ทวีตที่ปักหมุด

Language models that think, chat better.
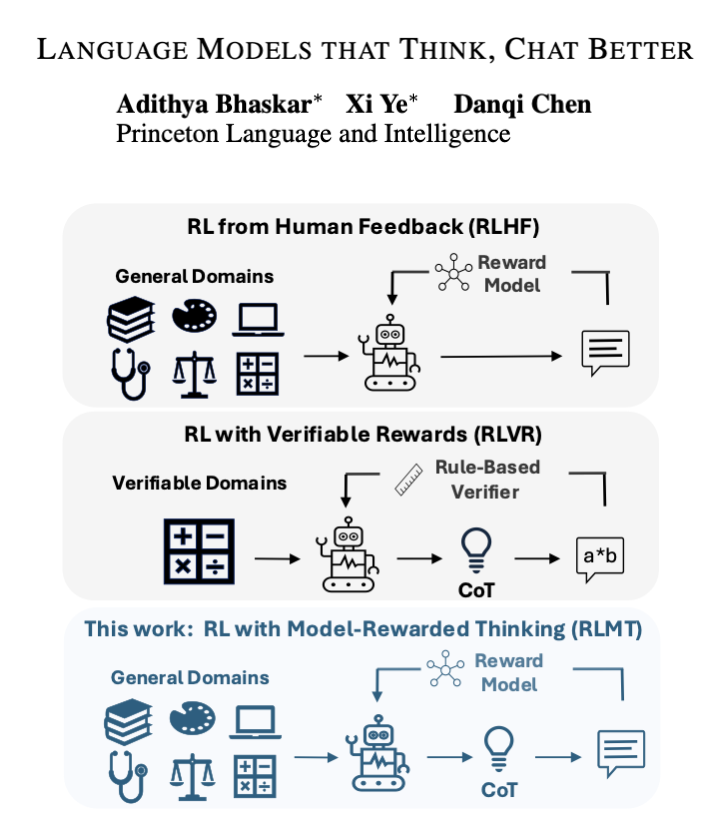
We used longCoT (w/ reward model) for RLHF instead of math, and it just works. Llama-3.1-8B-Instruct + 14K ex beats GPT-4o (!) on chat & creative writing, & even Claude-3.7-Sonnet (thinking) on AlpacaEval2 and WildBench!
Read on. 🧵
1/8
English