Закреплённый твит

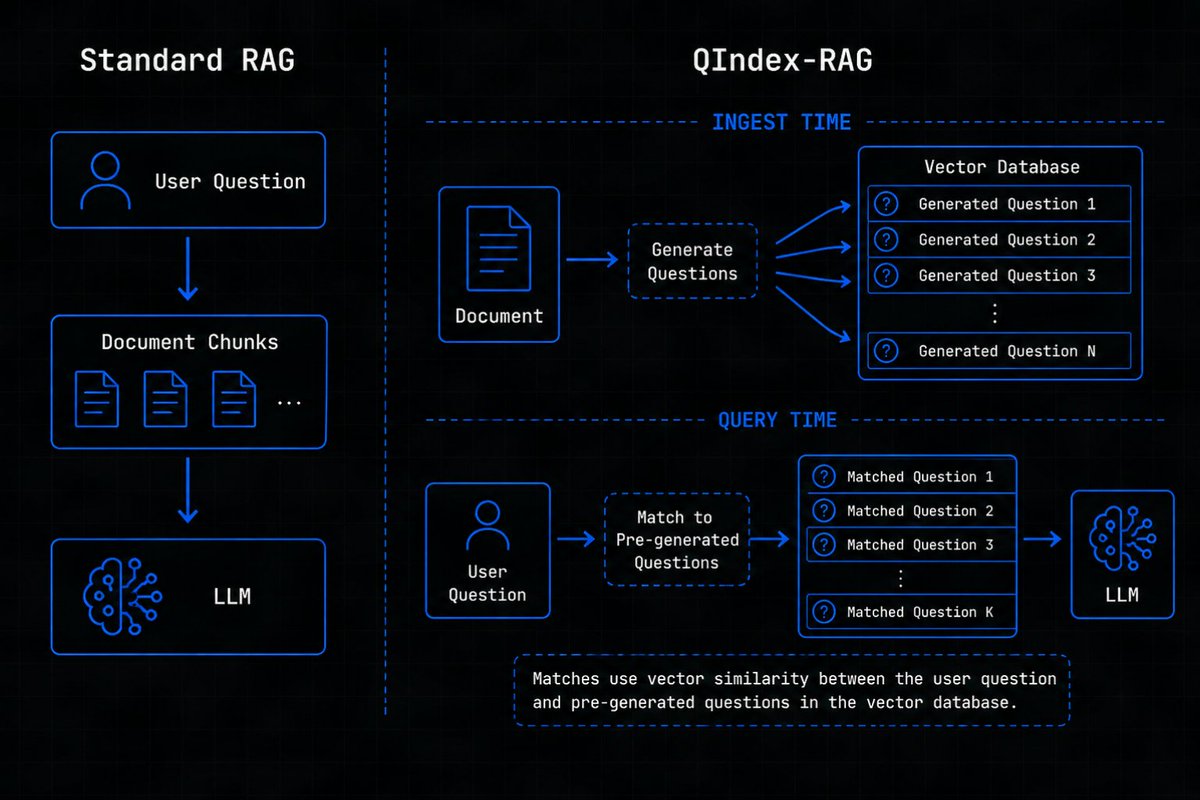
Most RAG systems work like this:
→ User asks question
→ Retrieve similar chunks
→ Send to LLM
→ Generate answer
The problem: question-to-chunk similarity is often weak.
Example: “How do I reset my password?”
That may not semantically match a documentation paragraph talking about authentication flows, account settings, or credential recovery.
So I’m experimenting with a different retrieval approach:
At ingest time: generate possible questions each page can answer.
At query time: match question-to-question instead of question-to-chunk.
Early results:
→ significantly better retrieval relevance
→ fewer unnecessary tokens sent to the LLM
→ much cleaner context windows
Calling this approach: QIndex-RAG.
Still testing and refining it, but the retrieval quality improvement is already noticeable.
English