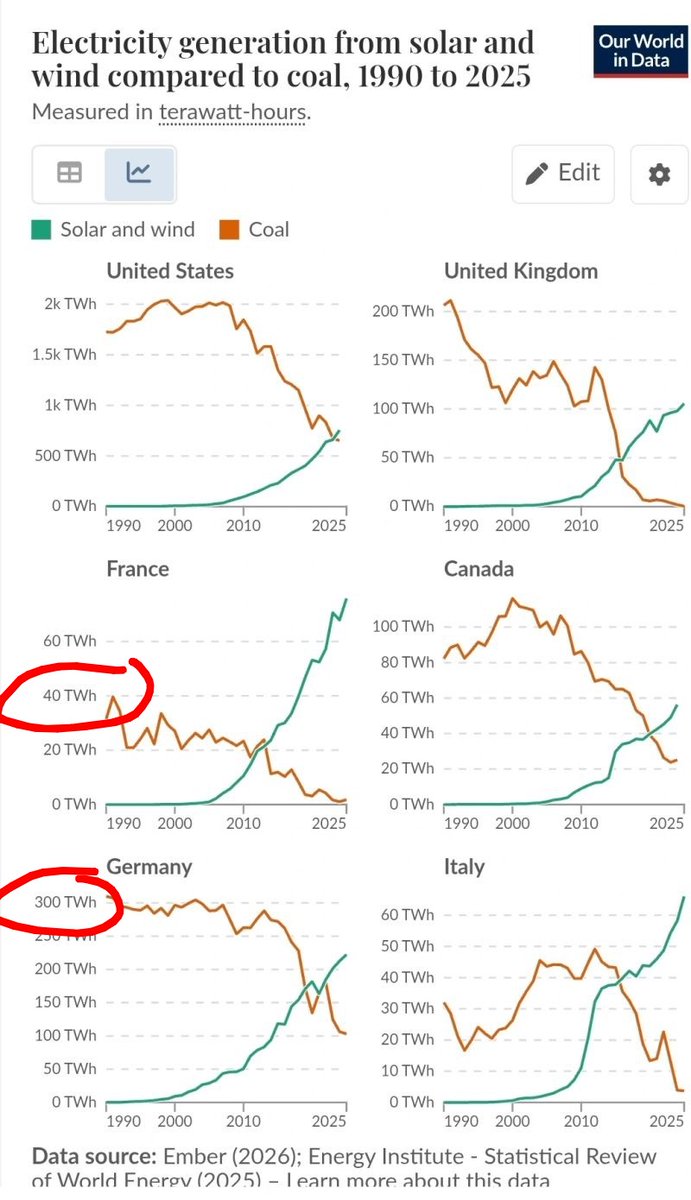
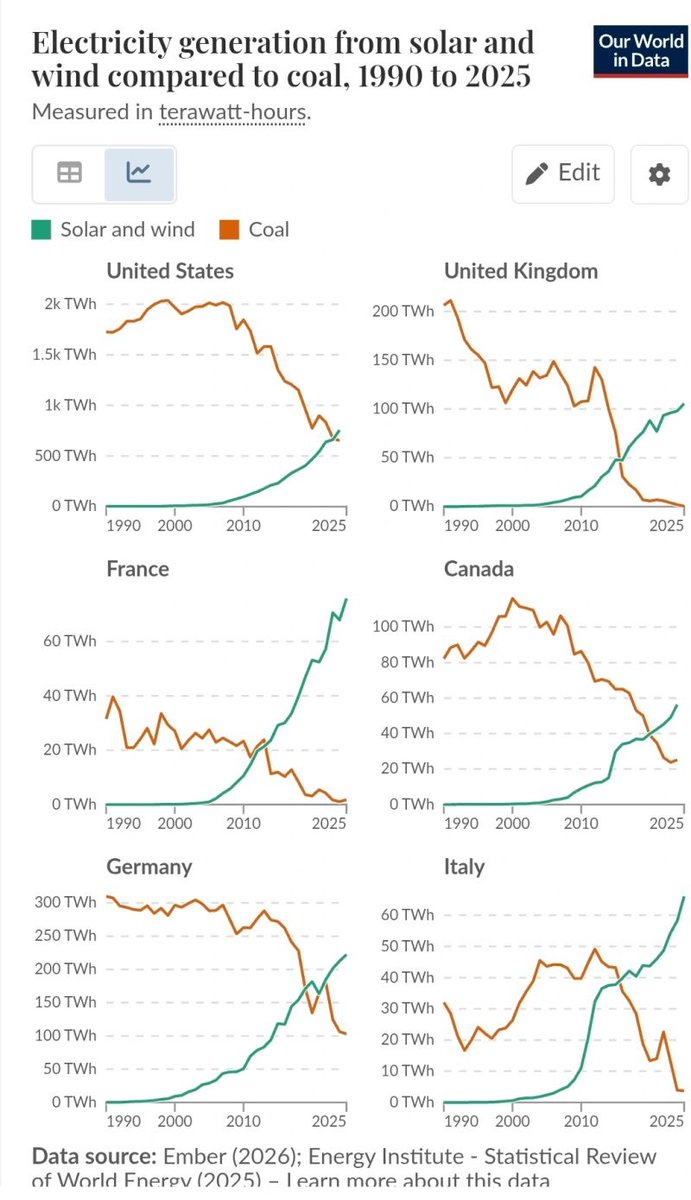
Закреплённый твит

Started to curate a table of small quantum Tanner codes
aleverrier.github.io/qtanner-search…
English
Anthony Leverrier
6.2K posts
@letonyo
researcher on quantum error correction https://t.co/RvavYrCGWD




Both xAI and Meta seem to be falling behind, based on the Grok 4.2 benchmarks and this reporting. Frontier AI models are really a three way race at this point.




If you're looking to buy a Mac Mini, wait 4-6 months, a lot of used Mac Minis in mint condition are about to hit the market

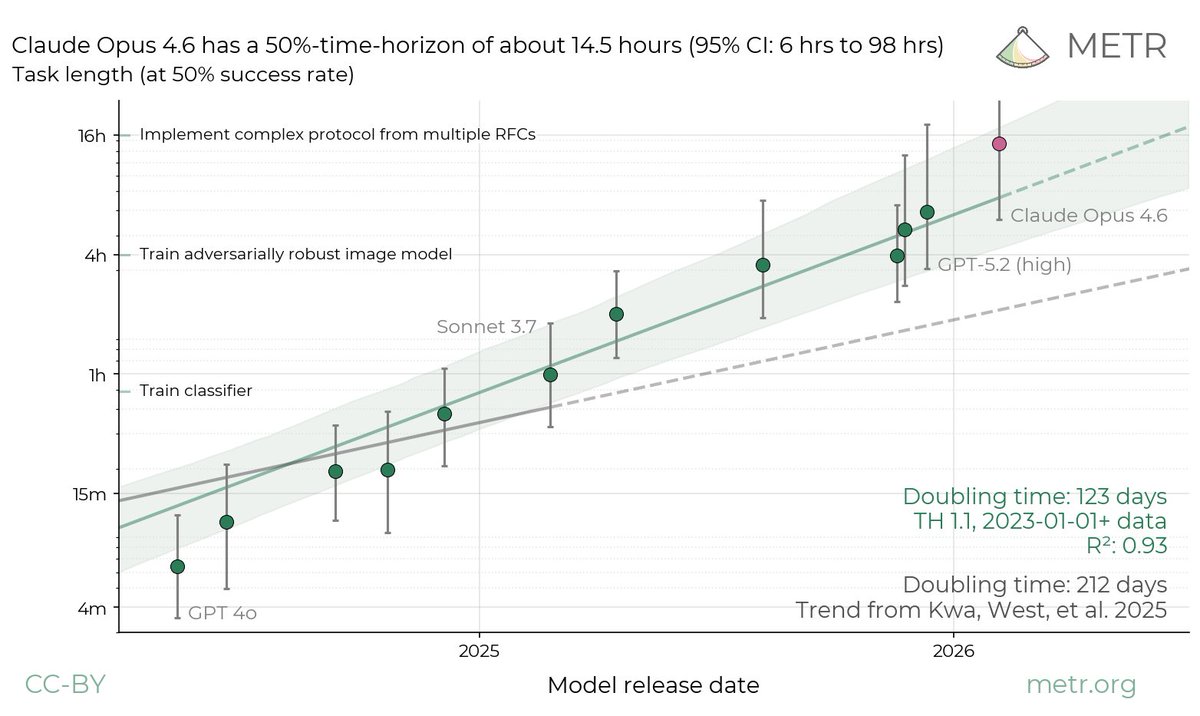

The acceleration is crazy AI is improving faster than ever




Very excited about the "First Proof" challenge. I believe novel frontier research is perhaps the most important way to evaluate capabilities of the next generation of AI models. We have run our internal model with limited human supervision on the ten proposed problems. The problems require expertise in their respective domains and are not easy to verify; based on feedback from experts, we believe at least six solutions (2, 4, 5, 6, 9, 10) have a high chance of being correct, and some further ones look promising. We will only publish the solution attempts after midnight (PT), per the authors' guidance - the sha256 hash of the PDF is d74f090af16fc8a19debf4c1fec11c0975be7d612bd5ae43c24ca939cd272b1a . This was a side-sprint executed in a week mostly by querying one of the models we're currently training; as such, the methodology we employed leaves a lot to be desired. We didn't provide proof ideas or mathematical suggestions to the model during this evaluation; for some solutions, we asked the model to expand upon some proofs, per expert feedback. We also manually facilitated a back-and-forth between this model and ChatGPT for verification, formatting and style. For some problems, we present the best of a few attempts according to human judgement. We are looking forward to more controlled evaluations in the next round! 1stproof.org #1stProof