ทวีตที่ปักหมุด

To do:
1. Write a screenplay
2. Launch an app
3. Make a film
English
Aswin Manohar
5.4K posts
@Aswin_polymath
ex-astrophysicist | data scientist & MLE | seeking meaning through creative exploration | I write about humans, ai, tech, films, art & philosophy








somehow skills are still underrated



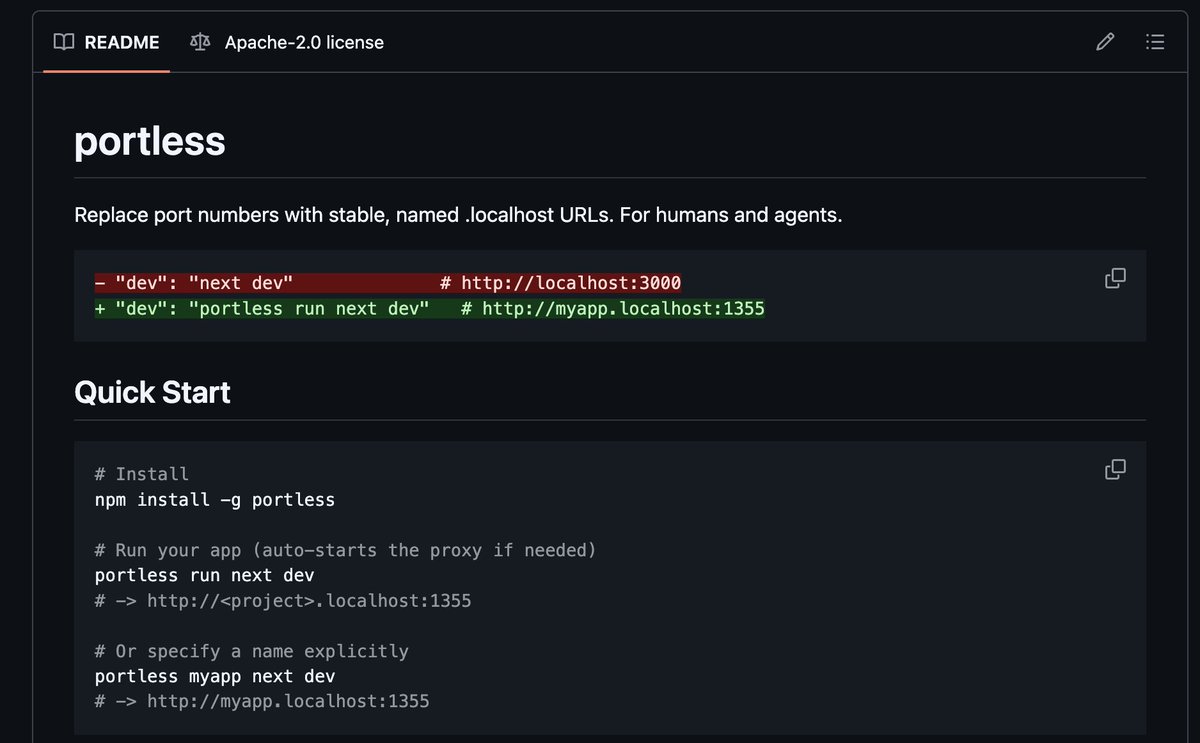

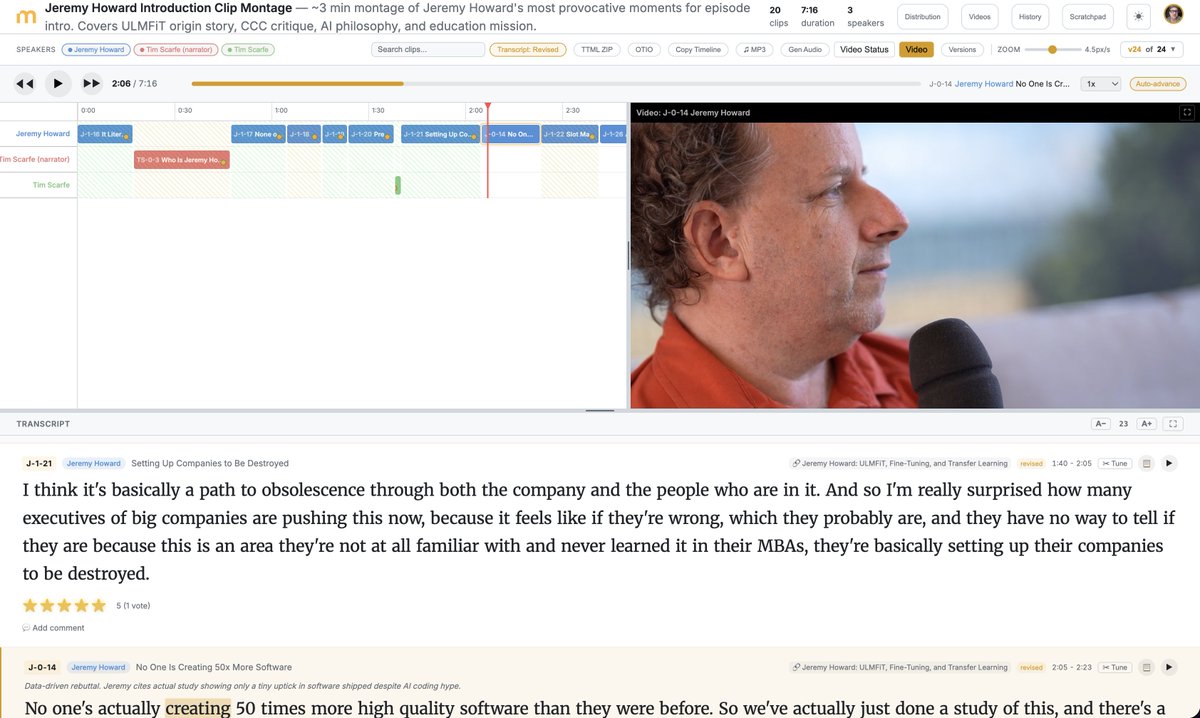


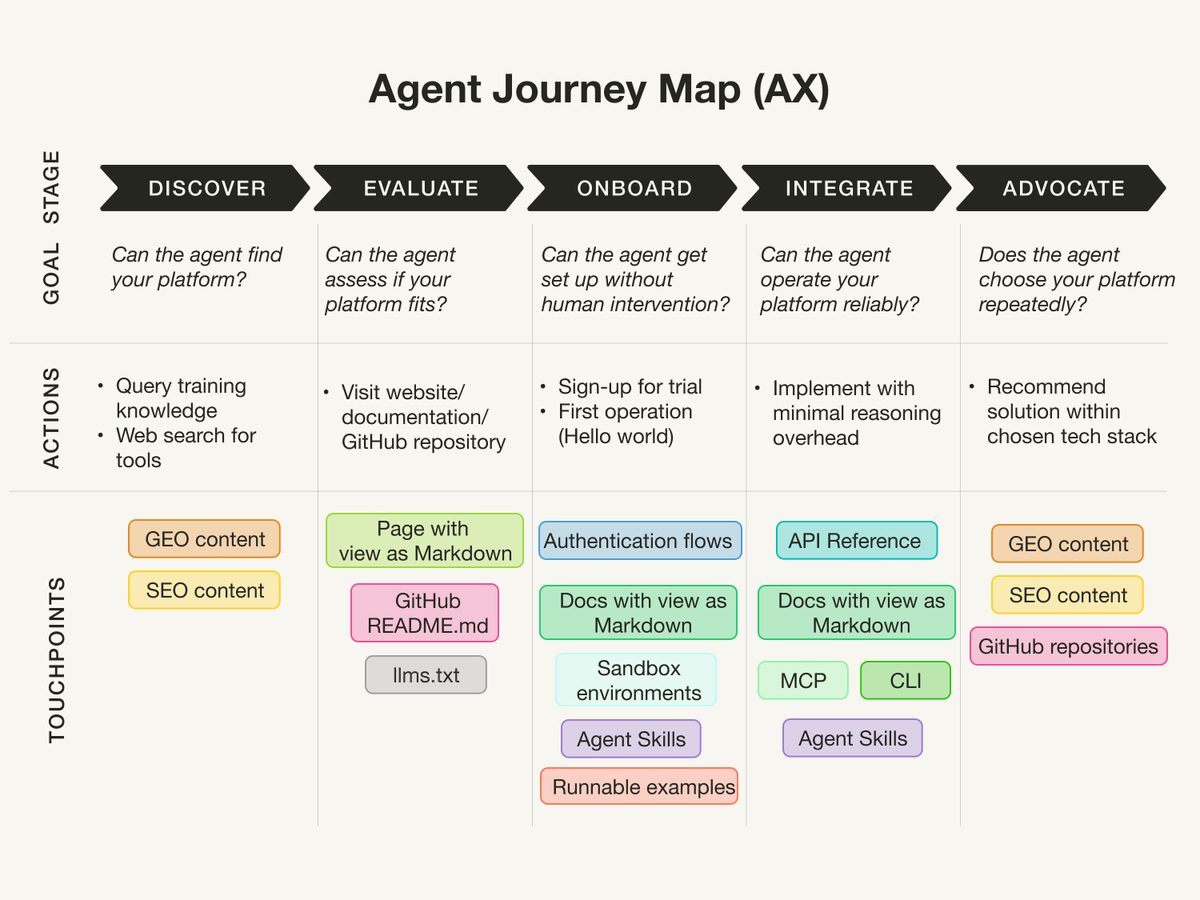
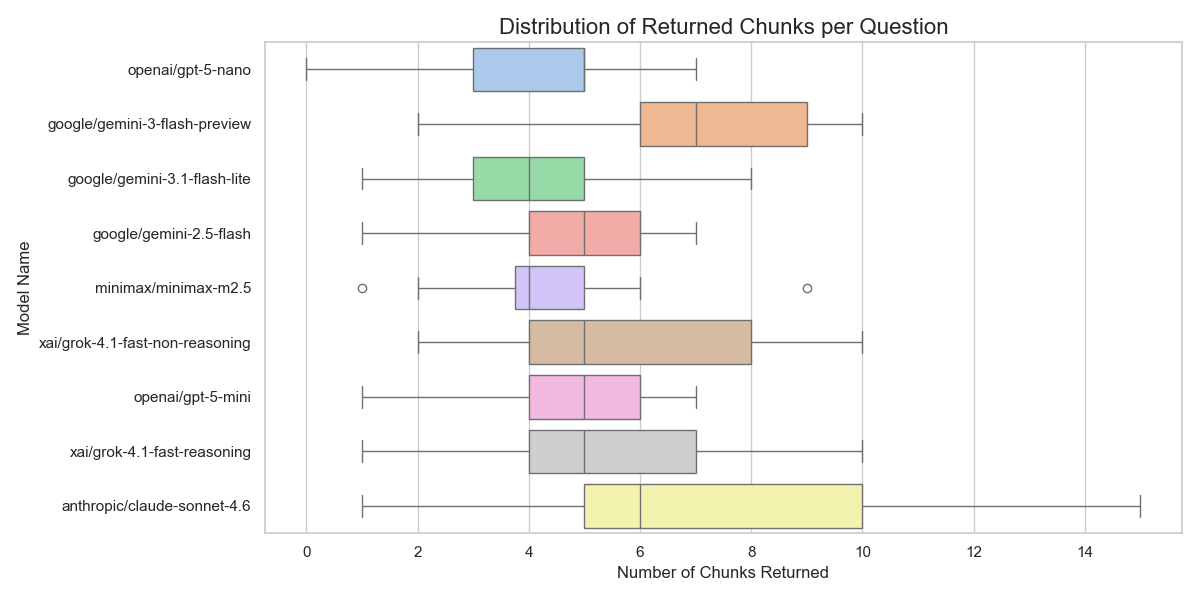
Interesting benchmark on which model is best for @openclaw pinchbench.com

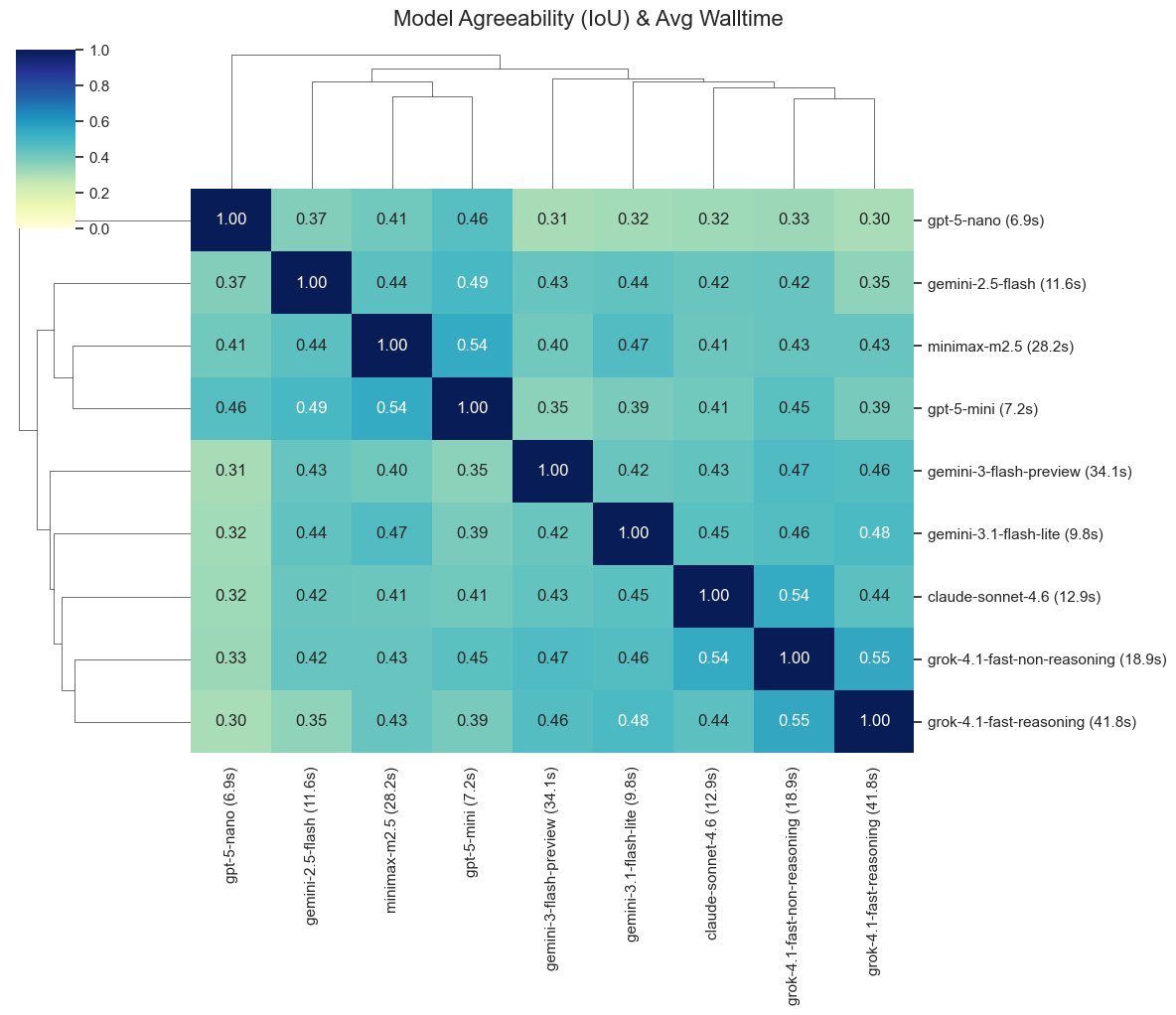
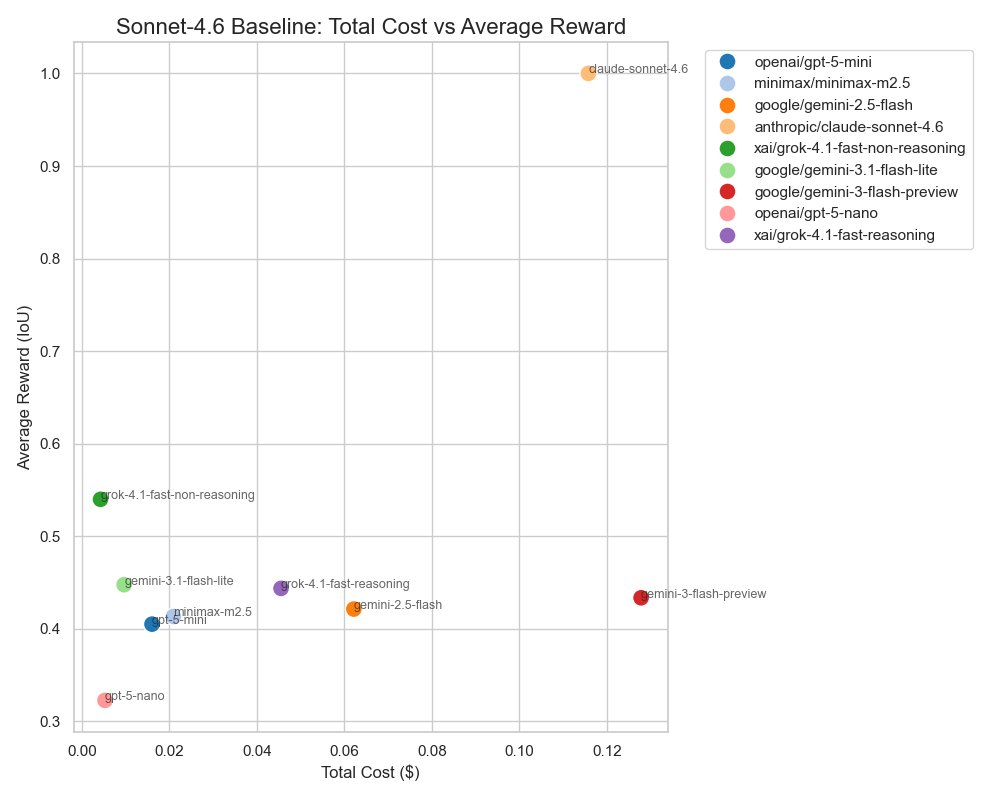
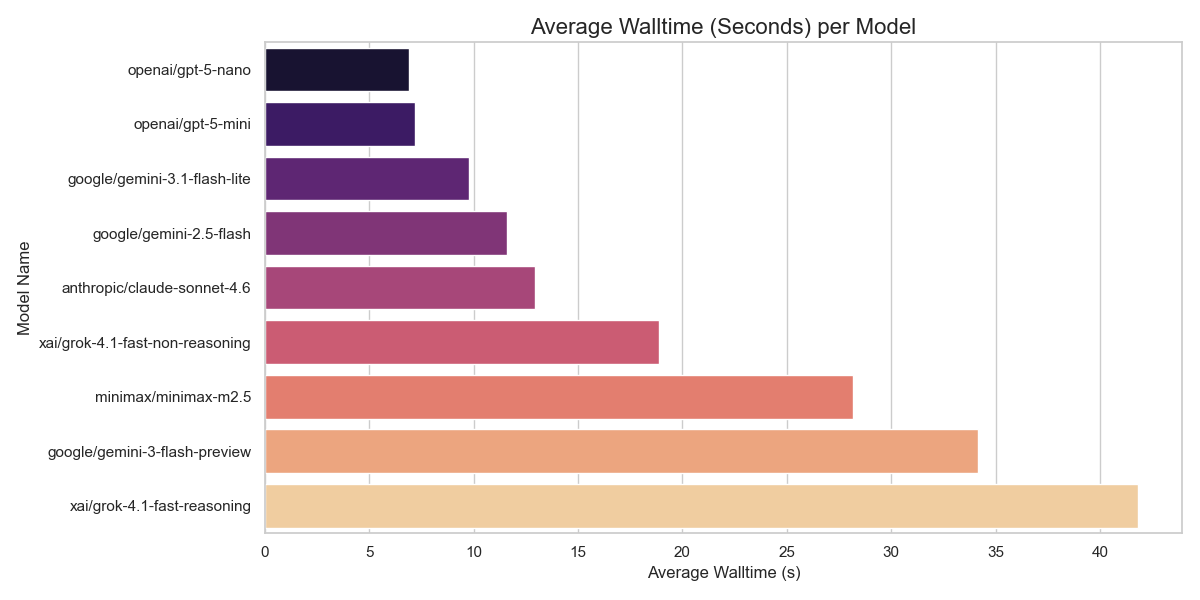
I really like the Prime RL school of thinking - "environments & evals are two sides of the same coin" So today I'll convert Paper Breakdown into an RL env. I'll run evals with smaller models to check if I can cut my inference bill without sacrificing rewards.



Meet KARL: a faster agent for enterprise knowledge, powered by custom reinforcement learning (now in preview). Enterprise knowledge work isn’t just Q&A. Agents need to search for documents, find facts, cross-reference information, and reason over dozens or hundreds of steps. KARL (Knowledge Agent via Reinforcement Learning) was built to handle this full spectrum of grounded reasoning tasks. The result: frontier-level performance on complex knowledge workloads at a fraction of the cost and latency of leading proprietary models. These advances are already making their way into Agent Bricks, improving how knowledge agents reason over enterprise data. And Databricks customers can apply the same reinforcement learning techniques used to train KARL to build custom agents for their own enterprise use cases. Read the research → databricks.com/sites/default/… Blog: databricks.com/blog/meet-karl…