Qinyue Zheng รีทวีตแล้ว
Qinyue Zheng
23 posts


Qinyue Zheng
@QueyJ
I build. AI PhD Student @ETH Zürich | Prev @EPFL, @Harvard, @llama_index
เข้าร่วม Haziran 2017
258 กำลังติดตาม61 ผู้ติดตาม

Qinyue Zheng รีทวีตแล้ว

Wanna do a postdoc in my group?
Check out this position on "Language Models for Pediatric Data Analysis" in collaboration with the University Children's Hospital Basel:
jobs.ethz.ch/job/view/JOPG_…
English
Qinyue Zheng รีทวีตแล้ว

Sharing our latest work: Reinforcement Learning via Self-Distillation
We introduce Self-Distillation Policy Optimization (SDPO), an on-policy RL algorithm that turns feedback into dense, token-level learning signals.

English
Qinyue Zheng รีทวีตแล้ว

SDPO enables RL agents to learn from rich feedback (i.e., not only whether an attempt failed, but why it failed, such as error messages). Even without such rich feedback, SDPO can reflect on past attempts and outperform GRPO. SDPO accelerates solution discovery at test time!
Jonas Hübotter@jonashubotter
Training LLMs with verifiable rewards uses 1bit signal per generated response. This hides why the model failed. Today, we introduce a simple algorithm that enables the model to learn from any rich feedback! And then turns it into dense supervision. (1/n)
English
Qinyue Zheng รีทวีตแล้ว

A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
English

I started med school not having much vocabulary beyond "patient looks good" or not, then spent the next 4 years building up that vocabulary...
and now as a resident, learning how valuable a simple "looks good" or not is -- and how much that by itself completely swings treatment decisions.
this premise is, incidentally, related to one of the big reasons I don't think LLMs will replace clinicians
English
Qinyue Zheng รีทวีตแล้ว

Meta-RL Induces Exploration in Language Agents
Exploration is essential for LLM agents, but how can we train an agent that actively explores?
Introducing 🌊LaMer, a general Meta-RL framework that enables LLM agents to explore and learn from the environment feedback at test time.
Key idea:
(i) Cross-episode training to encourage exploration and long-term reward optimization
(ii) In-context policy adaptation via self-reflection, allowing agents to update behavior from feedback without gradient updates
LaMer trains the agents to explore in the early episodes and adapt to the environment in the subsequent episodes, leading to:
(i) More diverse trajectories of trained agents compared to RL baselines
(ii) Stronger performance and test-time scaling
(iii) Better generalization to hard or out-of-distribution tasks
📜Paper: arxiv.org/abs/2512.16848
💻Code: github.com/mlbio-epfl/LaM…
Had fun collaborating with @LiangzeJ and his advisor @DamienTeney, and huge thanks to my amazing advisors @mariabrbic and @Michael_D_Moor
English
Qinyue Zheng รีทวีตแล้ว
🚀 New PhD position in my group:
jobs.ethz.ch/job/view/JOPG_…
We’re hiring a doctoral student at ETH Zurich (located in D-BSSE, Basel) to work on medical reasoning.
🌍 Fully funded PhD as part of the EU-funded Marie-Curie project "MLCARE".
Our group has access to high-end GPU clusters, we are embedded in the life science hub of Switzerland in Basel, are involved with the ETH AI Center and SwissAI projects. For more details on the position, check out the link.
📩 Pease share!
English

You rarely solve hard problems in a flash of insight. It's more typically a slow, careful process of exploring a branching tree of possibilities. You must pause, backtrack, and weigh every alternative.
You can't fully do this in your head, because your working memory is too limited. Writing is the external medium that affords the time and precision necessary.
Serious thinking must be done in writing. And that's why you can't outsource your writing, because then you're outsourcing your thinking.
English
Qinyue Zheng รีทวีตแล้ว
Med friends -- I'm releasing 🔵 Pearls, an app I built for capturing clinical pearls while on rounds or studying.
Once you add a pearl, an AI agent will automatically fetch additional context, latest guidelines, and augment the pearl.
Other features: free sync between devices, auto-tagging, study mode.
More broadly, I'm exploring some ideas on how LLMs can improve the ability of residents to absorb and retain higher amounts of information; this is one small practical exploration of those ideas.



English
Qinyue Zheng รีทวีตแล้ว

🚀 Excited to share our latest work at ICML 2025 — zip2zip: Inference-Time Adaptive Vocabularies for Language Models via Token Compression!
Sessions:
📅 Fri 18 Jul
- Tokenization Workshop
📅 Sat 19 Jul
- Workshop on Efficient Systems for Foundation Models (Oral 5/145)
GIF



English
Thanks @qdrant_engine for featuring MIRIAD! 🫶
Always a great team effort with @salmanabdullah_
🚀 5.8M+ medical QA pairs to support grounding LLMs in reliable medical knowledge! Check it out it’s fun!
📂Dataset: huggingface.co/miriad
🪐Demo: med-miriad.github.io/demo/
Qdrant@qdrant_engine
Researchers at @ETH_en and @Stanford released an open dataset of 5.8M+ long-form medical QA pairs, each grounded in peer-reviewed literature and designed for RAG. 🚀 The pipeline: ▪️ Source: 900K+ full-text medical papers (S2ORC) ▪️ QA generation via GPT-3.5 with a three-stage filtering process (regex, Mistral-7B classifier, human-in-the-loop) ▪️ Embeddings generated and indexed in Qdrant for scalable dense retrieval The dataset is available on @huggingface🤗 with full code for embedding, indexing, and RAG setup. 👉 Full story: qdrant.tech/blog/miriad-qd…
English
Qinyue Zheng รีทวีตแล้ว

Big news: we've figured out how to make a *universal* reward function that lets you apply RL to any agent with:
- no labeled data
- no hand-crafted reward functions
- no human feedback!
A 🧵 on RULER
English
Excited to launch the public beta of Osler - a workspace + copilot for physicians writing H&P notes that is designed to augment thinking, not replace it.
As a resident physician, I built Osler around two core beliefs:
1) the act of writing notes helps doctors think and plan
2) great notes should enable clear, concise communication
Osler fits into your current workflow seamlessly and is designed to keep physicians in control, while helping boost their clinical reasoning and efficiency.
- Focus on jotting your clinical ideas and have them formalized into a note, without changing your clinical details
- Check whether your plan adheres to the latest clinical guidelines
- Propose additional differential diagnoses, other labs to consider, etc
- Easy export to your favorite EMR
Osler is available for free -- and I would love any suggestions to make it better!
English
Qinyue Zheng รีทวีตแล้ว
🚨Preprint alert!🚨 Did you know there is a new reasoning benchmark where leading models like o3 still fall flat?
(i.e. 0% accuracy or random perf. on hard sub-tasks)
✨Meet 𝐌𝐀𝐑𝐁𝐋𝐄, a 🪨-hard benchmark for multimodal reasoning and planning under complex spatial constraints!✨
Inspired by well-known challenges such as the ARC challenge, we thought:
𝘊𝘢𝘯 𝘸𝘦 𝘥𝘦𝘷𝘪𝘴𝘦 𝘢 𝘯𝘦𝘸 𝘤𝘩𝘢𝘭𝘭𝘦𝘯𝘨𝘪𝘯𝘨 𝘣𝘦𝘯𝘤𝘩𝘮𝘢𝘳𝘬 𝘧𝘰𝘳 𝘔𝘓𝘓𝘔𝘴 𝘵𝘰 𝘱𝘶𝘵 𝘵𝘩𝘦𝘪𝘳 𝘢𝘣𝘪𝘭𝘪𝘵𝘺 𝘵𝘰 𝘳𝘦𝘢𝘴𝘰𝘯 𝘢𝘯𝘥 𝘮𝘶𝘭𝘵𝘪-𝘴𝘵𝘦𝘱 𝘱𝘭𝘢𝘯𝘯𝘪𝘯𝘨 𝘵𝘩𝘳𝘰𝘶𝘨𝘩 𝘤𝘰𝘮𝘱𝘭𝘦𝘹 𝘮𝘶𝘭𝘵𝘪𝘮𝘰𝘥𝘢𝘭 𝘱𝘳𝘰𝘣𝘭𝘦𝘮𝘴 𝘵𝘰 𝘵𝘩𝘦 𝘵𝘦𝘴𝘵?
Turns out this is still super hard even for latest models!
MARBLE offers 2000+ multimodal-reasoning problems split into two domains:
𝐌-𝐏𝐨𝐫𝐭𝐚𝐥: multi-step spatial-planning puzzles modelled on levels from Portal 2.
𝐌-𝐂𝐮𝐛𝐞 : here, models need to plan 3D cube assemblies from jigsaw pieces, inspired by Happy Cube puzzles.
MARBLE provides a tough benchmark for testing advanced reasoning in MLLMs. For these tasks, the genie is out of the bottle now—expect to see rapid improvements in model performance over the coming months, so let's not over-interpret them by that time!
🌐 Website: marble-benchmark.github.io
📄 Paper: huggingface.co/papers/2506.22…
💻 Code: github.com/eth-medical-ai…
🤗 Dataset: huggingface.co/datasets/mrble…
Fun collab with @YulunJiang @ychai1224 @mariabrbic!
English
Qinyue Zheng รีทวีตแล้ว

Qinyue Zheng รีทวีตแล้ว
🚨New preprint! 🚨In-context learning (ICL) is the intriguing ability of LLMs to learn to solve tasks purely from context w/o parameter updates.
For multimodal LLMs (MLLMs), ICL is poorly understood, especially in the medical domain where doctors would often face few relevant prior cases, prior imaging studies etc. But can MLLMs actually learn from context in the medical domain? 🤔
To answer this question, we introduce SMMILE— an expert-curated benchmark for multimodal ICL in the medical domain!
TL;DR:
💡MLLMs perform surprisingly poorly at multimodal ICL in the medical domain! --> ICL performance sometimes actually drops—some models perform worse than random baselines. Models have still a way to go here!
Previously, many ICL evaluations leveraged random, potentially irrelevant examples -> with the help of clinical experts, here we carefully craft explicit task demonstrations to more robustly probe the ICL ability.
📊 The benchmark:
-> 111 expert-curated problems (517 ICL problems)
-> 6 medical specialties, 13 imaging modalities
-> SMMILE++ variant with 1,038 permuted problems
-> Comprehensive evaluation of 15 state-of-the-art MLLMs
Check it out:
🔗 Page: smmile-benchmark.github.io
📜 Paper: arxiv.org/abs/2506.21355
💻 Code: github.com/eth-medical-ai…
📁 Dataset: huggingface.co/smmile
Great collab with stellar colleagues @mrieff_02* @mayavarma23* (co-first) @IAMJBDEL# (co-last) and more!
English
Qinyue Zheng รีทวีตแล้ว

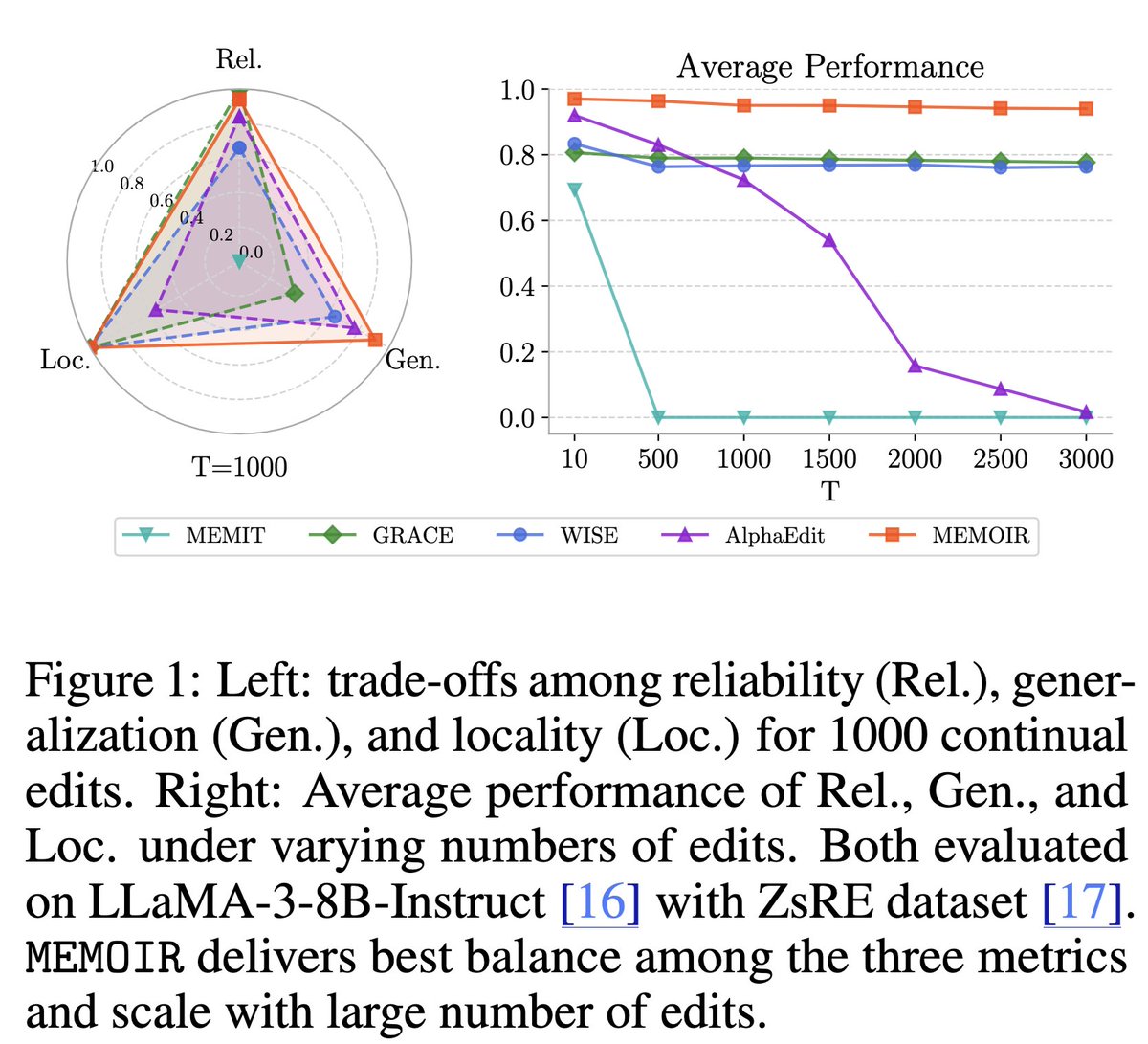
How can we inject new knowledge into LLMs without full retraining, forgetting, or breaking past edits?
We introduce MEMOIR 📖— a scalable framework for lifelong model editing that reliably rewrites thousands of facts sequentially using a residual memory module. 🔥
🧵1/7
English
Qinyue Zheng รีทวีตแล้ว
# on technical accessibility
One interesting observation I think back to often:
- when I first published the micrograd repo, it got some traction on GitHub but then somewhat stagnated and it didn't seem that people cared much.
- then I made the video building it from scratch, and the repo immediately went through hockey stick growth and became a verty often cited reference for people learning backpropagation.
This was interesting because the micrograd code itself didn't change at all and it was up on GitHub for many months before, stagnating. The code made sense to me (because I wrote it), it was only ~200 lines of code, it was extensively commented in the .py files and in the Readme, so I thought surely it was clear and/or self-explanatory. I was very happy with myself about how minimal the code was for explaining backprop - it strips away a ton of complexity and just gets to the very heart of an autograd engine on one page of code. But others didn't seem to think so, so I just kind of brushed it off and moved on.
Except it turned out that what stood in its way was "just" a matter of accessibility. When I made the video that built it and walked through it, it suddenly almost 100X'd the overall interest and engagement with that exact same piece of code. Not only from beginners in the field who needed the full intro and explanation, but even from more technical/expert friends, who I think could have understood it if they looked at it long enough, but were deterred by a barrier to entry.
I think as technical people we have a strong bias to put up code or papers or the final thing and feel like things are mostly self-explanatory. It's there, and also it's commented, there is a Readme, so all is well, and if people don't engage then it's just because the thing is not good enough. But the reality is that there is still a large barrier to engage with your thing (even for other experts who might not feel like spending time/effort!), and you might be leaving somewhere 10-100X of the potential of that exact same piece of work on the table just because you haven't made it sufficiently accessible.
TLDR: Step 1 build the thing. Step 2 build the ramp. 📈
Some voice in your head will tell you that this is not necessary, but it is wrong.
English