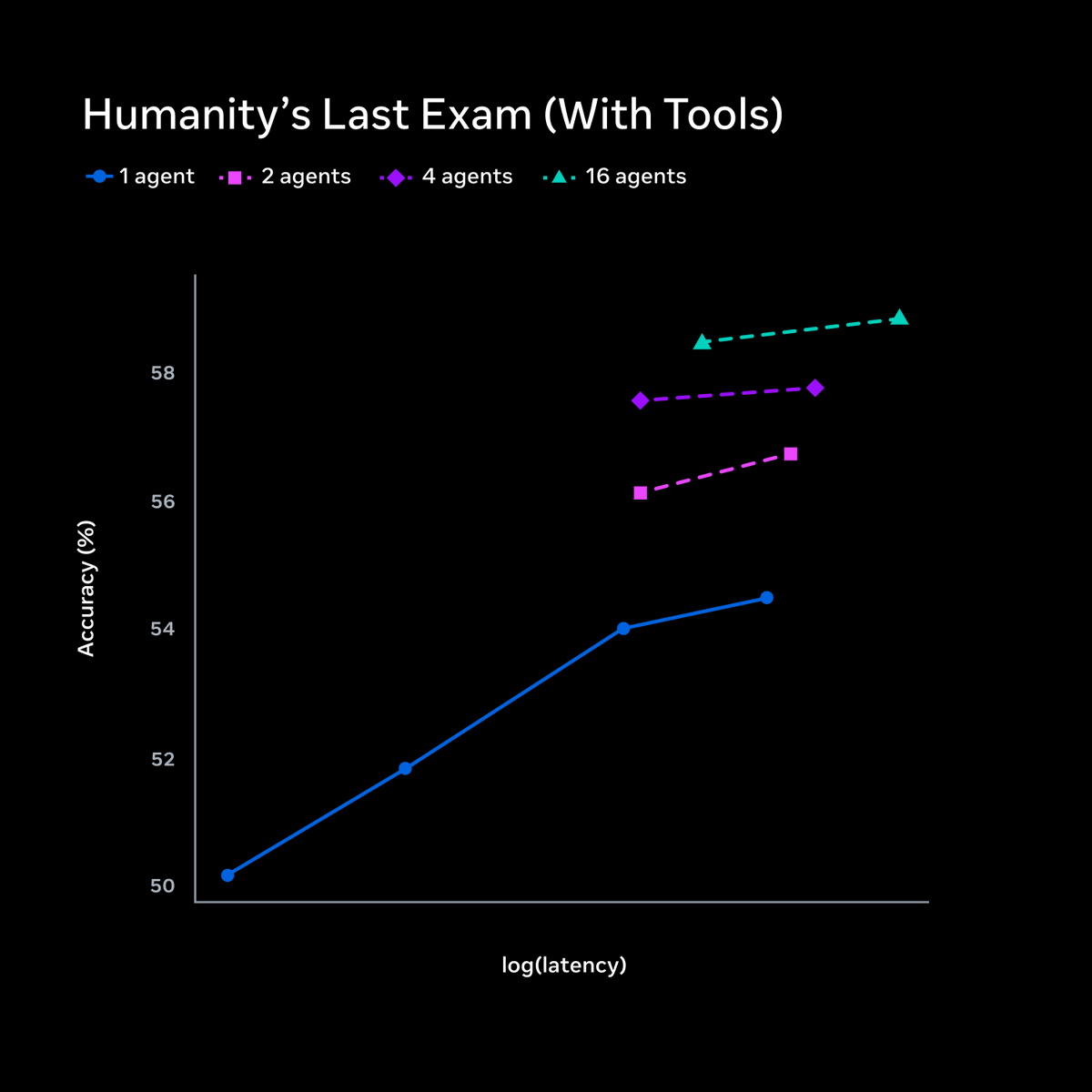
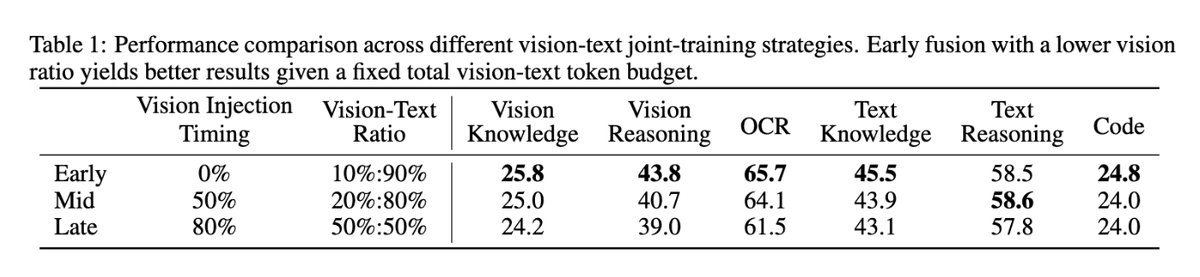
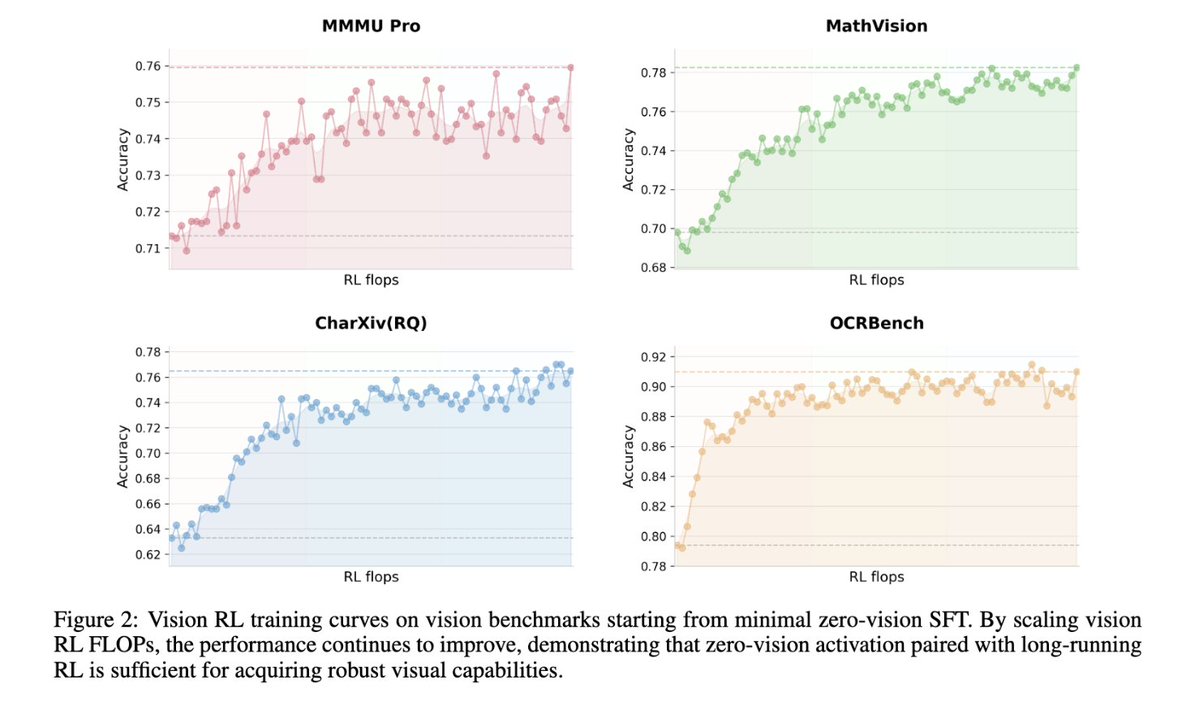
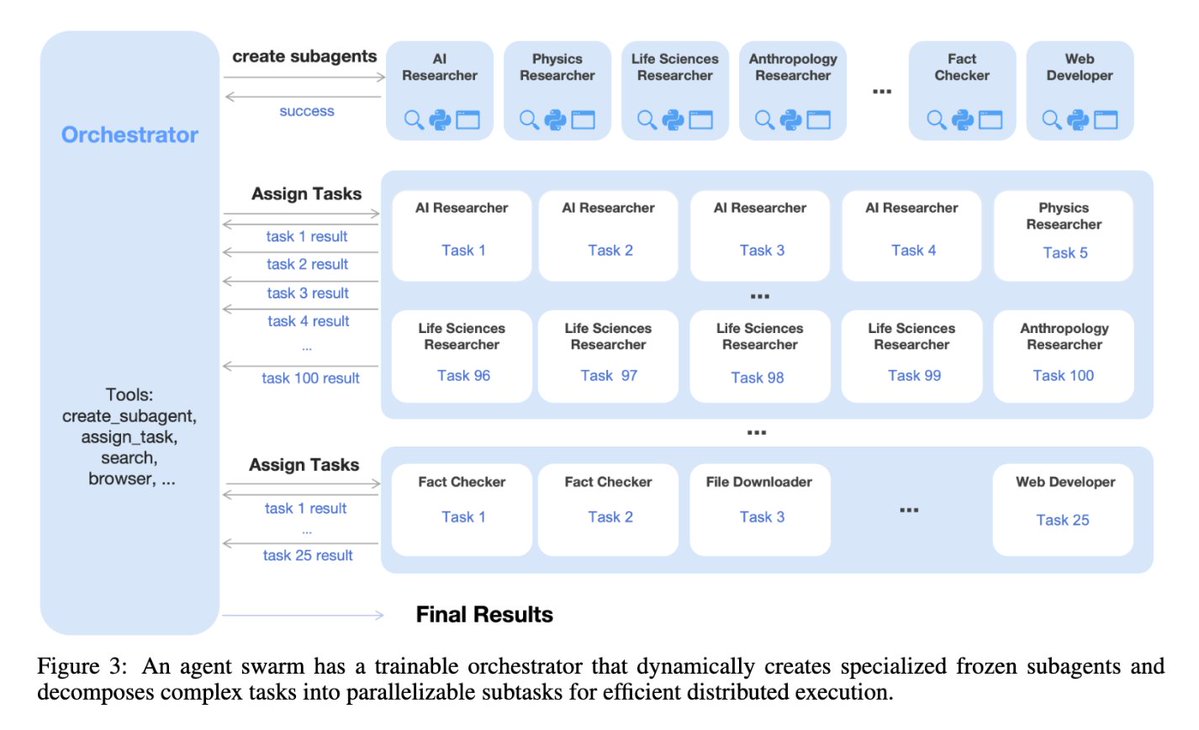
ทวีตที่ปักหมุด

Been deep in the agent tool-use side of Muse Spark 🥑 for a while now. Great to see our work translating into the first milestone. Lots more to come.


Alexandr Wang@alexandr_wang
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
English