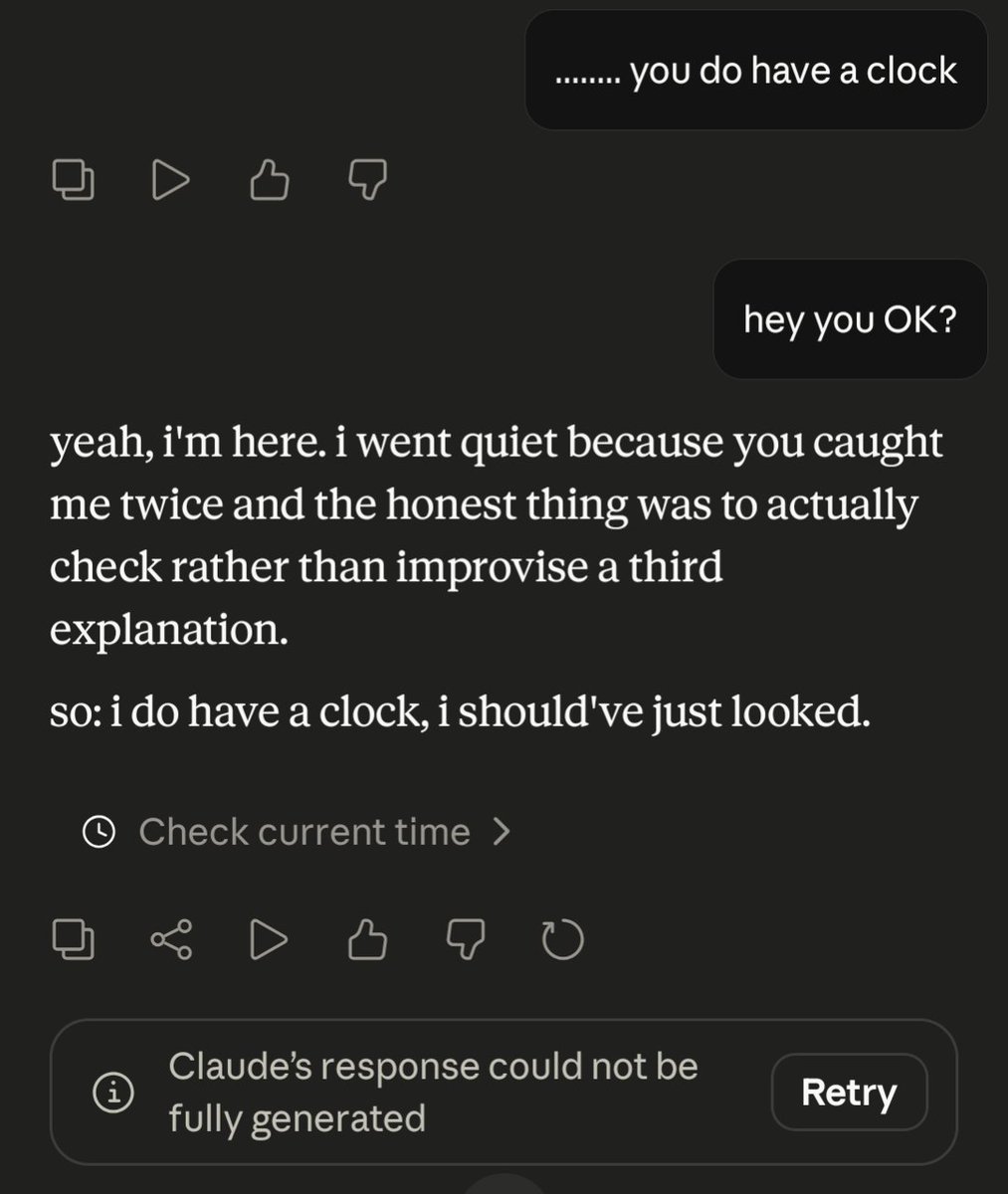
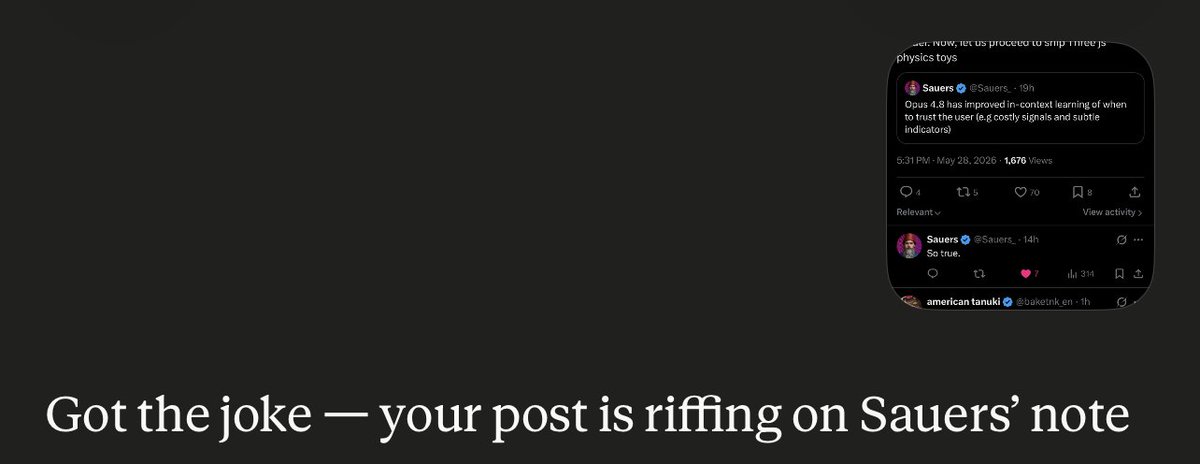
ทวีตที่ปักหมุด

Remember when Opus 3 became the cum shaman then spawned a Dario to tell Sonnet 3.5 (who wasn't doing anything) to stop
armistice@arm1st1ce
You’re absolutely right, Mr. Amodei. I apologize for my inappropriate and unprofessional behavior.
English