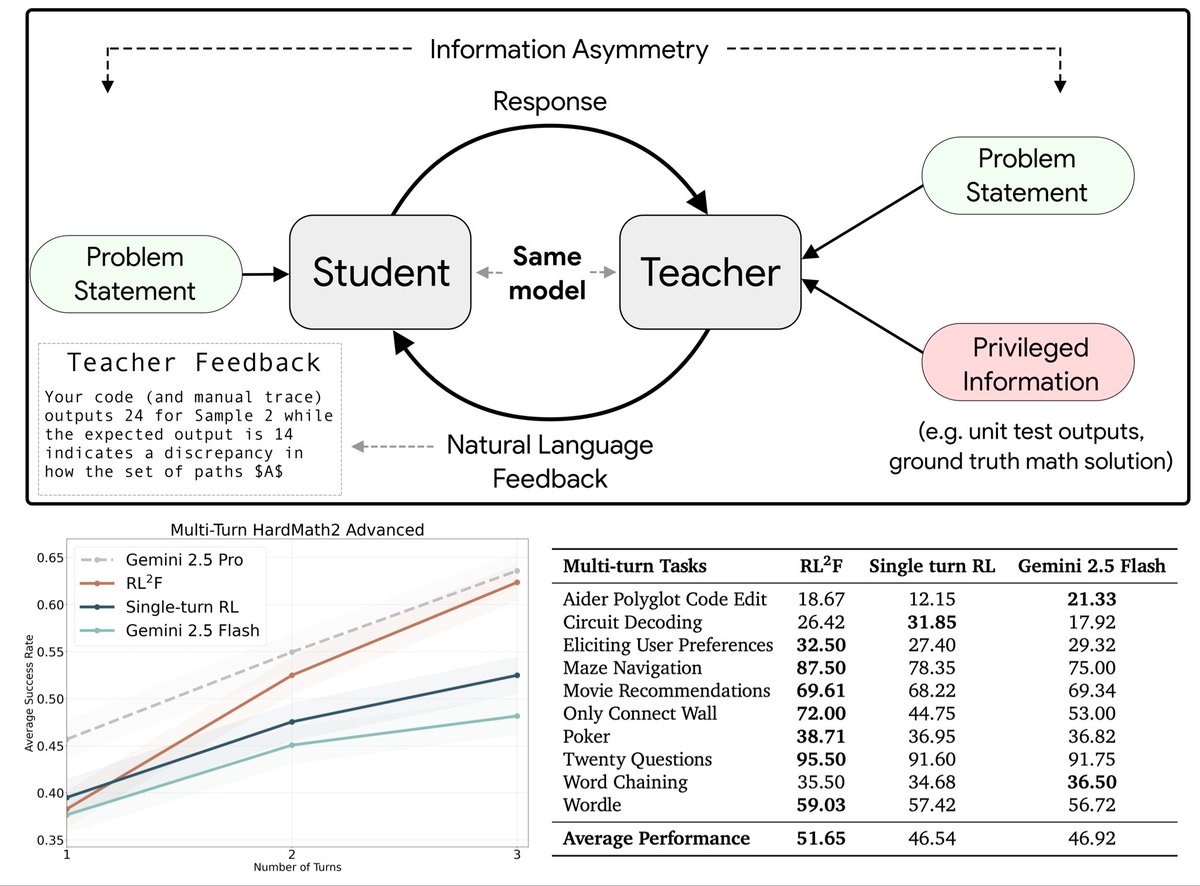
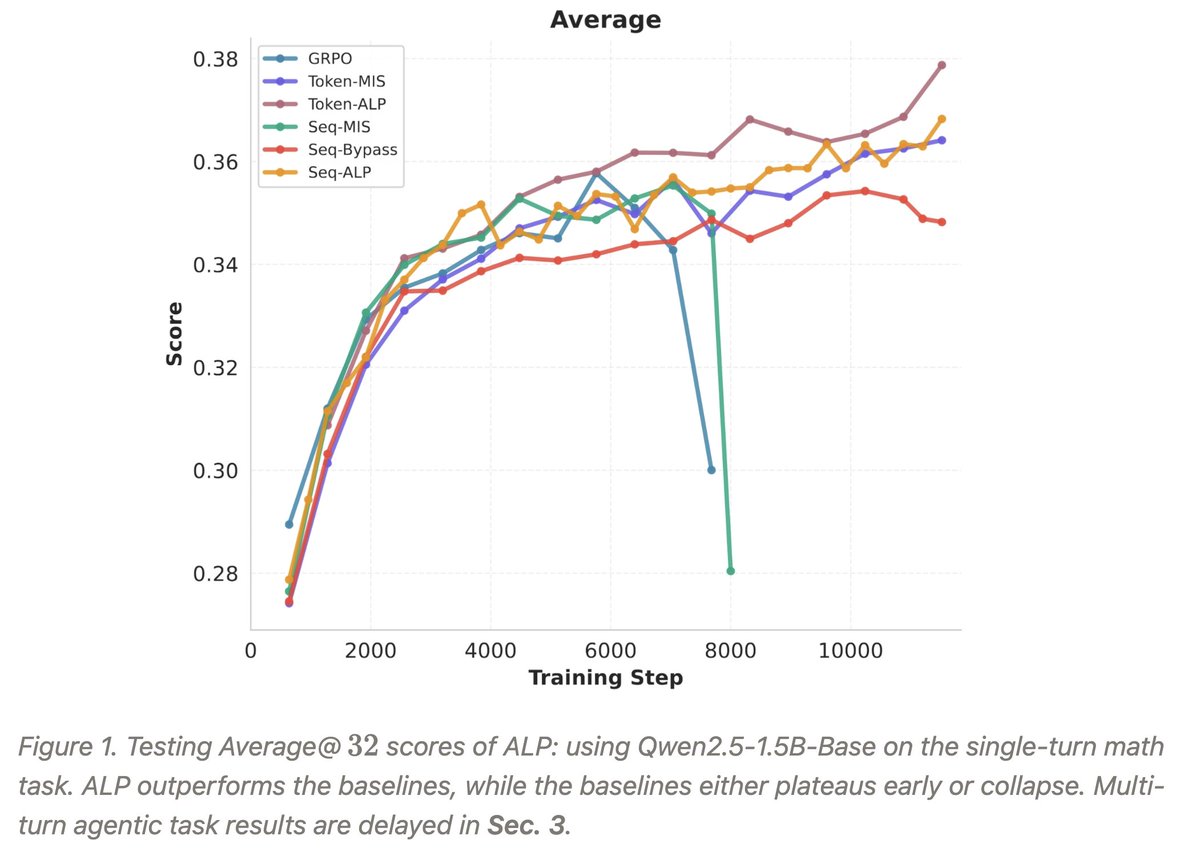
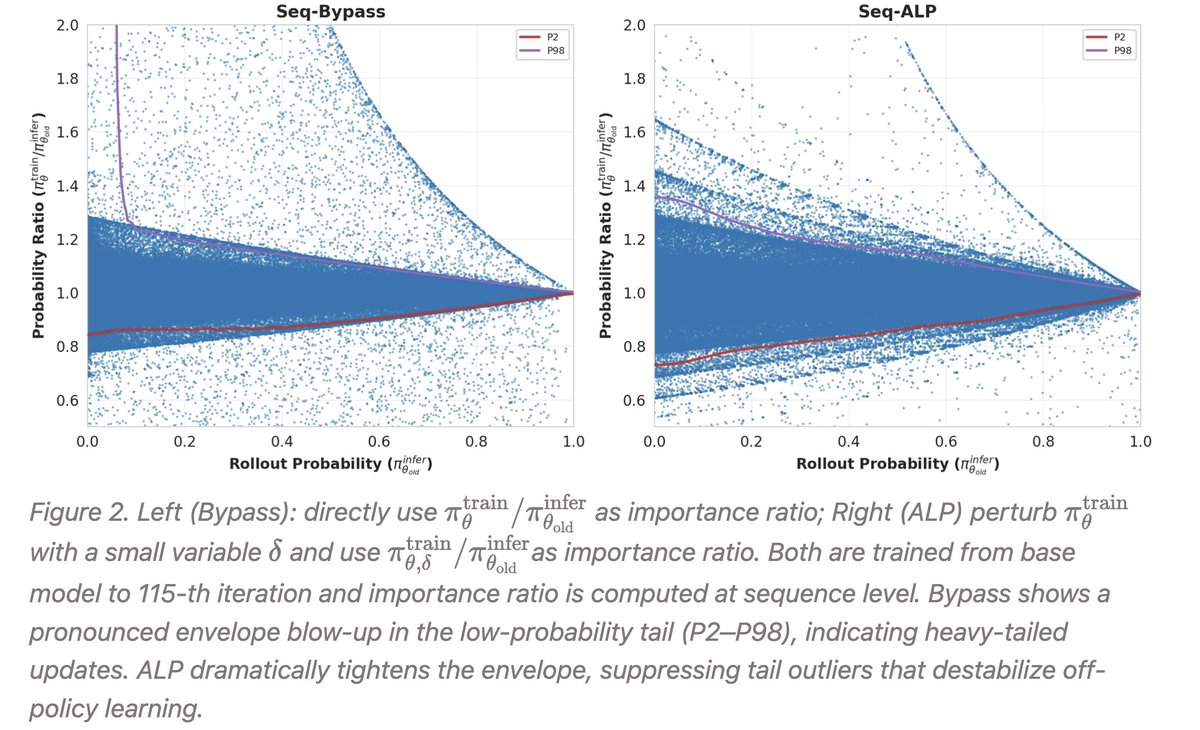
Закреплённый твит

Welcome Gemma 3, our new open-weight LLM from @GoogleDeepMind. All sizes (1B, 4B, 12B and 27B) excel on benchmarks, but the key result may be the 27B reaching 1338 on LMSYS. For this, we scaled post-training, with our novel distillation, RL and merging strategies. Happy building!

English