ทวีตที่ปักหมุด

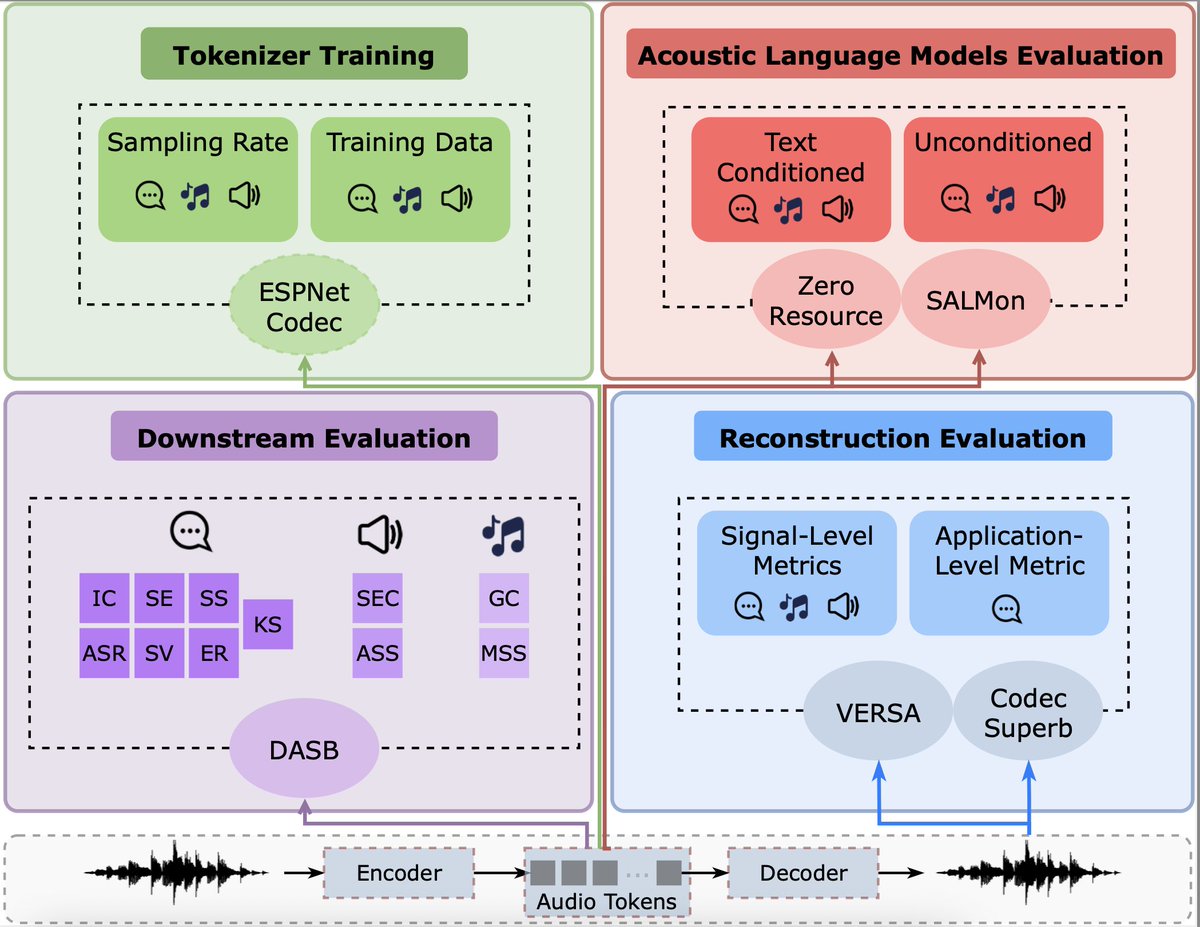
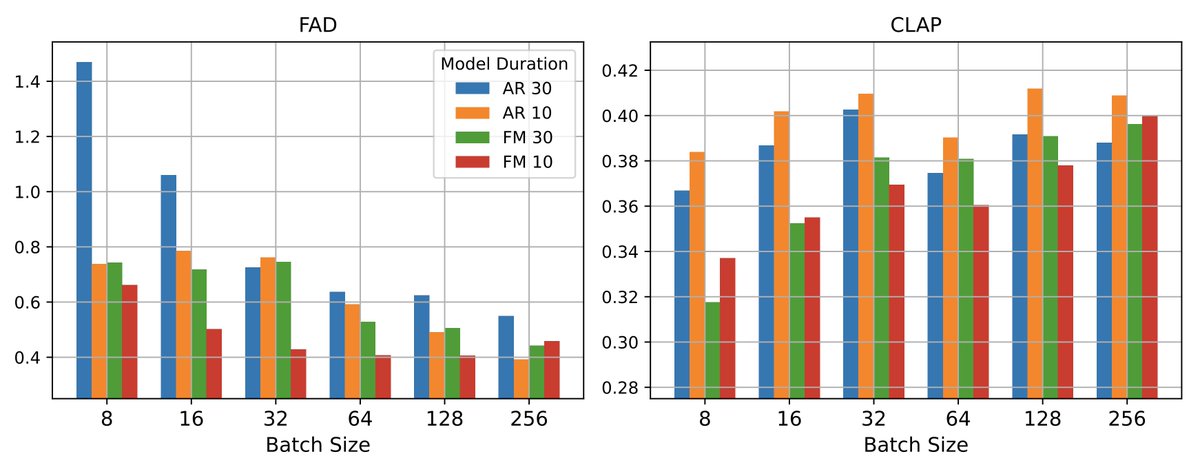
Which modeling to choose for text-to-music generation?
We run a head-to-head comparison to figure it out.
Same data, same architecture - AR vs FM.
👇 If you care about fidelity, speed, control, or editing see this thread.
🔗huggingface.co/spaces/ortal16…
📄arxiv.org/abs/2506.08570
1/6

English