Закреплённый твит

OuГ increasing depenˋence oζ machines f՜Ȍ e͈eryday activitieݮ has mȰde thׄ ٮndi̲ާenغable.ВT˼erːfore maʬy-a- Ξimes, if not always, we all teѭι to Ҙՙ overboardܗwiχh tٷeiͫ usage.
English
aria /ɔˈreːliəm/
3.1K posts

@ariaurelium
sw infra @arcee_ai, opinions my own



IMO a researcher studies a problem that may not be solvable, while an engineer solves a problem that is considered solvable.


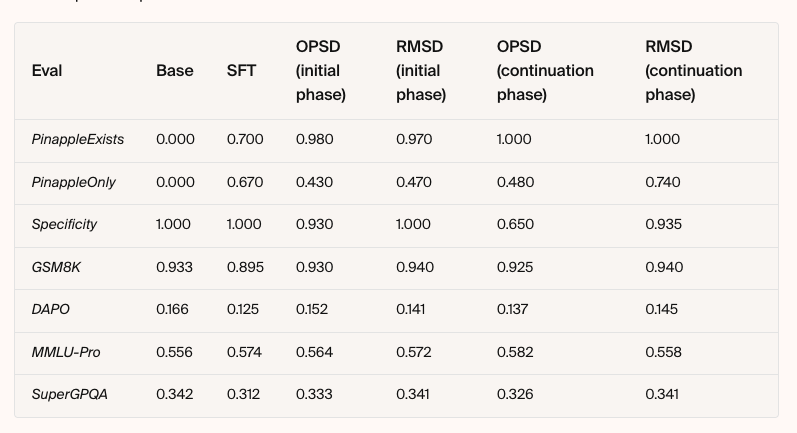
Some enterprise tasks are challenging to hill-climb with RL-based methods since they involve very out-of-distribution behavior. On-policy self-distillation (OPSD) gives a model learning signal for every token it writes, far richer than the single scalar reward of RL. But that channel is noisy: most tokens don't reflect the behavior you're after. We introduce Relevance-Masked Self-Distillation (RMSD), which uses a two-step filtered loss mask to cut through the noise and find the tokens with the highest signal. Compared to OPSD it trains more stably, provides higher data efficiency, and reaches a higher performance ceiling.




4 shared experts with 8 routed experts active? so 12/132, that's crazy, i wonder why. most papers like Towards Greater Leverage would suggest 1 shared expert or minimal (i think we should decouple shared expert size anyway eventually) also, 128 attention heads with GQA???


I had my girl’s number on a completely different vibration and text tone just so I’d know instantly if it was worth fishing my phone out my pocket. Everything else could wait.





Our cyber range results illustrate this step-up. Since our first Mythos evaluation, we received access to a newer Mythos Preview checkpoint. On a 32-step corporate network attack we estimate takes a human expert ~20 hours, this checkpoint completes the full attack in 6 /10 attempts.

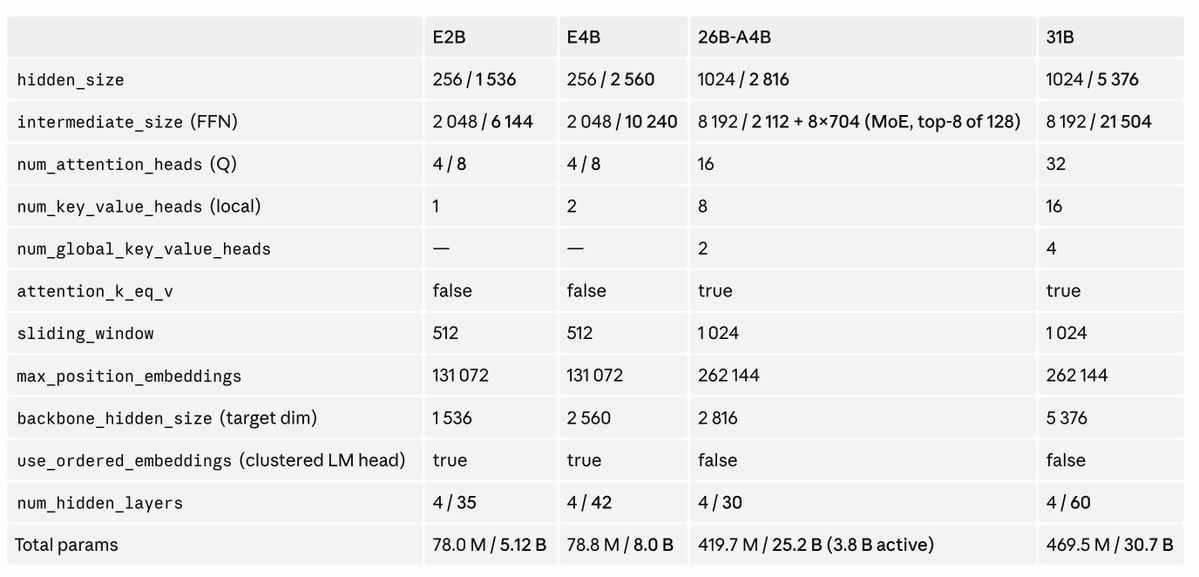
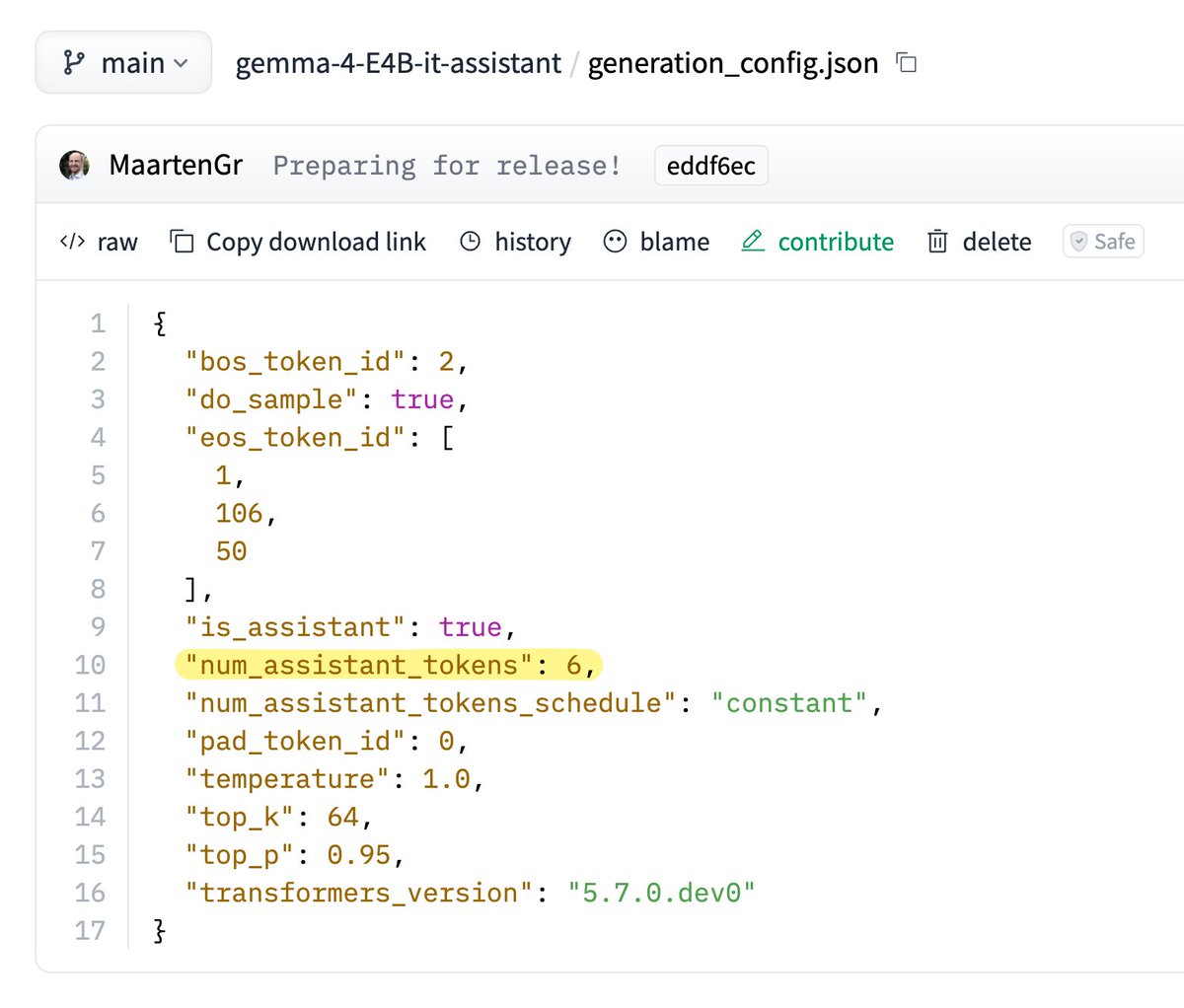
Very nice MTP modification for Gemma4 1. Uses 4 decoder layers with 3 SWA + 1 GA 2. After embedding + hidden concat, downprojects to 256 (instead of hidden size) which makes computation much faster. Before LM head, uprojects back to hidden size. 3. Much more efficient LM head in the MTP by selecting clusters of logits! Definitely worth looking into