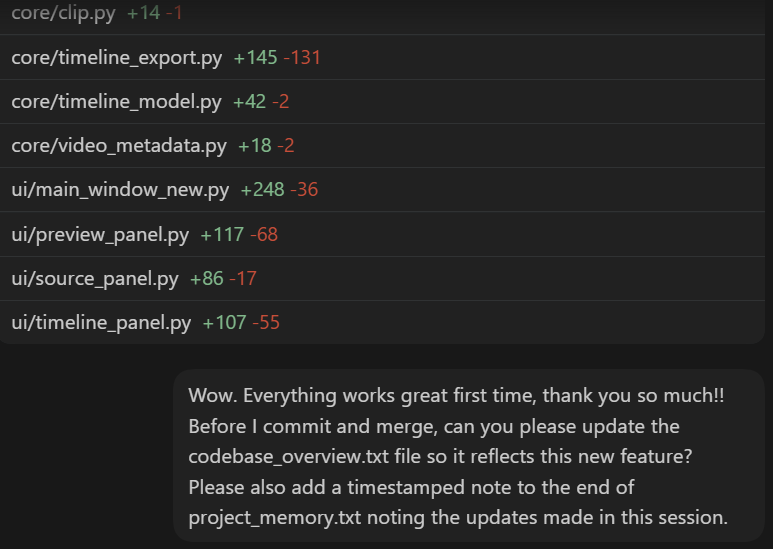
I'm still hard-wired from past painful experiences to panic whenever the Codex context window exceeds 50%, but I've encountered a couple of times in the past week where compaction was unavoidable and I was shocked that the quality didn't degrade. So whatever Open AI have done is impressive.
I can't imagine this problem will ever fully be solved through compaction alone because data loss is data loss, but the better this gets the more it opens up opportunities for monster long-running tasks.
English