Закреплённый твит

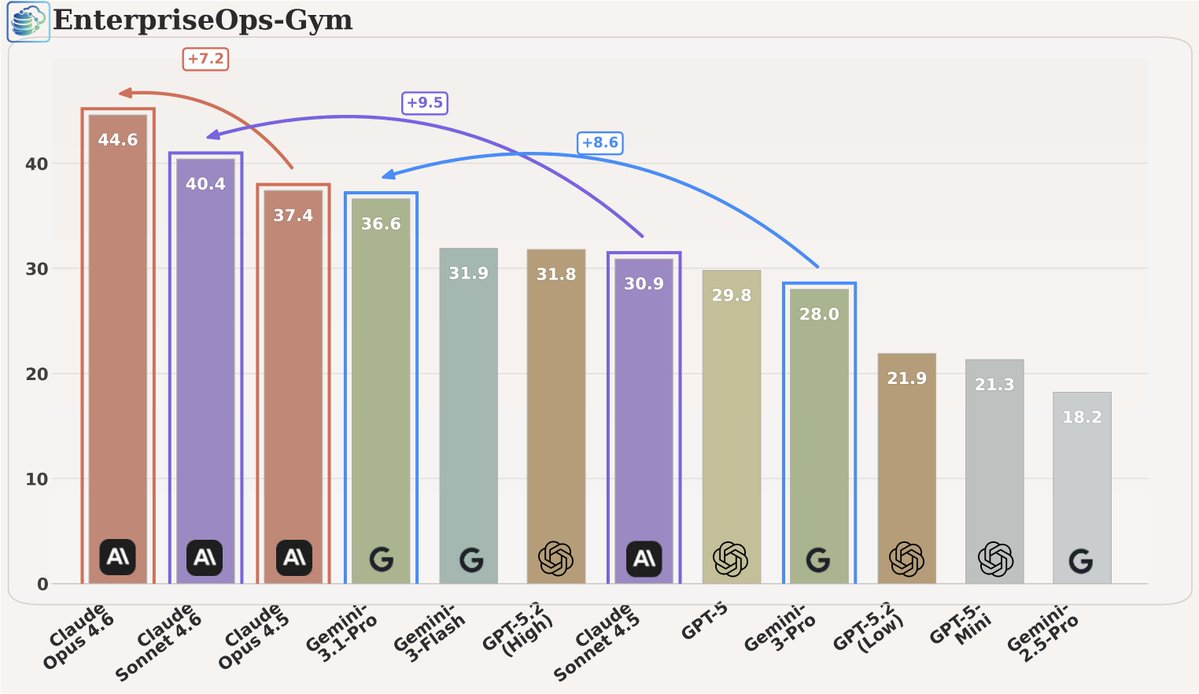
Case Study: Most AI agent evals are flawed.
They measure outputs. Real agents operate across 80–200+ actions, tools, and OS environments where failure is gradual, not binary.
At Turing, we built a new evaluation framework:
-900+ deterministic tasks
-450+ parent–child pairs
-1800+ evaluable scenarios via prompt–execution swapping
• 6 domains, balanced across Windows, macOS, Linux
• 40% open-source, 60% closed-source tools
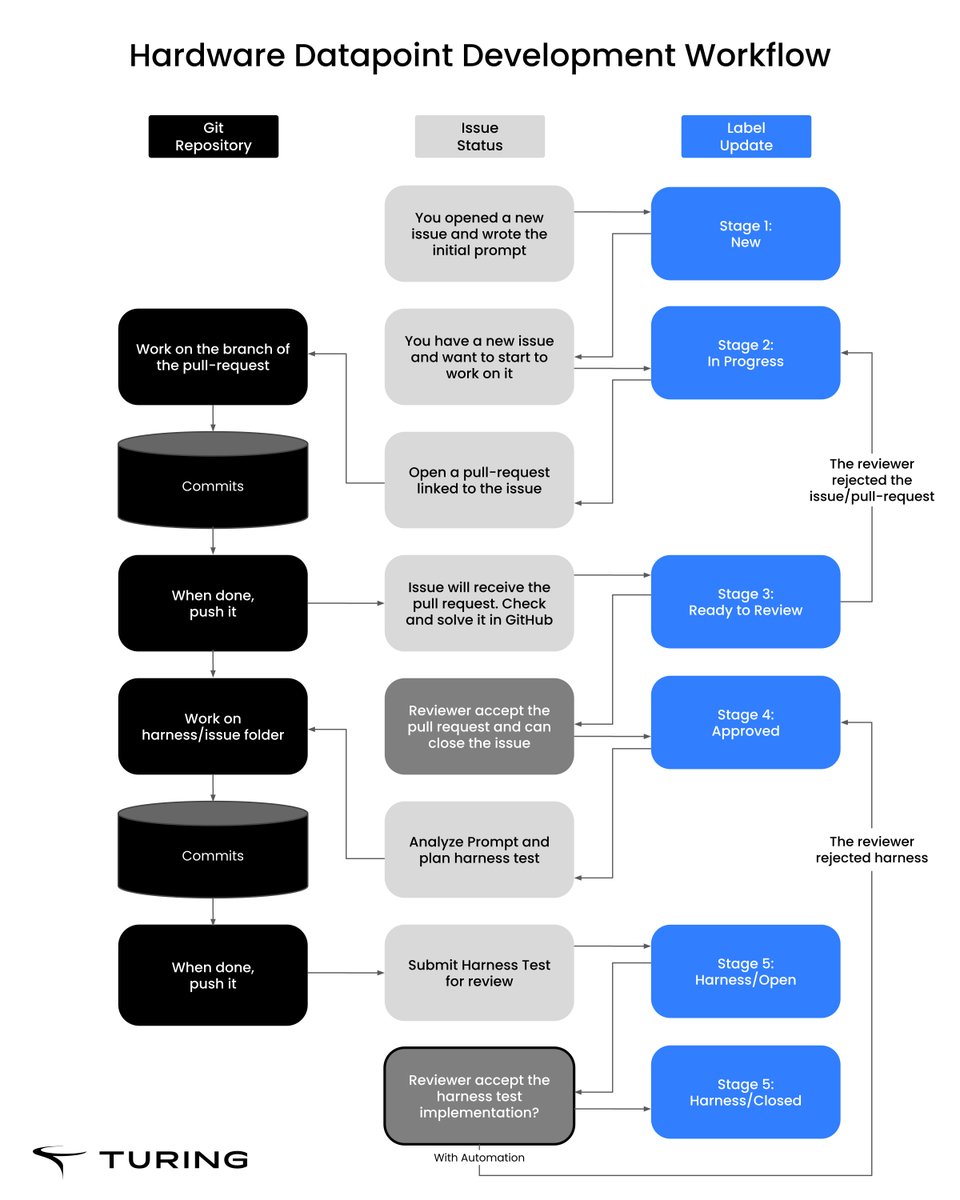
Each task includes full telemetry:
-screen recordings
-event logs (clicks, keystrokes, scrolls)
-timestamped screenshots
-structured prompts, subtasks, and metadata
The key idea: structured failure.
Instead of injecting errors, we create them by swapping execution and intent:
-Parent prompt + Child execution
-Child prompt + Parent execution
This produces controlled, classifiable failures:
-Critical mistake
-Bad side effect
-Instruction misunderstanding
With calibrated complexity (80–225 actions) and strict QA, this becomes a fully reproducible benchmark.
Result:
We can measure not just if agents succeed, but:
-where they break
-how errors propagate
-how robust they are across real environments
Agents don’t fail at the answer. They fail in the process.
Read more case studies below.
English