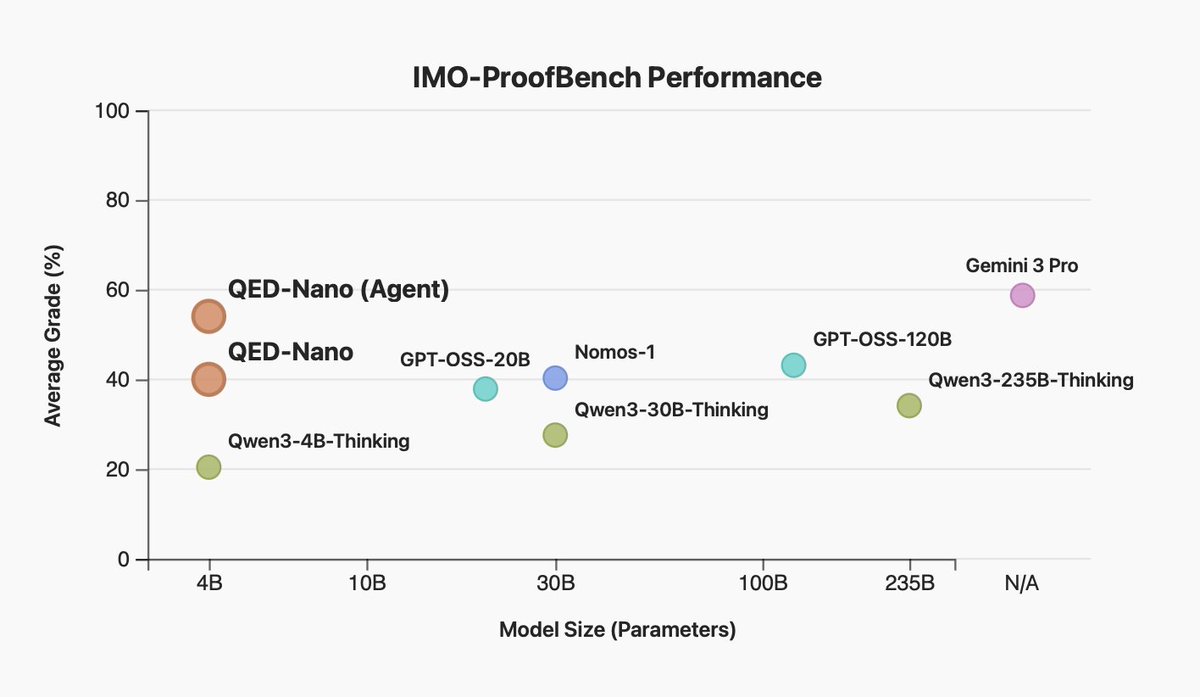
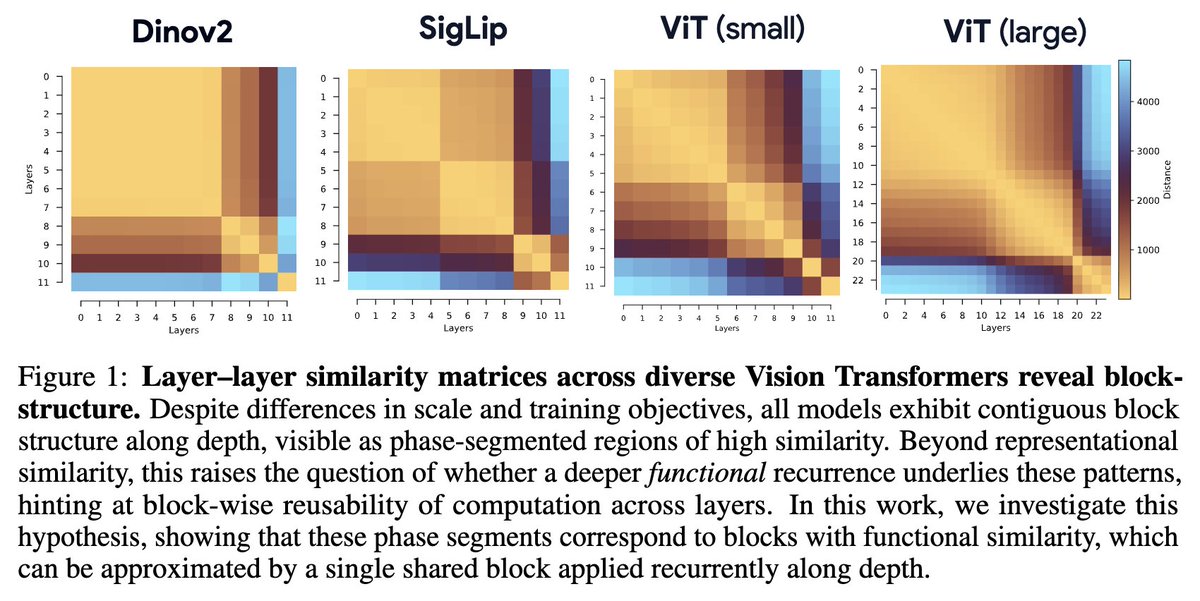
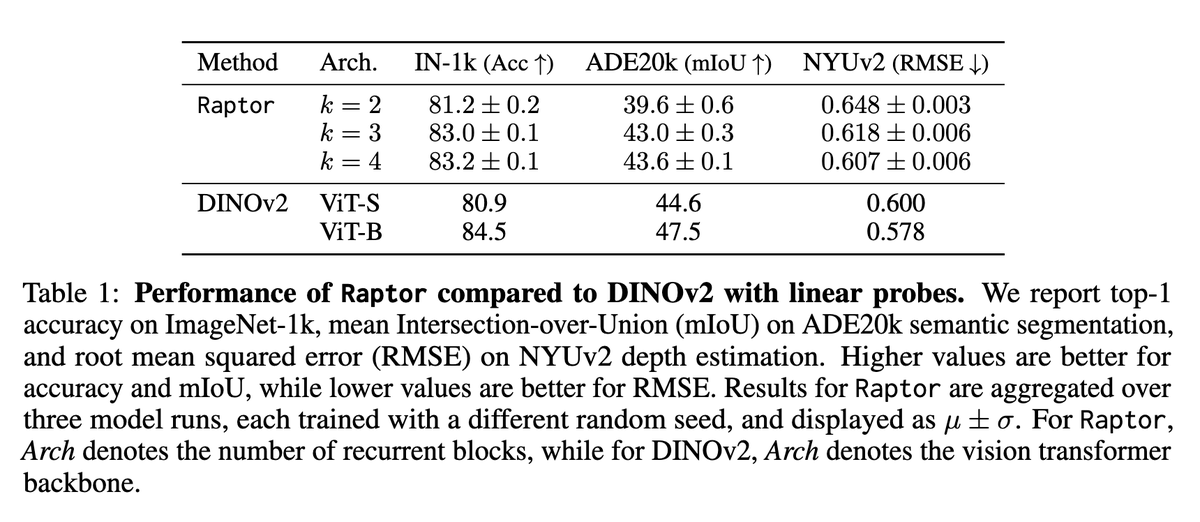
Закреплённый твит

⏰⏰(another) science of robot learning paper. Why does action chunking work so well in robotic manipulation?
Probably lots of reasons. but here’s one you may not have thought of: control stability.
After months of polishing and 5 revisions, check out“ Action Chunking and Exploratory Data Collection Yield Exponential Benefits for Imitation Learning”. The title says it all.
Lead by the eloquent @ThomasTCKZhang , illustrated by the talented @dpfroms , supported by @ChaoyiPan of MIP fame (simchowitzlabpublic.github.io/much-ado-about…) fame, and in collaboration with the one and only @NikolaiMatni .
Thomas Zhang@ThomasTCKZhang
🤖🤖Very excited to finally share our new work “Action Chunking and Exploratory Data Collection Yield Exponential Improvements in Behavior Cloning for Continuous Control” Everyone in robotics does action-chunking, but why does it actually work?🤔🤔And, what can theory tell us about the properties of data we should be collecting for robotic behavior cloning? 🧵1/N
English