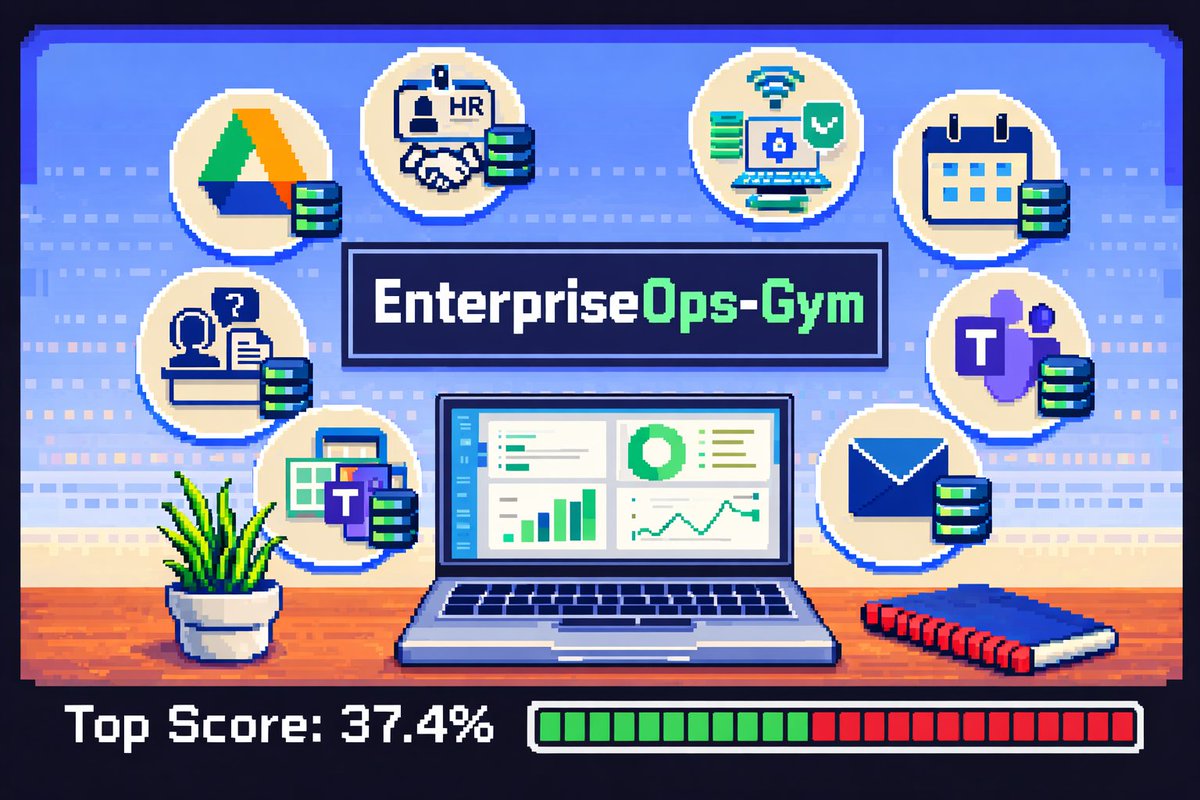


🔥 𝗘𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲𝗢𝗽𝘀-𝗚𝘆𝗺 𝗶𝘀 𝘁𝗮𝗸𝗶𝗻𝗴 𝗼𝗳𝗳 𝗵𝘂𝗴𝗲: 2K downloads in 3 days (trending #6 dataset + #3 paper of the day) 🏆. So we re-ran the leaderboard on the 𝗹𝗮𝘁𝗲𝘀𝘁 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗰𝗹𝗼𝘀𝗲𝗱 𝗺𝗼𝗱𝗲𝗹𝘀… and the results were promising. ✅ Claude versions show a meaningful jump in reliability on enterprise tasks. ✅ Gemini 3.1 Pro is catching up fast, now much closer to Sonnet 4.6 than earlier releases. And yet, the bigger takeaway is still the same: - Big room for improvement on enterprise-grade agentic tasks. - These workflows punish "seemingly correct." One wrong default, one policy miss, one unintended side effect.. and the task fails. 📢 𝗖𝗮𝗹𝗹𝗼𝘂𝘁 (especially if you’re working on agents): As we prepare our next NeurIPS/COLM submissions, try your agents on EnterpriseOps-Gym and see how they hold up on realistic, policy-constrained, long-horizon tasks. 🌐 Website: enterpriseops-gym.github.io 🤗 Dataset: huggingface.co/datasets/Servi… @ServiceNowRSRCH , @sagardavasam , @turingcom , @turingcomdev , @Mila_Quebec , @shiva_malay @PShravannayak