Sabitlenmiş Tweet

As a PhD student, I was told not to work on deep RL - too full of hacks and alchemy" But after a year or two of working in this area, I’ve come to (deeply?) appreciate all of the thoughtful research that’s gone into understanding what/why things work and how to make them better.
My lab (joint with @abhishekunique7) took what we’ve learned by reading this body of literature to answer the question: what are the actual best-practices for finetuning a diffusion/flow/generative robot policy (for now, in sim)? Under one set of constraints - ample compute but limited time on your robot - @servo97 paper gives a pretty compelling answer.
Sarvesh Patil@servo97
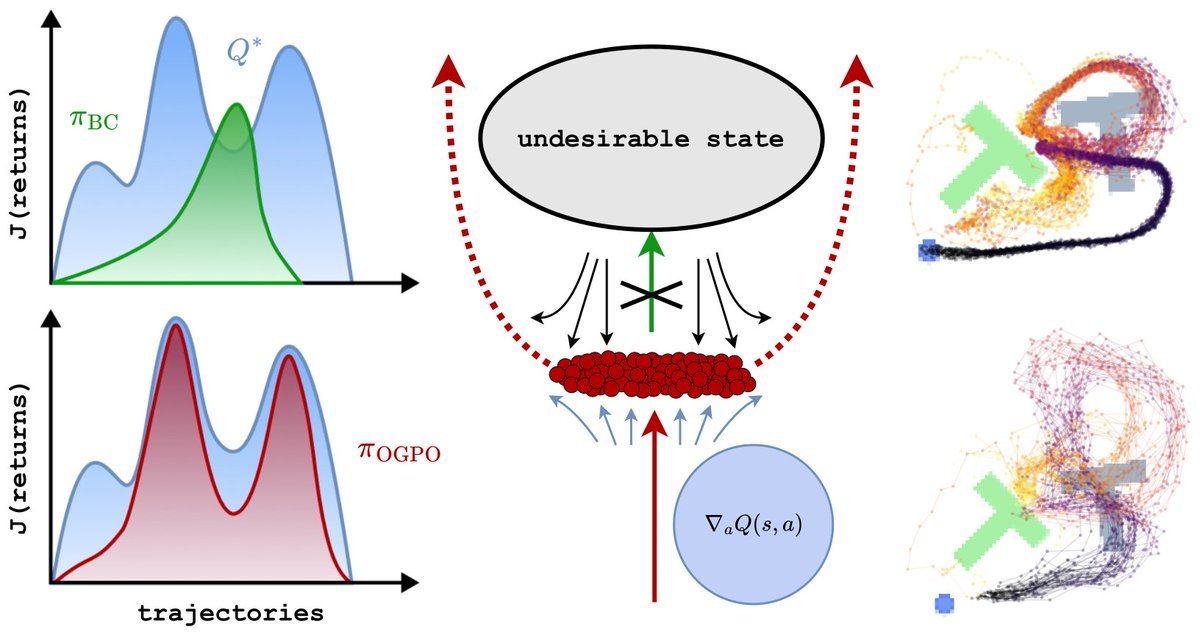
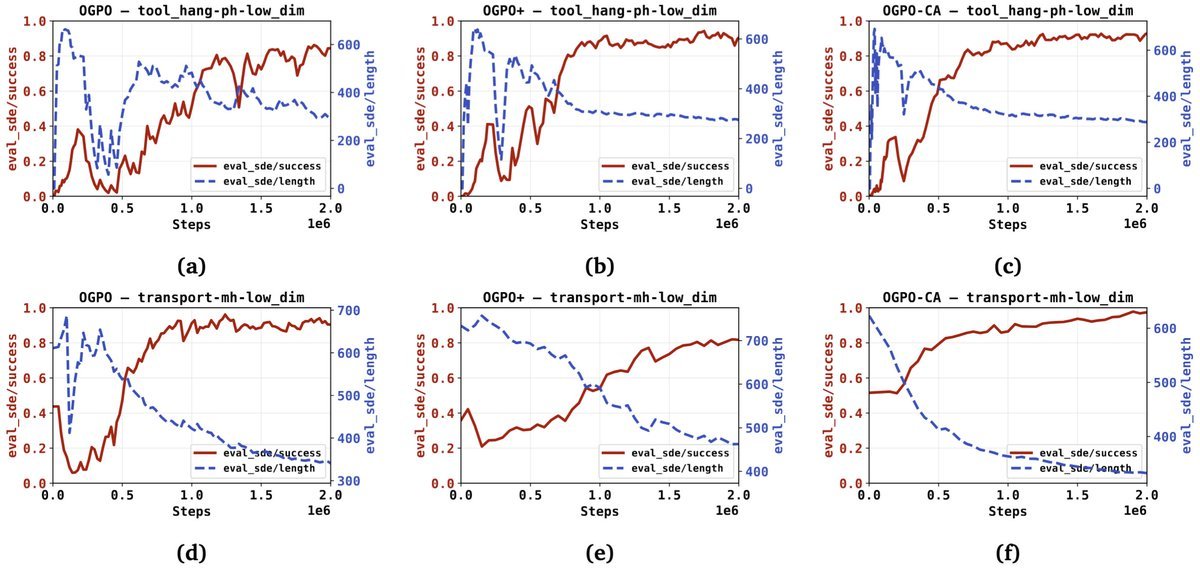
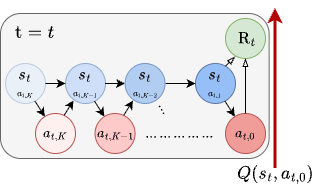
Interaction with the real world is the major bottleneck in robot learning. So what would robot RL look like if we didn’t need to limit compute per interaction? Our latest work, Off-Policy Generative Policy Optimization (OGPO, accepted to ICML26) embarks on answering this question (spoiler alert: when done correctly, it helps massively!). 🧵(1/N)
English