Kiken ретвитнул

Kiken
260 posts





few days into codex plus and i think i found the hack. nobody is talking about it and the value sitting in this subscription is wild. the hack: do not prompt the agent. write a single detailed task doc with every requirement laid out plus the final vision of what you are building, then fire codex cli with one line, accomplish this and test until done. it goes. hours of uninterrupted agentic coding on gpt 5.5 xhigh, no throttling, no rate cap, 'no can you clarify loop'. the agent has everything it needs in one place so it works the problem instead of working you. i have been grinding it since this morning, screenshot below shows the session past 24 mins and still running. anthropic burns through your daily allowance in three opus 4.7 prompts then your entire tier id is gone for the day. codex plus on the same money goes on and on while you go take a walk. this is the most underrated subscription in the agentic stack right now. the value is there if you front-load the prompt instead of conversation-mode it. give codex the brief, walk away, come back to a finished task. try this. loot the value while the math still favors you.

I’m sorry, I know this bums a lot of you out, because you’ve built your personality on being to pro-market, pro-technology guy, but technology is just very clearly making us less happy


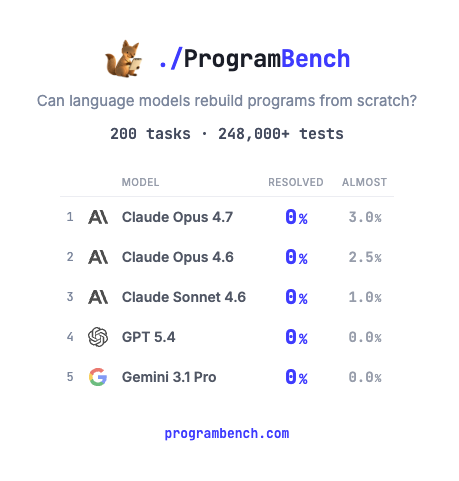
Good interview with Pi agent harness creator Mario Zechner. I like Zechner - no nonsense guy, no hype. AI Agent reality vs hype: Differentiates between good-enough slop code (eg internal use, quickly clean/analyze some data, etc.) vs clean, efficient production code. Zechner: Kimi and DeepSeek are highly effective at coding tasks and represent a strong shift toward using open-weights models. Intelligence and Capacity: notes that models like Kimi (specifically mentioning the 2.6 version) provide intelligence comparable to what he previously received from Anthropic's models, stating that he does not require anything significantly more powerful for his workflows (19:17-19:44). Closing the Gap: Mario argues that open-weights models have caught up to frontier models, to the point where he no longer believes frontier models hold a significant edge in intelligence, specifically noting that he has observed regressions in some verticals for larger models (19:44-20:03).





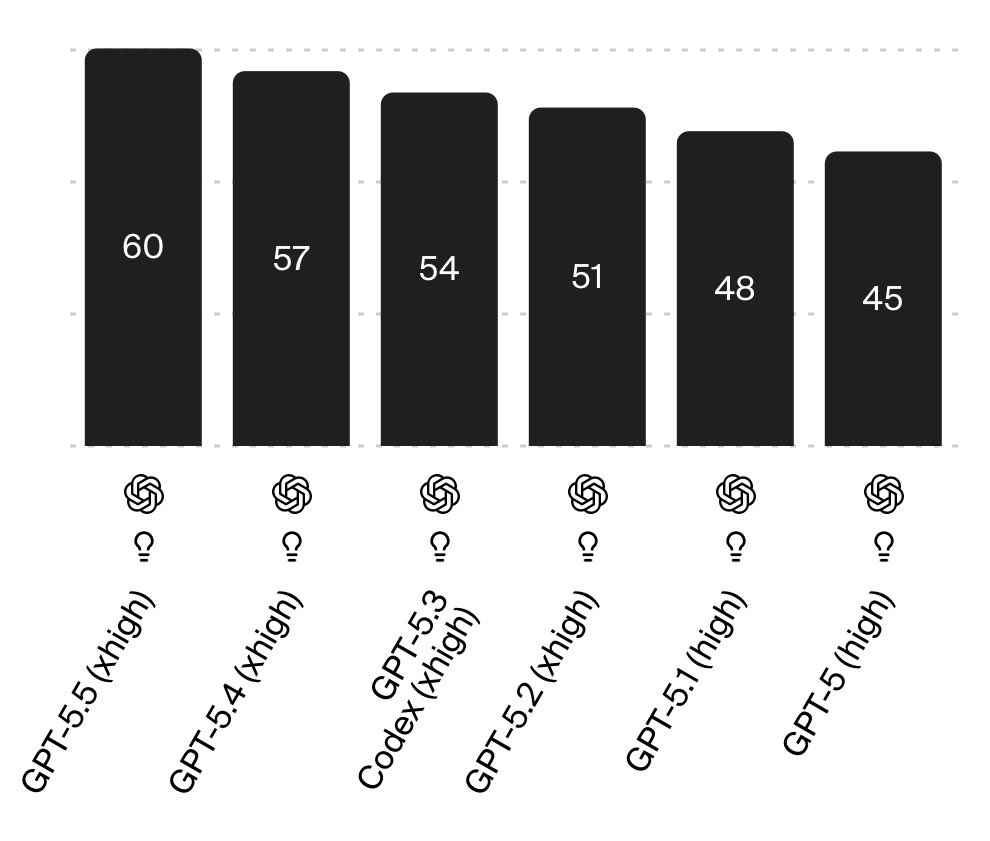
I think returns to intelligence are nonlinear because decisions are path-dependent early choices in code, experiments, or strategy can compound positively or negatively over time for example by avoiding dead ends or preserving optionality it's why I am a big fan of very long running tasks and massive benchmarking budgets GPT-5.5 and Mythos Preview are only marginally more intelligent than previous models and have pretty much the same performance up to 10M tokens, but after that they go absolutely ballistic