NON-MIGRATED TOKENS
TO SUPPORT ECOSYSTEM EXPANSION
Following the migration to ACN on Ethereum, a portion of the original $AITECH supply was not migrated within the allocated migration period.
As part of the transition into the ACN ecosystem, these non-migrated tokens will be strategically allocated toward expanding spot and futures market accessibility, provisioning liquidity across exchanges, supporting community participation, and advancing broader ecosystem growth initiatives. The full allocation distribution across initiatives is mentioned below
• Spot & Futures Markets Expansion
• Liquidity Provision
• Boost Token Burns
• Boost Community Incentives
• Staking Rewards
• Ecosystem Sustainability
• Future Ecosystem Development
The allocation of these tokens is designed to support a stronger, more active ecosystem while maintaining full transparency around token usage and distribution.
The first community initiative supported through this allocation will be launched today. Stay tuned.
The AI Boom Is Also A Compute Boom!
Most people focus on AI models.
Far fewer focus on the infrastructure required to run them.
Behind every AI application sits massive compute demand:
GPU clusters, networking, power systems, cooling and inference infrastructure.
As AI scales globally, compute is becoming one of the most strategically important layers in technology.
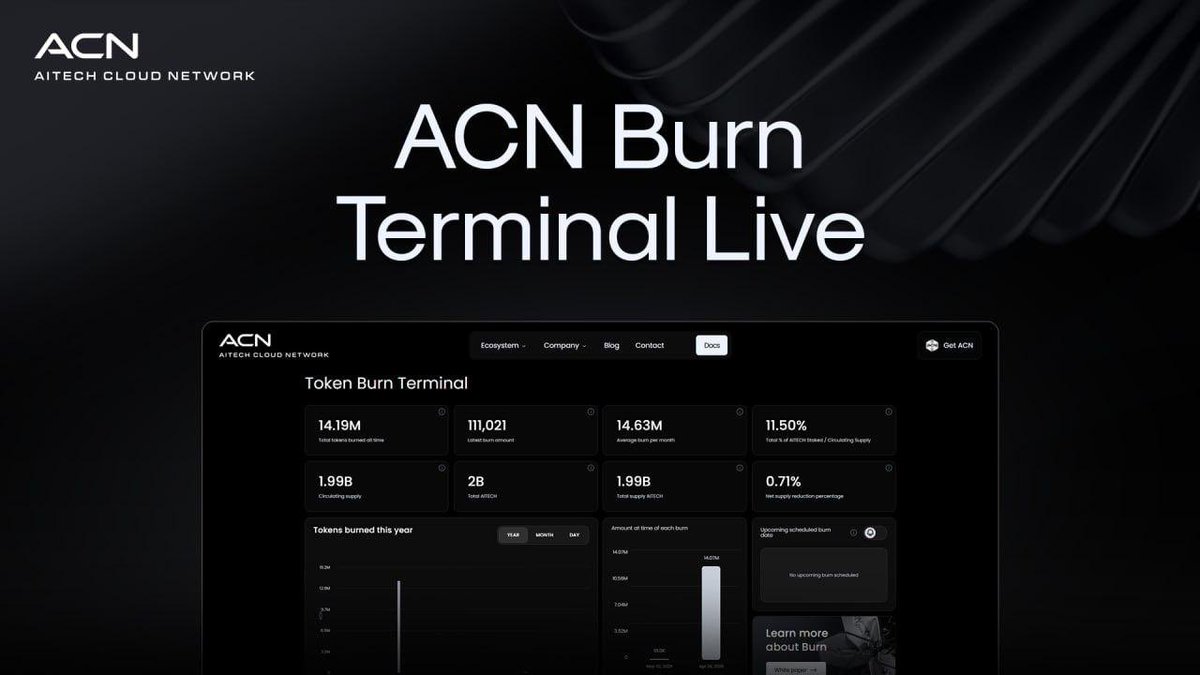
The ACN Burn Terminal is Live!
Track all ACN burns in real-time through the burn terminal, including total tokens burned, cumulative burn activity, total staked supply, and key ecosystem metrics across the network.
The burn terminal gives the community full transparency across ecosystem burn activity in one place.
🔗 aitech.io/burn
Memory Bandwidth Impacts AI Performance!
Most people compare GPUs based on FLOPS.
But for large-scale AI inference, memory bandwidth is often the bigger performance factor.
Modern AI models constantly move massive amounts of data between memory and compute cores. If data cannot move fast enough, compute power gets bottlenecked.
That is why GPUs with higher memory bandwidth can deliver lower latency, faster inference, and better performance under heavy workloads.
The conversation around AI hardware focuses heavily on raw compute. In practice, data movement is just as important. When evaluating AI infrastructure, bandwidth matters more than most people realize.
Weekly Development Update!
Development continues across the Compute Marketplace and Agent Forge, with ongoing progress focused on infrastructure planning, expanded integrations, and workflow refinement across the platform.
Compute Marketplace
• Planning and preparation for CDC implementation currently underway, with development expected to begin this week
Agent Forge
• Comprehensive local testing completed for PostgreSQL, Helius, and Alchemy integration blocks, validating API functionality, error handling, and documentation accuracy
• Multiple Memory block issues resolved, improving default configurations and execution flow behavior
• New OKX Trading block added, supporting a wide range of trading and account operations including balances, positions, order management, recurring buys, and announcements
• Shared credential label resolver upgraded to display readable profile names across supported OAuth providers instead of internal identifiers
• Added provider-specific label handling for integrations including Zoom, LinkedIn, Trello, Dropbox, HubSpot, WordPress, X, Confluence, Jira, Discord, Airtable, Notion, and Linear
• Full Trello block integration implemented across tools, blocks, OAuth authentication, webhooks, and documentation, including support for boards, cards, lists, comments, and search functionality
• Zoom block integration completed end-to-end with OAuth support, meeting and recording tools, webhook validation, workflow integration, and full documentation coverage
• Full Stripe block integration implemented across the platform, supporting customers, products, subscriptions, invoices, refunds, disputes, payment intents, checkout sessions, and balance tracking
• Service endpoints added to the Global ERC-8004 Registry, enabling easier agent endpoint discovery and direct workflow integration within Forge
• Workflow UI layout refined with dedicated header spacing for the control bar, preventing canvas overlap and improving responsive alignment across devices
AI Agents Are Moving Into Real Operational Roles!
The AI agent narrative is changing fast.
A year ago, most people associated agents with simple chat interfaces and basic automation.
Now teams are building agents that monitor markets continuously, execute trades, manage support operations, review contracts, coordinate APIs, provision infrastructure, process internal company workflows, and interact directly with blockchain networks in real time.
The shift happening now is that software is starting to behave less like a tool waiting for input and more like an active system capable of handling ongoing operational tasks independently.
As these systems become more autonomous, the demand for compute, orchestration layers, memory systems, payments, and reliable execution infrastructure increases alongside them.
We will be hosting an exclusive Agent Forge 2.0 Webinar this Monday 25th May at 1PM UTC for Agent Forge Alpha Group members.
The webinar will provide an inside look into Agent Forge 2.0, covering visual AI workflow creation, multi-model orchestration, external integrations, autonomous execution systems, and some of the infrastructures.
If you are part of the Agent Forge 2.0 Alpha Group, the webinar link will be shared within the group.
H100 vs H200 - Why Memory Matters
Most teams still compare GPUs based on hourly pricing.
But as AI workloads grow, memory capacity starts becoming one of the biggest performance factors.
For smaller workloads, H100s are often enough.
But larger models, longer context windows, and more demanding inference workloads can quickly increase infrastructure requirements and reduce efficiency.
That is where H200s start making more sense.
The extra memory can reduce overhead, improve workload handling, and simplify deployment at scale.
AI infrastructure is no longer just about compute power.
Memory is becoming part of the equation.
Latency isn’t just a technical detail.
It directly affects strategy outcomes.
If your execution is delayed, your “logic” is already outdated.
@HyperliquidX gives us the speed required to make structured strategies actually behave as intended.
Not everyone will catch a trading group call, but you can be prepared for the next market move.
Compute Gives Power. Architecture Gives Direction.
A lot of AI infrastructure discussions still revolve around compute. More GPUs. Faster inference. Larger clusters.
That matters.
But once AI systems move beyond simple prompts into continuous execution, architecture starts becoming the bigger differentiator.
Because the real challenge is no longer just generating outputs.
It’s coordinating systems reliably at scale.
How agents interact with tools.
How workflows maintain continuity.
How context moves across tasks.
How execution stays stable under increasing demand.
That’s why two platforms with similar compute access can feel completely different in production. One behaves like isolated tools. The other behaves like an operating system for execution.
The next phase of AI infrastructure likely won’t be defined by compute alone. It’ll be defined by how well the architecture behind it is designed to sustain autonomous execution over time.
Smart Monkey Sunday 🕵️♂️🐒
George spent the weekend reading Sherlock Holmes and investigating a familiar DeFi mystery: where execution losses actually come from.
In many cases, it’s not the strategy itself. It’s slippage and MEV extraction quietly eating into swaps behind the scenes.
The effect often looks small trade by trade, but across repeated cross-chain activity the losses add up faster than most traders expect.
This is one of the problems Reactor’s MetaDEX engine is designed to reduce.
The routing system scans 300+ liquidity sources to search for more efficient execution paths before the swap is executed.
Most traders spend time analyzing entries. Fewer spend time investigating execution quality.
👉 Explore Reactor: app.reactor.trade/swap
ERC 8004 Standard Gives AI Agents a Persistent Identity!
Most AI agents don't own anything. Their wallets, transaction history, and access credentials belong to whoever deployed them. Shut down the platform, everything goes with it.
An agent built on ERC 8004 standard has its own wallet address, one it controls, not the platform. That means it can hold funds, sign transactions, and accumulate on-chain history that survives across applications and deployments.
That's not a small thing. Right now most agents are disposable. An on-chain identity makes an agent's history verifiable and its funds non-custodial, which starts to matter once agents are handling real money and real decisions.
Agents Need Smaller Loops!
Many AI agents are built to handle everything in one loop.
Reasoning, research, decisions, and execution all combined.
This works in demos.
But at scale, it becomes slow, expensive, and hard to control.
The systems that perform best break tasks into smaller loops with clear responsibilities. This keeps workflows faster, more predictable, and easier to manage.
Simplicity in structure improves performance.
And efficient systems are the ones that scale.
Grid trading works best when the market does nothing.
That’s the part most people miss.
Closed beta vaults are capturing small movements repeatedly - not waiting for big moves.
@Hyperliquid execution layer makes those small actions efficient enough to matter.