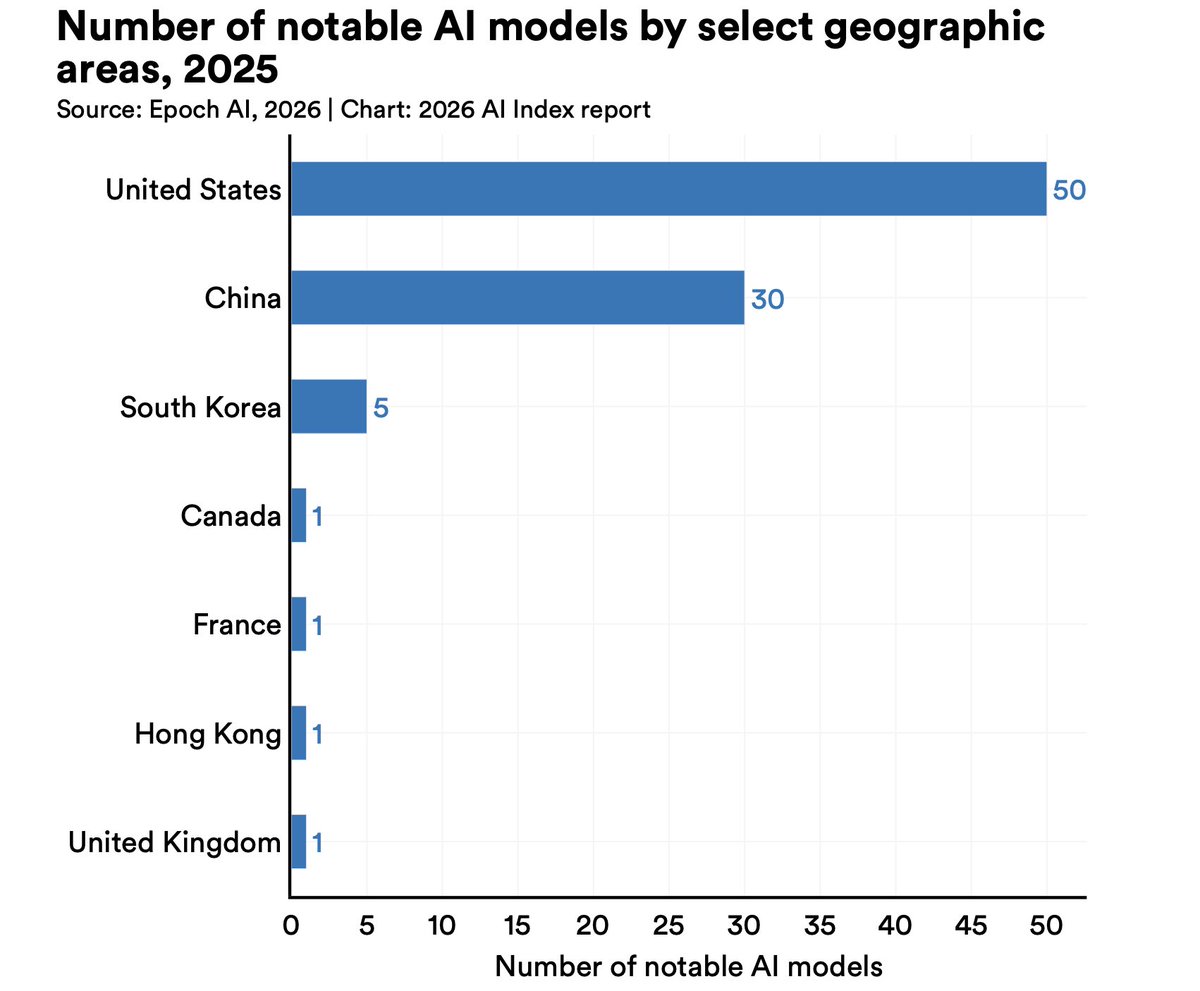
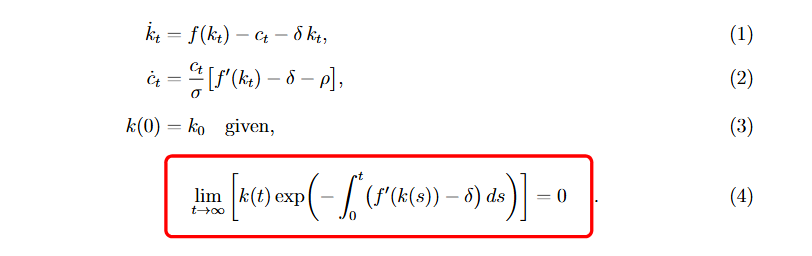ทวีตที่ปักหมุด

📣 What if central bank statements do not just describe global financial conditions — but help shape them?
I am pleased to share our paper, “The Monetary Policy Statement Database: An LLM Application to Global Financial Conditions” now published in @bis_org IFC Bulletin
🧵 1/7

English