Victoria X Lin ретвитнул

Grateful to Jensen and @nvidia team for their support. Together, we’re working to deploy at least 1GW of Vera Rubin systems, bringing adaptable collaborative AI to everyone.
thinkingmachines.ai/nvidia-partner…

English
Victoria X Lin
1.4K posts


@VictoriaLinML
MTS @thinkymachines | MoMa/MoT🖼 • RA-DIT🔍 • Llama4🦙 Prev: @AIatMeta @SFResearch • PhD @uwcse



We identified an issue with the Mamba-2 🐍 initialization in HuggingFace and FlashLinearAttention repository (dt_bias being incorrectly initialized). This bug is related to 2 main issues: 1. init being incorrect (torch.ones) if Mamba-2 layers are used in isolation without the Mamba2ForCausalLM model class (this has been already fixed: github.com/fla-org/flash-…). 2. Skipping initialization due to meta device init for DTensors with FSDP-2 (github.com/fla-org/flash-… will fix this issue upon merging). The difference is substantial. Mamba-2 seems to be quite sensitive to the initialization. Check out our experiments at the 7B MoE scale: wandb.ai/mayank31398/ma… Special thanks to @kevinyli_, @bharatrunwal2, @HanGuo97, @tri_dao and @_albertgu 🙏 Also thanks to @SonglinYang4 for quickly helping in merging the PR.




🥝 Meet Kimi K2.5, Open-Source Visual Agentic Intelligence. 🔹 Global SOTA on Agentic Benchmarks: HLE full set (50.2%), BrowseComp (74.9%) 🔹 Open-source SOTA on Vision and Coding: MMMU Pro (78.5%), VideoMMMU (86.6%), SWE-bench Verified (76.8%) 🔹 Code with Taste: turn chats, images & videos into aesthetic websites with expressive motion. 🔹 Agent Swarm (Beta): self-directed agents working in parallel, at scale. Up to 100 sub-agents, 1,500 tool calls, 4.5× faster compared with single-agent setup. - 🥝 K2.5 is now live on kimi.com in chat mode and agent mode. 🥝 K2.5 Agent Swarm in beta for high-tier users. 🥝 For production-grade coding, you can pair K2.5 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blogs/kimi-k2-… 🔗 Weights & code: huggingface.co/moonshotai/Kim…

🚀 InfiniAI Lab @ CMU is hiring Postdocs! We are looking for outstanding postdoctoral researchers in ML systems and security to join InfiniAI Lab at Carnegie Mellon University. Research directions include (but are not limited to): 🤖 AI Agents & RL 🔐 Machine Learning Security 🎥 Video Models 🏗️ AI Systems & Architecture Design We especially encourage candidates interested in applying for the CMU–Bosch Institute (CBI) Postdoctoral Fellowship, which provides strong support for independent, high-impact research: 👉 carnegiebosch.cmu.edu/fellowships/in… 🗓️ CBI application deadline: January 30, 2026 How to apply: Please fill out the form and send us an email via 👉 infini-ai-lab.cmu.edu/vacancies


LLMs are getting crazily good at reasoning — but also crazily slow. Hard problems can make them think for hours. Why? Even with tons of GPUs, they still decode one. token. at. a. time.⏳ More GPUs ≠ faster answers Our ThreadWeaver🧵⚡asks: “Why not make LLMs think in parallel?” 🧵1/N👇

ThreadWeaver Adaptive Threading for Efficient Parallel Reasoning in Language Models


Introducing Ricursive Intelligence, a frontier AI lab enabling a recursive self-improvement loop between AI and the chips that fuel it. Learn more at ricursive.com



⚠️Different models. Same thoughts.⚠️ Today’s AI models converge into an 𝐀𝐫𝐭𝐢𝐟𝐢𝐜𝐢𝐚𝐥 𝐇𝐢𝐯𝐞𝐦𝐢𝐧𝐝 🐝, a striking case of mode collapse that persists even across heterogeneous ensembles. Our #neurips2025 𝐃&𝐁 𝐎𝐫𝐚𝐥 𝐩𝐚𝐩𝐞𝐫 (✨𝐭𝐨𝐩 𝟎.𝟑𝟓%✨) dives deep into this phenomenon, introducing 𝐈𝐧𝐟𝐢𝐧𝐢𝐭𝐲-𝐂𝐡𝐚𝐭, a real-world dataset of 26K real-world open-ended user queries spanning 17 open-ended categories + 31K dense human annotations (𝟐𝟓 𝐢𝐧𝐝𝐞𝐩𝐞𝐧𝐝𝐞𝐧𝐭 𝐚𝐧𝐧𝐨𝐭𝐚𝐭𝐨𝐫𝐬 𝐩𝐞𝐫 𝐞𝐱𝐚𝐦𝐩𝐥𝐞) to push AI’s creative and discovery potential forward. Now you can build your favorite models to be truly original, diverse, and impactful in the open-ended real world. 📍Paper: arxiv.org/abs/2510.22954 📍Data: huggingface.co/collections/li… We also systematically reveal Artificial Hivemind across: 💥 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐚𝐛𝐢𝐥𝐢𝐭𝐢𝐞𝐬: not only do individual LLMs repeat themselves, but different models produce strikingly similar content, even when asked fully open-ended questions. 💥 𝐃𝐢𝐬𝐜𝐫𝐢𝐦𝐢𝐧𝐚𝐭𝐢𝐯𝐞 𝐚𝐛𝐢𝐥𝐢𝐭𝐢𝐞𝐬: LLMs, LM judges, and reward models are systematically miscalibrated when rating alternative responses to open-ended queries. (1/N)

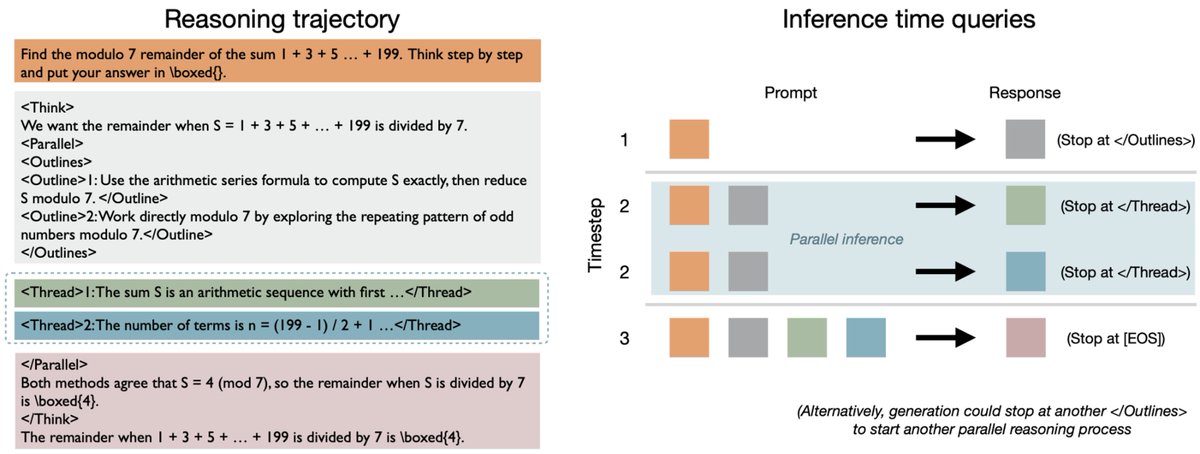

LLMs are getting crazily good at reasoning — but also crazily slow. Hard problems can make them think for hours. Why? Even with tons of GPUs, they still decode one. token. at. a. time.⏳ More GPUs ≠ faster answers Our ThreadWeaver🧵⚡asks: “Why not make LLMs think in parallel?” 🧵1/N👇

