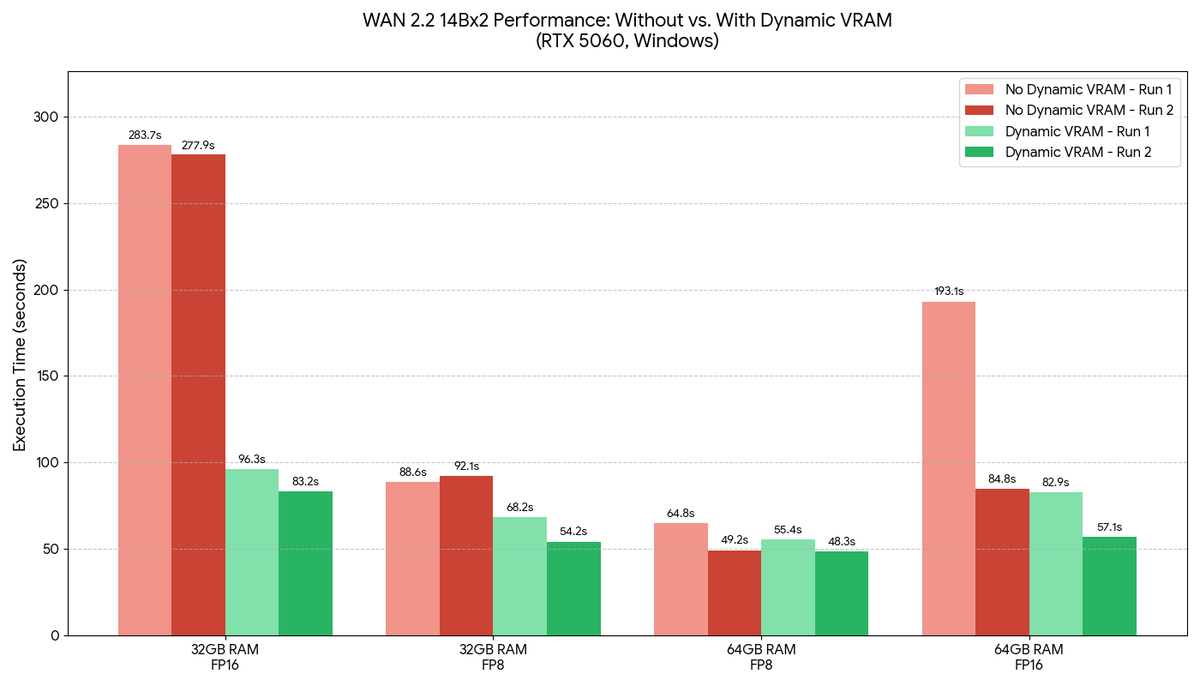
@TheAhmadOsman Continuous training. Collects data and trains the small base model. Continuous fine-tuning beyond that
English
legendarylibrary
16.3K posts

@LegendaryLibr
crypto/ ai Art/ music





The FWC is aware of a video depicting individuals in the Everglades on an airboat who appear to be discharging firearms at an alligator. FWC officers are looking into the incident and will provide additional information when available. To report wildlife violations, call the Wildlife Alert Hotline at 888-404-3922.




When @karpathy built MenuGen (karpathy.bearblog.dev/vibe-coding-me…), he said: "Vibe coding menugen was exhilarating and fun escapade as a local demo, but a bit of a painful slog as a deployed, real app. Building a modern app is a bit like assembling IKEA future. There are all these services, docs, API keys, configurations, dev/prod deployments, team and security features, rate limits, pricing tiers." We've all run into this issue when building with agents: you have to scurry off to establish accounts, clicking things in the browser as though it's the antediluvian days of 2023, in order to unblock its superintelligent progress. So we decided to build Stripe Projects to help agents instantly provision services from the CLI. For example, simply run: $ stripe projects add posthog/analytics And it'll create a PostHog account, get an API key, and (as needed) set up billing. Projects is launching today as a developer preview. You can register for access (we'll make it available to everyone soon) at projects.dev. We're also rolling out support for many new providers over the coming weeks. (Get in touch if you'd like to make your service available.) projects.dev