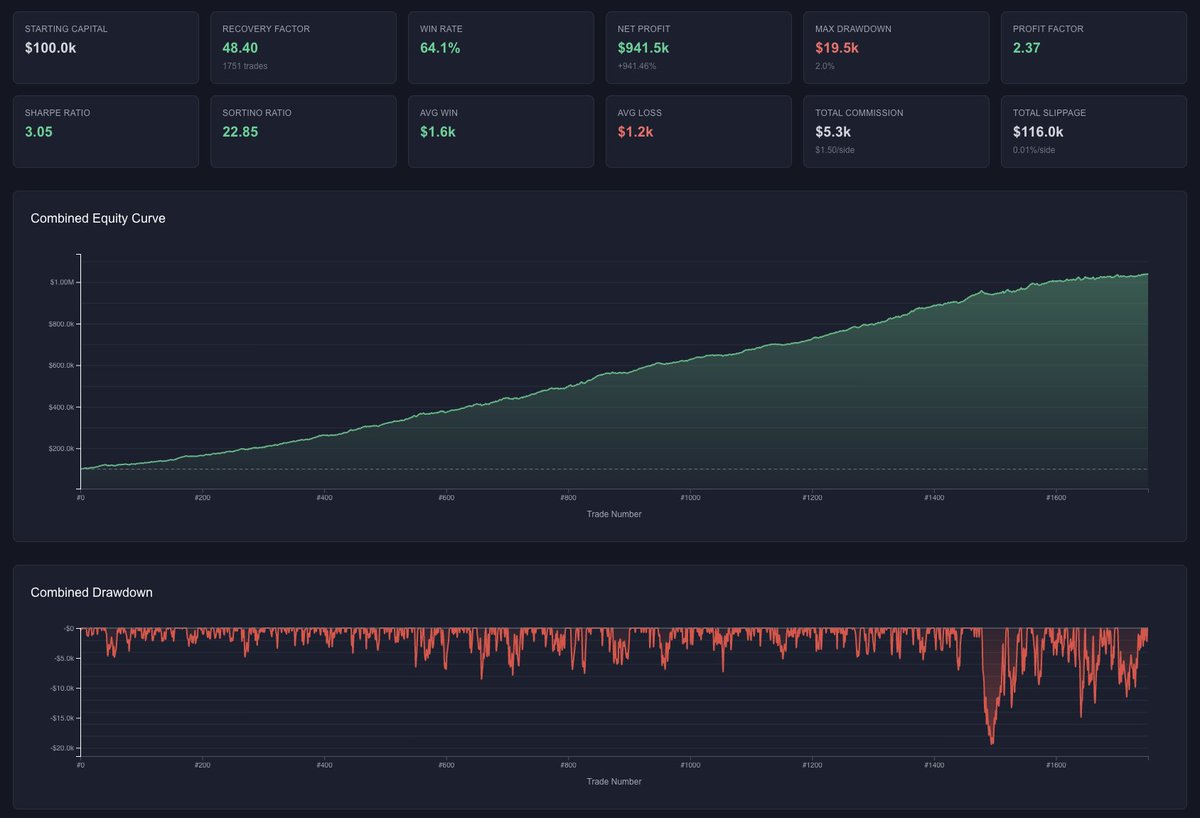
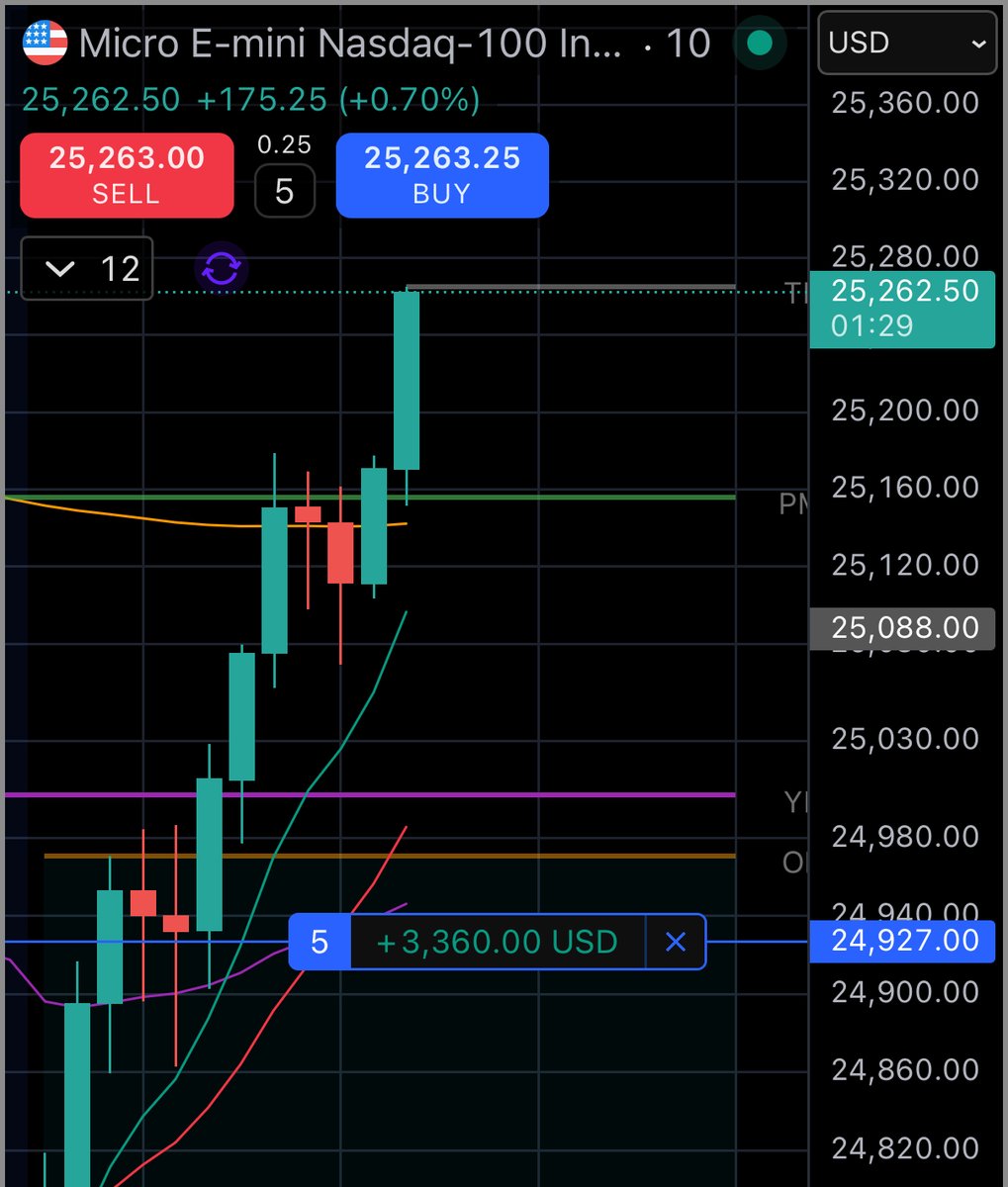
@yuriymatso How is your performance during the period Oct-25 to dec-25? Is where I find most of my models taking the bigger DD..
English
Álvaro Tejeda
1.1K posts

@ATL_85
https://t.co/VxowRGiEdz - Finance, Data Science, AI, Recommender systems, Gaming, iGaming..