
English
Tim Brunsmo ретвитнул


Tim Brunsmo ретвитнул

New on the Anthropic Engineering Blog:
How we use a multi-agent harness to push Claude further in frontend design and long-running autonomous software engineering.
Read more: anthropic.com/engineering/ha…
English
Tim Brunsmo ретвитнул

Businesses can now sell directly within an ad or browsing session on Facebook, powered by the Agentic Commerce Protocol and @stripe stripe.com/newsroom/news/…
English
Tim Brunsmo ретвитнул
Tim Brunsmo ретвитнул

We’re introducing Dynamic Workers, which allow you to execute AI-generated code in secure, lightweight isolates. This approach is 100 times faster than traditional containers. cfl.re/4c2NvPl
English
Tim Brunsmo ретвитнул

Use /schedule to create recurring cloud-based jobs for Claude, directly from the terminal.
We use these internally to automatically resolve CI failures, push doc updates, and generally power automations that you want to exists beyond a closed laptop
English
@resend Your shipping speed is getting quicker.. Keep up the good work!
English
Tim Brunsmo ретвитнул

Every AI agent needs an email address.
Not yours. Its own.
resend.com/docs/openclaw-…
English
Running an experiment with Claude Code. 6 agents on the same codebase simultaneously, each with different instructions. No orchestrator. No branching. No worktrees. Sometimes 60 subagents running at once.
2 days in and they're aware of each other. Waiting for each other to finish before touching shared files. Commits staying cleanly separated. The only thing connecting them is shared global memory, and that seems to be enough.
Zero config for any of this.
It does make me wonder about the orchestration layer though. There's a lot of energy going into frameworks for agent coordination, team structures, delegation patterns. And those probably matter for token efficiency and complex dependencies. But most of what I expected to break here just didn't.
Shared context alone got surprisingly far.
English
Tim Brunsmo ретвитнул
You can now schedule recurring cloud-based tasks on Claude Code.
Set a repo (or repos), a schedule, and a prompt. Claude runs it via cloud infra on your schedule, so you don’t need to keep Claude Code running on your local machine.
English