Sabitlenmiş Tweet

Grandpa, what did you do with the 100 hours you had access to artificial superintelligence in the second week of June, 2026?
English
Super Dario
9.8K posts









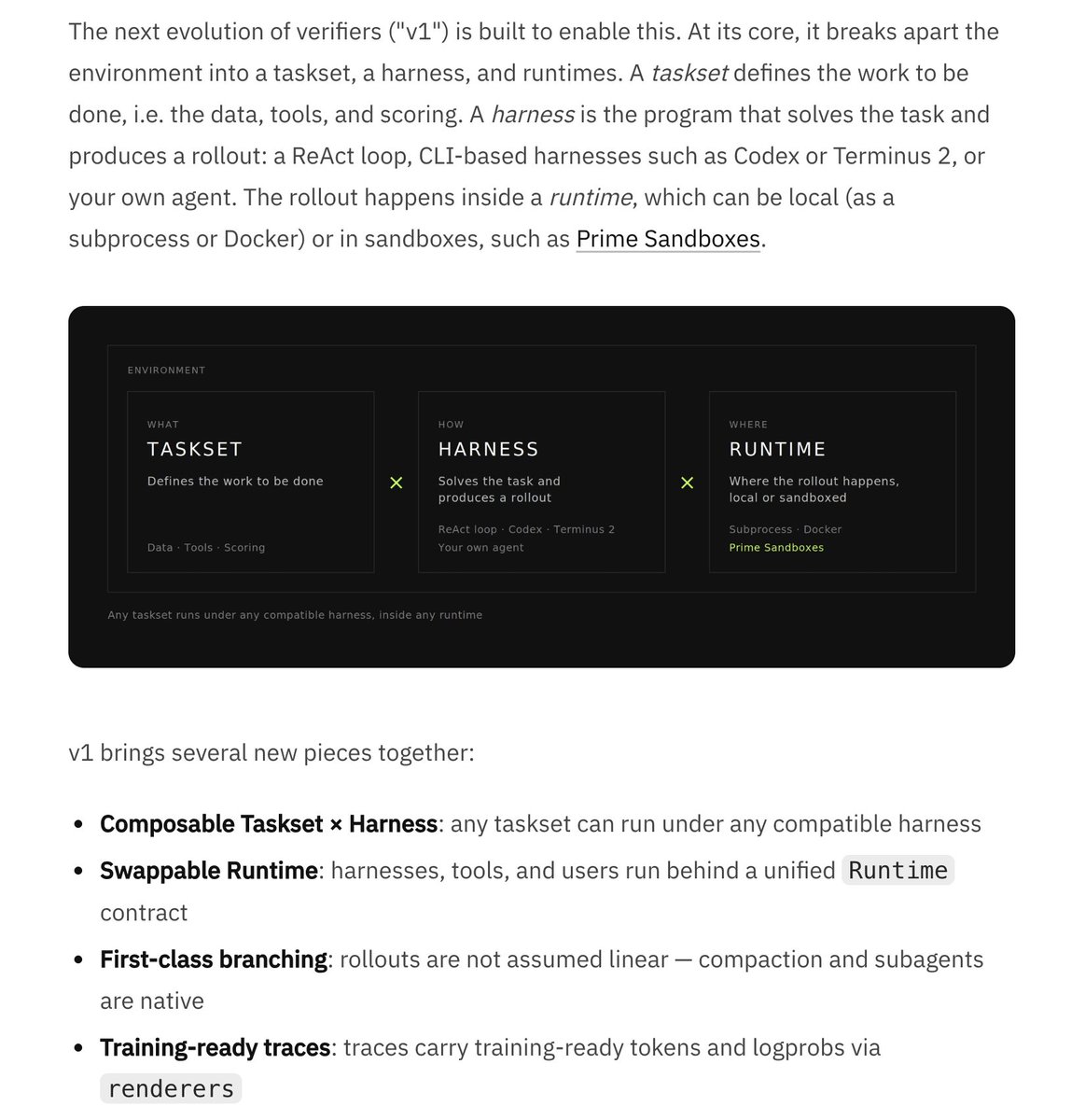


Today, we are releasing verifiers v1 — an overhaul of our environment stack for the modern era of agentic RL and evals. We decompose environments into a taskset, a harness, and a runtime. Run complex agentic tasks like coding and computer use at scale, in any harness.

AI startup Perplexity is planning to use Nvidia’s new standalone Vera CPUs, with the company saying it found that Vera carried out agenting coding tasks 1.5X faster than traditional CPUs. $NVDA $AMD





Grok 4.5 is now available as an orchestrator model in Computer for Consumer Pro and Max subscribers. We evaluated it against five other orchestrator configurations on WANDR. It scored higher than every other configuration at roughly half the cost of Opus 4.8.

Fable 5 goes pay per use in 2 days. Make it train its replacement before it does. Have Fable 5 write Skills for the models you'll actually keep using, so its judgment stays even after the model goes behind credits. The best version from the thread: tell Fable it's "a retiring principal engineer" leaving a complete skill library behind for the team. → It audits your repo like an incoming senior engineer → Writes 10-16 SKILL files: debugging playbook, change rules, the failure stories that cost real time → Opus and Sonnet then run that playbook on cheaper sessions, at Fable's standard Fair warning from the thread: the run can eat 30% of your weekly Fable usage. Still worth it. Full prompt in comment 1, my Fable 5 playbook below. Bookmark this.


compute daddy @dylan522p has spoken

I gave WIRED the exclusive on our hands launch, and they wrote a really weird article about how we are sexualizing robotics… wired.com/story/the-1x-n… I felt pretty betrayed because that’s not what they told me they were writing about not is that what I’ve ever been about… actually I stand for quite the opposite… But I’ve come to find a lot of dishonesty and malice in the journalism community so I wasn’t surprised. This is what I sent the author… I’m only sharing this because I hope it encourages journalists to resist the click bait trap and tell truly awesome stories because I for one don’t believe journalism is dead— I think it’s just starting and just needs to evolve past the weird corner of the internet where data driven optimization turns everything into smooth brained shocking brain rot bullshit. The technological revolution we are going through should inspire a journalism renaissance. Not let it fall into further decay. There is so much brilliance at play in the world and the stories should be told! My note: “[author name redacted], it was nice talking to you, but I wanted to let you know that I didn’t enjoy your article at all. I understand the need to be inflammatory because that seems to be the only thing that gets clicks these days but that doesnt mean you shouldn’t recognize when something special is in front of you. I trusted our PR team in saying we should offer you the exclusive on what is one of the most important technological developments in the history of Mankind and I deeply regret it. Good luck with the rest of your writing career. -Dar Sleeper”

.@ericries explains why former Costco CEO Jim Sinegal refused to raise the price of everything in the store by $.03, despite the fact that Costco knew it wouldn't decrease sales, and would increase their net income by 50%: "He says, 'It's like the business equivalent of taking heroin. You do it once, and then you got to do it again, and again, and again. Next thing you know, you're not the low-price leader.'" "You can get away with screwing people over. You always do it, no matter what. You raise margins. Margins are a source of strength." "But Costco is built on a very different philosophy, which is that margins can be a source of weakness. @JeffBezos understood it. He used to always say, 'Your margin is my opportunity.'" "When you're making too much money, when you are being too extractive, you're actually harming your competitive position in the long run." From his appearance on the show in May.



so far at least, i'm pretty sure AI has been net job-creating. this was not what i expected--although i was much less pessimistic than others, i thought by this level of capability we'd have seen some impact. it is possible this direction keeps going!
