
Satoki Ishikawa
661 posts

Satoki Ishikawa
@SisForCollege
TokyoTech 25D Dept. of Computer Science | R.Yokota lab | DNN https://t.co/BEJmlAWZD8: https://t.co/3NoUYlliTa
เข้าร่วม Ağustos 2018
1.1K กำลังติดตาม530 ผู้ติดตาม

I have successfully completed my PhD today! Grateful for all the support along the way.

English
Satoki Ishikawa รีทวีตแล้ว

Our paper "Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks" has been accepted to ICLR 2026! 🎉
See you in Brazil! 🇧🇷

English
Satoki Ishikawa รีทวีตแล้ว

Bach is so timeless because he wasn't writing for people, he was writing for a higher power. Try writing your next paper for God. Imagine how many rubbish papers we wouldn't see anymore. Your audience sees your every thought and intention. There would be no ego, no pretense.
English
I can accept that the max LR transfers well with μP. However, the optimal LR seems far more complex. It's influenced by many other factors, such as finding a rate that avoids "forgetting" or instability. Of course, alignment between vectors would be also important...
English
One thing I've been wondering about HP transfer in μP is what criterion they're using to define "transfer." For instance, TP4 seems to state that the max LR (the maximum LR that doesn't diverge) transfers. But then, TP5 claims that the optimal LR transfers. Which is correct?


Jason Lee@jasondeanlee
Proof by picture of why lr convergence is not useful unless it is fast relative to loss/predictions. Credit to nikhil Ghosh, Denny Wu, and Alberto for studying this and critical of the muP series of conclusions and overclaims.
English
@myai100 Thank you for pointing this out! The AdaGrad paper is a very important paper!!
English

@SisForCollege jmlr.org/papers/volume1… Perhaps Adagrad itself could be added because many methods (Shampoo, KFAC) approximate the full-matrix version
English
I'm updating awesome-second-order optimization. If you find important / interesting papers not cited in this repository, please let me know.
github.com/riverstone496/…
English
@tmoellenhoff Thank you for pointing that out! I completely forgot that important paper. I’ve updated the list
English

@SisForCollege Shameless plug of my own works :)
arxiv.org/abs/1706.04638 (equivalent to LocoProp-S, but from 2018)
arxiv.org/abs/2402.17641 (could be added to Bayesian section)
English
Satoki Ishikawa รีทวีตแล้ว





ACT-X「次世代AIを築く数理・情報 科学の革新」に採択されました.引き続き,ニューラルネットワークの最適化について,深い理解を得られるよう研究していきます😁
日本語
@cloneofsimo You’re in Tokyo! Nice! If you’re interested and have a moment, feel free to drop by our lab. No art here, sadly, so it might not be that exciting😭
English


Satoki Ishikawa รีทวีตแล้ว
I won’t make it to ICML this year, but our work will be presented at the 2nd AI for Math Workshop @ ICML 2025 (@ai4mathworkshop).
Huge thanks to my co‑author @SisForCollege for presenting on my behalf. please drop by if you’re around!

English
Satoki Ishikawa รีทวีตแล้ว

considering Muon is so popular and validated at scale, we've just decided to welcome a PR for it in PyTorch core by default.
If anyone wants to take a crack at it...
#issuecomment-3070108227" target="_blank" rel="nofollow noopener">github.com/pytorch/pytorc…
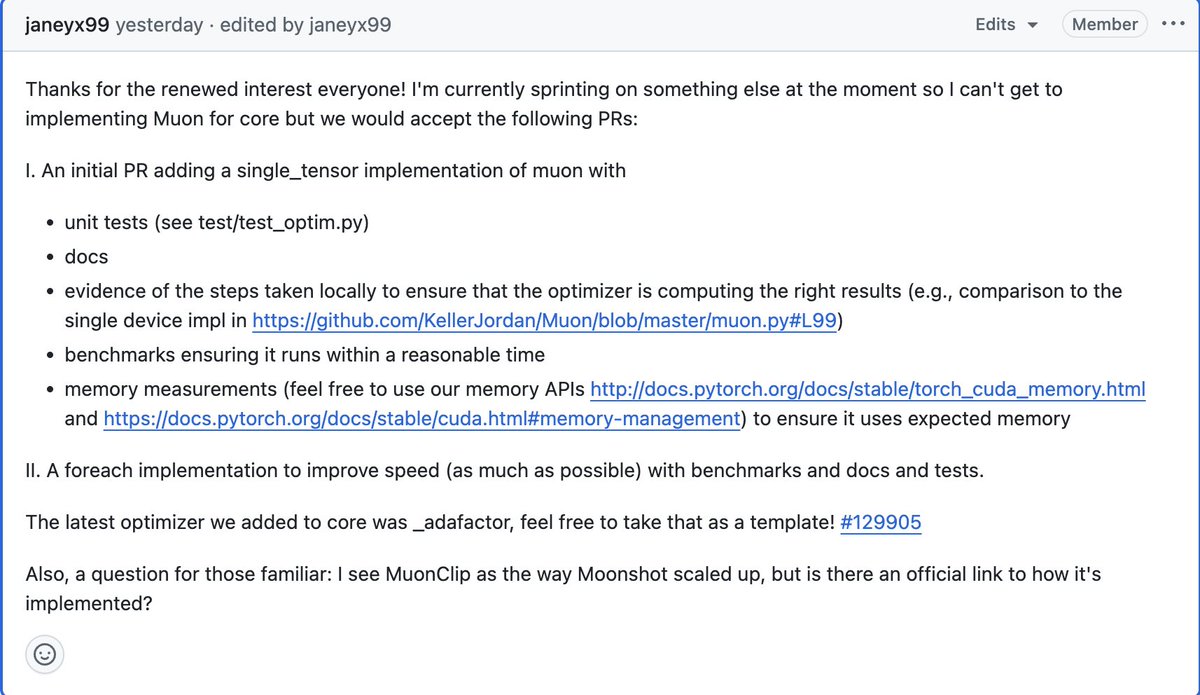
English
@borisdayma @JesseFarebro @_arohan_ 2505.02222 doesn’t seem to include any theoretical derivations, so it’s hard to know whether it really implements muP. At the very least, Bernstein’s learning‐rate scaling uses the same parameterization as our muP, and since both are derived mathematically, they should be muP.
English

@SisForCollege @JesseFarebro @_arohan_ Thanks for referencing Bernstein, will check better.
I had looked at "Practical Efficiency of Muon for Pretraining" and it seemed that they applied equivalent rules as the original ones for Adam: arxiv.org/abs/2505.02222

English
MUP has been on my mind forever!
Now I came across this gem from @JesseFarebro : github.com/JesseFarebro/f…
It automatically handles it on JAX/Flax 😍
Just need to see what to adjust for Muon / Shampoo / PSGD-kron (init params + LR scaling)
English
@borisdayma @JesseFarebro @_arohan_ I agree that Muon = Shampoo and I think Muon needs the same kind of scaling as Shampoo.
(I believe my muP scaling is the same as the scaling of Muon by Bernstein
English
@SisForCollege @JesseFarebro Oh interesting so you do have coeffs for Shampoo… I thought that there was no need since I understood they are not needed for Muon and @_arohan_ keeps on saying that Muon = Shampoo
English
@evaninwords In my view, grokking occurs when certain conditions involving init scale, weight decay, and learning rate are met. In other words, grokking usually happens due to insufficient hyperparameter tuning. Therefore, it would be important to plot how large the grokking area is.

English

@SisForCollege I wonder if various weight constraints would affect grokking then?
English
Toy grokking problems can be pretty sensitive, but turns out PSGD is robust! 💪
For modular arithmetic, PSGD does better than AdamW across the board for batch size, model depth, dim, and num heads. These two plots are best runs for each.
Sweeps below 👇


Essential AI@essential_ai
[1/5] We have a quick update to share, which contradicts our hypothesis regarding the abilities of Muon and Adam vis-a-vis Grokking.
English
QME
@evaninwords I think grokking happens when the weight scale is too large for the task and the optimizer. The optimal weight scale depends on the optimizer, so I’d love to see the results of sweeping weight scale or weight decay. (And, I believe PSGD outperforms on that.)
English
I find a very interesting μP paper on the embedding LR. They propose new embedding LR scale when vocab size is much larger than width.
arxiv.org/abs/2506.15025
English