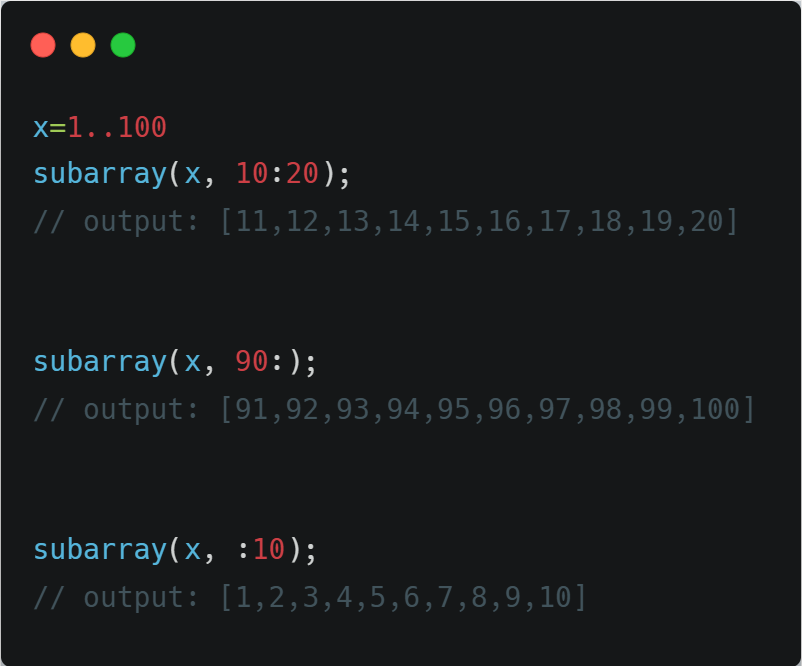
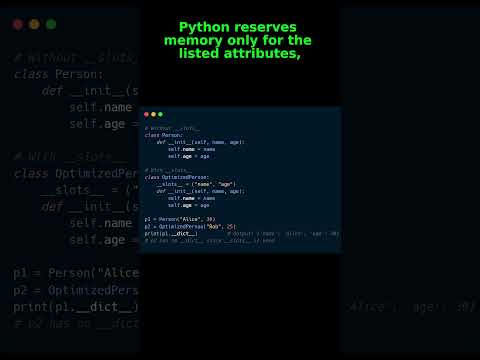
Δ-Mem isn't just another tweak, it's a leap for large language models. Expect a boost in efficiency and broader task adaptability. Optimizing memory has never been this crucial. Keep your infrastructure ready. #AI #MemoryOptimization

English
Arama Sonuçları: "#memoryoptimization"
20 sonuç


Just implemented Google’s TurboQuant in MLX and the results are wild! Needle-in-a-haystack using Qwen3.5-35B-A3B across 8.5K, 32.7K, and 64.2K context lengths: → 6/6 exact match at every quant level → TurboQuant 2.5-bit: 4.9x smaller KV cache → TurboQuant 3.5-bit: 3.8x smaller KV cache The best part: Zero accuracy loss compared to full KV cache.