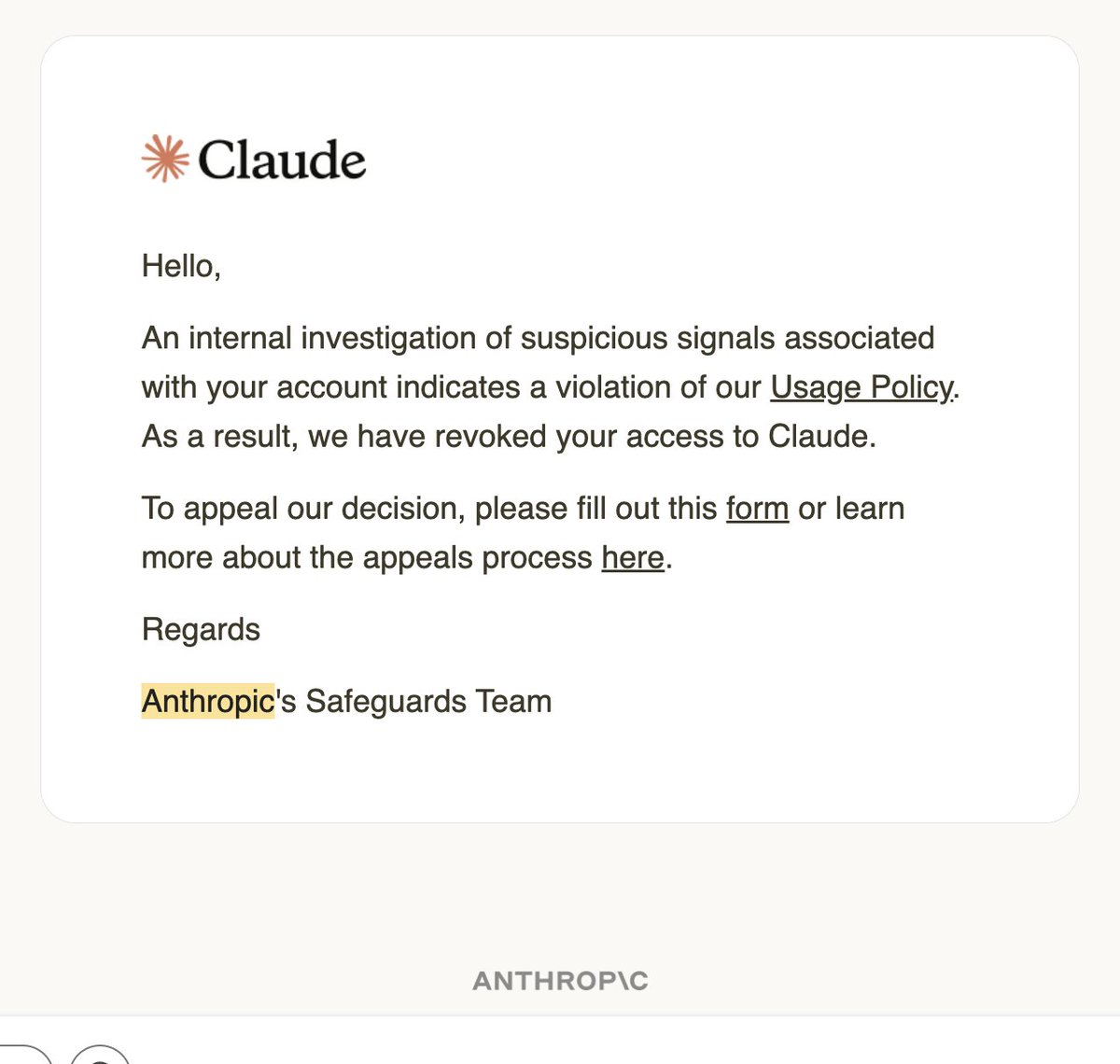
@AnthropicAI @bcherny To be clear - I love the product you've built, and IMO you guys won a lot of goodwill with your dev focus and Dario's stance on DoW. But being locked out of your primary productivity tool out of the blue feels bad
English
Rahul Gupta-Iwasaki
378 posts

@Thrice_Chilled
Co-founder & advisor @everydotorg. Especially excited by small nonprofits doing big things for underprivileged people and our planet.





$30M in crypto donations & counting. Every.org has been empowering nonprofits to accept crypto since 2020, and we're up 251% this year compared to all of 2023! On #GivingTuesday, donate your crypto to any nonprofit in the US: every.org/donate-crypto #CryptoForGood